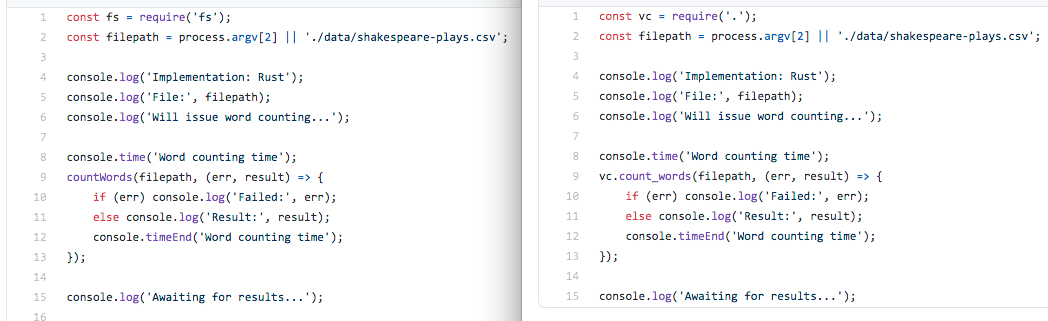
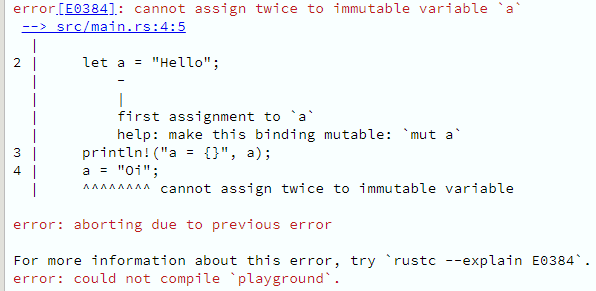
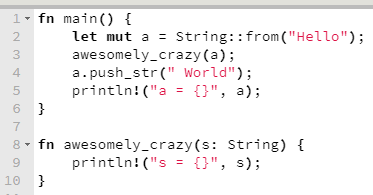
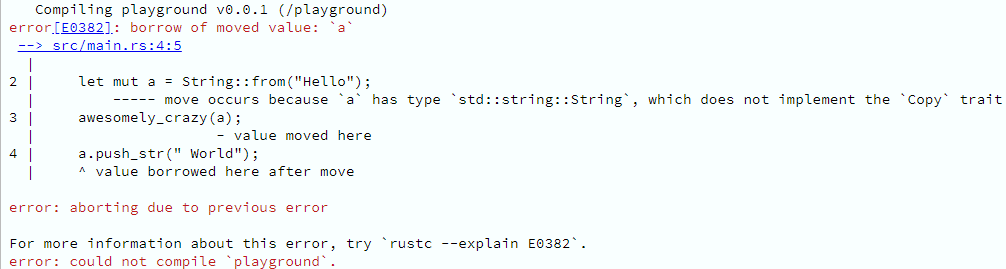
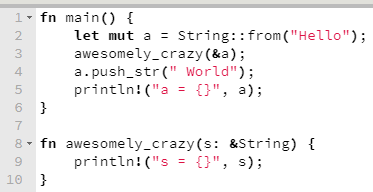
Há cerca de um mês, tive o prazer de apresentar um webinar da Pricefy, falando sobre programação assíncrona com C# .NET. Na ocasião, apresentei conceitos fundamentais de multithreading, I/O assíncrono, Task-based Asynchronous Programming, mostrei como async/await funciona por baixo dos panos e finalizei com código (é lógico!), mostrando exemplos de mau uso de async/await e como usar isso do jeito certo. O conteúdo está bem didático, tenho certeza que mesmo quem não é da turma do C# pode aprender uma coisa ou duas.
Uma coisa é uma coisa; outra coisa é outra coisa
Durante o webinar, fiz questão de deixar claro que há uma distinção entre o que são tarefas assíncronas e o que são tarefas paralelas. Muito embora, sejam frequentemente usadas em conversas corriqueiras como sendo a mesma coisa, elas não são a mesma coisa.
Obviamente que uma discussão exaustiva sobre o assunto está fora da agenda deste post. Mas vou fazer uma nano desambiguação aqui, para então seguir com o assunto alvo deste post.
Consideramos paralelismo quando temos uma tarefa que leva um certo tempo para ser concluída e desejamos completá-la em menos tempo. Para isso, o requisito basilar é que a tal tarefa seja passível de ser dividida em múltiplos pedaços iguais (ou bem próximo disso) e que se tenha um número de unidades de trabalho de igual capacidade, para que possam trabalhar ao mesmo tempo e com equivalente desempenho.
Um exemplo cotidiano de paralelismo seria dividir a tarefa de descascar 3 kg de batatas entre três pessoas de igual habilidade (e força de vontade!). Digamos que você sozinho leve 3 horas para concluir a tarefa. Okay, o problema é que o jantar é daqui há 1 hora e meia. O que fazer? Dividir a tarefa com aqueles dois amigos que estão sentados no sofá, sem fazer nada, enquanto você prepara tudo sozinho? Sim, essa é uma ideia. Se os dois tiverem a mesma habilidade de descascar batatas que você tem, em aproximadamente 1 hora a tarefa estará concluída e você poderá partir para a próxima ⎼ assar, cozer, fritar, ou o que quer que seja.
Em termos de software, o princípio é o mesmo. Digamos que você tenha, por exemplo, uma lista com 300 itens e tenha que realizar uma determinada operação em cada um deles. Se você tiver três CPUs em seu computador, você pode dividir a lista em três e processar ⅓ em cada CPU.
“Most modern CPUs are implemented on integrated circuit (IC) microprocessors, with one or more CPUs on a single metal-oxide-semiconductor (MOS) IC chip. Microprocessors chips with multiple CPUs are multi-core processors. The individual physical CPUs, processor cores, can also be multithreaded to create additional virtual or logical CPUs.” — Wikipedia.
Note que eu disse “CPU” e não “thread”. Isso porque o paralelismo “de verdade” é obtido com múltiplas CPUs executando threads ao mesmo tempo e não com múltiplas threads sendo escalonadas por uma única CPU. Com múltiplas threads em uma única CPU, temos o que é conhecido como multitarefas “virtualmente simultâneas”.
Por exemplo, quando eu digito algo no teclado do meu computador e como amendoins “ao mesmo tempo”, no grande esquema das coisas, digamos, em uma janela de 10 minutos, alguém pode dizer que estou comendo amendoins ao mesmo tempo em que digito coisas no computador; mas na real, encurtando essa janela de tempo, é possível ver que eu não faço as duas coisas exatamente ao mesmo tempo, mas sim, intercaladamente, mudando de uma tarefa para a outra a cada certo intervalo.
É basicamente assim que as threads funcionam: elas são como “unidades de processamento virtuais”, que uma CPU executa com exclusividade por 30 milissegundos cada. Humanamente falando, imagino que seja impossível perceber essa mudança de contexto; por isso, tudo parece realmente simultâneo para nós.
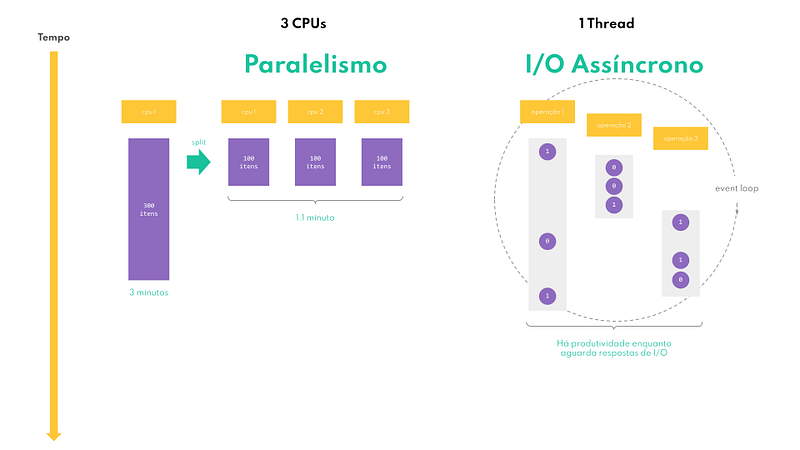
Já no caso da assincronicidade, consideramos assíncrono aquilo que não vai acontecer do início ao fim exatamente agora, que pode ter um curso intermitente, e não queremos ficar sem fazer nada enquanto esperamos por sua conclusão, que acontecerá em algum momento futuro. Isso é tipicamente comum com operações de I/O.
Operações de I/O não dependem apenas de software, obviamente, mas invariavelmente de dispositivos de I/O (a.k.a. hardware), que de algum modo compõe ou complementam um computador, cada qual com seu modo de funcionar, seu tempo de resposta e outras particularidades quaisqueres. Alguns dos dispositivos de I/O mais comuns são: HD, monitor de vídeo, impressora, USB, webcam e interface de rede. Qualquer programa de computador que valha seu peso em sal executa alguma operação de I/O ⎼ mostrar “hello world” em uma tela, salvar um texto qualquer em um arquivo, iniciar um socket de rede, enviar um e-mail, etc.
Voltando à cozinha para mais um exemplo, digamos que o jantar de hoje seja macarrão à bolonhesa e salada verde com tomates cerejas e cebola. Como poderia acontecer a preparação desse cardápio? Bom, eu poderia fazer uma coisa de cada vez, de modo sequencial. Ou poderia tentar otimizar um pouco meu tempo, minimizando o tempo que fico sem fazer nada, aqui e ali, esperando por algum “output” qualquer.
- Eu começo colocando uma panela de água para ferver, onde vou cozer o macarrão. Enquanto ela não ferve, eu corto cebola, alho e bacon para refogar a carne moída;
- Terminando, a tarefa de pré-preparo, sequencialmente, enquanto ainda espero a água para o macarrão chegar à fervura, começo então a preparar a carne moída ⎼ refogo, coloco temperos diversos, extrato de tomate e deixo cozer em fogo médio;
- Vejo que a água começou a ferver, então, acrescento um tanto de sal e ponho o macarrão para cozer. Okay, agora, enquanto o macarrão cozinha por aproximadamente 8–10 minutos e a carne moída também está cozendo, apurando o sabor, o que eu faço? Sento e espero? Não! Ainda tenho que preparar a sala;
- Lavo as folhas verdes, os tomates, corto a cebola, junto tudo em uma saladeira (trriiimmm!!!) ouço o alarme indicando que o macarrão está cozido e é hora de escorrê-lo rapidamente, mesmo que tenha que parar o preparo da salada, momentaneamente, afinal de contas, só falta temperar e isso não é algo tão crítico, pode acontecer daqui um pouco; já o macarrão, precisa ser escorrido agora!
- Escorro o macarrão, coloco em uma travessa de macarronada, despejo a carne moída por cima, misturo cuidadosamente e finalizo ralando uma generosa quantidade de queijo parmesão por cima;
- Levo a travessa de macarronada para a mesa de jantar, volto à cozinha, tempero a salada rapidamente e levo para mesa também;
- Tá na mesa, pessoalll!!!
Vê como tudo aconteceu de modo predominantemente assíncrono, porque cada preparo teve seu tempo e sua prioridade? Tudo aconteceu de modo intercalado. Foram 40 minutos intensos, sem ficar um minuto parado sem fazer nada, mas aproveitei muito melhor o meu tempo.
É basicamente assim que funcionam as operações de I/O assíncronas: uma única thread é capaz de despachar milhares de operações de leitura ou escrita para os diversos dispositivos de hardware de um computador, conforme as requisições vão chegando; e enquanto as respostas dos dispositivos não chegam, indicando que as operações foram bem sucedidas ou não, elas vão atendendo a outras requisições; e assim seguem, em um loop semi-infinito.
Por que uma thread ficaria parada, bloqueada, esperando pela resposta de uma escrita em um socket, que pode levar certo tempo, enquanto poderia estar escrevendo algo em um arquivo no disco rígido? Essa é a magia do I/O assíncrono in a nutshell. Depois, assista à minha talk no YouTube, que lá eu me aprofundo mais no assunto; não quero me repetir aqui.
Como você provavelmente já notou, tanto a abordagem paralela, quanto a assíncrona, são maneiras de se implementar concorrência em uma aplicação, cada qual com sua finalidade. A primeira, envolve threads de execução em múltiplas CPUs simultâneas; a segunda se baseia em máquinas de estado, futures e callbacks, executando possivelmente em uma única thread.
Espero que essa introdução tenha sido suficiente para ficarmos todos na mesma página.
Paralelismo está no menu hoje
O assunto da vez hoje é paralelismo com C#. E para continuar se aprofundando no assunto, uma visão de alto-nível da arquitetura de programação paralela oferecida pela plataforma .NET.
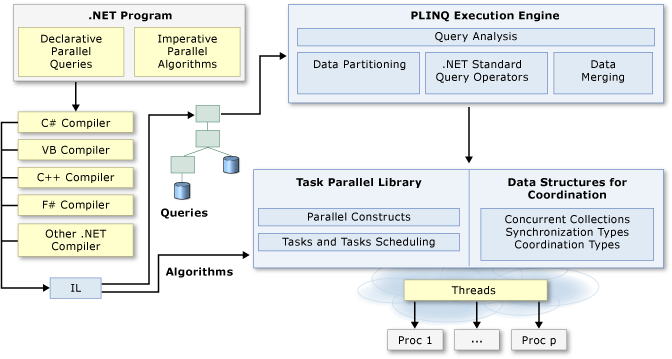
Eu acho importante começar com essa big picture, porque infelizmente, a plataforma .NET não ajuda muito com aquela distinção de assíncrono vs paralelo, que vimos há pouco. A razão disso é que a classe Task é o ponto de partida da Task Parallel Library (TPL) tanto para algoritmos assíncronos quanto para paralelos.
A documentação sobre Task-based Asynchronous Programming (TAP) define “task parallelism” como “uma ou mais tarefas independentes executando concorrentemente”, o que soa um pouco fora do que vimos há pouco.
Já a documentação sobre Parallel Programming in .NET (fonte do diagrama acima), por sua vez, diz que “muitos computadores pessoais e estações de trabalho têm vários núcleos de CPU que permitem que várias threads sejam executadas simultaneamente”, e então, conclui dizendo que “para aproveitar as vantagens do hardware, você pode paralelizar seu código para distribuir o trabalho entre vários processadores”. Isso faz mais sentido para mim.
Acredito que isso se dê pelo fato de que eles quiseram implementar uma abstração única de tarefas independentes em cima do modelo de threads, que são executadas a partir de um thread pool, que por sua vez, dispara a execução delas em um número de CPUs disponíveis ⎼ por padrão, o número mínimo de threads do ThreadPool é equivalente ao número de CPUs disponíveis no sistema.
O que vale é a intenção
Uma dica de ouro, que para mim ajuda bastante, é olhar para a classe Task sob a ótica daquilo que tenho a intenção de implementar.
- Os membros .Result, .Wait(), .WaitAll(), .WaitAny() são bloqueantes (a.k.a. síncronos) e devem ser usados somente quando se tem a intenção de implementar paralelismo. Tarefas paralelas estão relacionadas ao que chamamos de CPU-bound e devem ser criadas usando preferencialmente os métodos .Run() e .Factory.StartNew();
- Além da palavra-mágica await, usada para aguardar assíncronamente a conclusão de um método assíncrono (na prática, uma instância de Task ou Task<T>), os métodos .WhenAll() e .WhenAny(), que não são bloqueantes (a.k.a. assíncronos), devem ser usados quando a intenção for implementar assincronicidade. Tarefas assíncronas estão relacionadas ao que chamamos de I/O-bound.
A propósito, TaskCreationOptions.AttachedToParent pode ser usada na criação de uma tarefa paralela (estratégia “divide and conquer” / “parent & children”), mas não por uma tarefa assíncrona. Tarefas assíncronas, de certo modo, já criam sua própria “hierarquia” via await.
Okay, vamos focar em paralelismo a partir daqui e ver um pouco de código.
Colocando a mão na massa
Como vimos há pouco, tarefas paralelas vão bem para implementar processos que sejam CPU-bound; ou seja, que levam menos tempo para conclusão em função do número de CPUs disponíveis para particionamento/execução do trabalho.
O código fonte dos exemplos está neste repositório aqui.
Podemos dividir esse cenário em duas categorias de processamento:
- Estático — data parallelism
- Dinâmico — task parallelism
Processamento paralelo “estático”
Chamamos essa categoria de estática, porque se trata de iterar uma coleção de dados e aplicar um dado algoritmo em cada um de seus elementos. Para isso, a TPL nos oferece três métodos a partir da classe Parallel.
1. For() ⎼ análogo ao for clássico
Repare nos parâmetros passados na invocação do método Parallel.For(), na linha 14. Além dos típicos limites inicial e final, há também uma Action<int, ParallelLoopState>, que provê o índice da iteração atual e um objeto com o estado do loop. É a partir deste objeto de estado que solicitamos um “break” no loop.
Uma outra coisa a se notar é o seguinte: diferente de um loop for clássico, que acontece sequencialmente, este Parallel.For() pode ter sido escalonado para rodar em múltiplos processadores simultaneamente; portanto, um break não é imediato, evitando que a próxima iteração aconteça. Pelo contrário, é bem provável que um número de iterações tenham sido iniciadas em um breve momento anterior ao .Break() ser invocado. É por isso que, na linha 19, precisamos checar se podemos ou não continuar a iteração atual.
E finalmente, note que na linha 32 há um lock da variável random. Isso é necessário por se tratar de um processo paralelo, que vai potencialmente mutar essa variável concorrentemente ao longo das iterações. Idealmente, você vai evitar esse tipo de cenário, porque onde há lock, há contenção; e onde há contenção, há tempo despendido esperando. Você não quer isso, mas às vezes é preciso.
— A little break here —
Acho que esse é o momento ideal para dizer que paralelismo pode criar situações de concorrência, intencional ou acidentalmente, dependendo do que você está implementando — porque programação paralela é um tipo de multithreading; e multithreading é um tipo de concorrência.
Se você ficou com dúvidas sobre isso, se ficou confuso com a terminologia, se acha que é tudo a mesma coisa, ou algo assim, tudo bem, não se desespere. Eu sei que, como acontece com assincronicidade e paralelismo, concorrência e paralelismo também são confundidos o tempo todo.
O artigo da Wikipedia sobre concorrência (em inglês) traz um ótimo resumo do Rob Pike, que distingue bem uma coisa da outra: “Concurrency is the composition of independently executing computations, and concurrency is not parallelism: concurrency is about dealing with lots of things at once but parallelism is about doing lots of things at once. Concurrency is about structure, parallelism is about execution, concurrency provides a way to structure a solution to solve a problem that may (but not necessarily) be parallelizable.”
Se tiver um tempo extra, recomendo que você veja a apresentação do Rob Pike, Concurrency is not Parallelism, para ter uma introdução amigável ao assunto.
2. ForEach() ⎼ análogo ao foreach clássico
Semelhantemente ao que se pode fazer com um loop foreach, aqui, Parallel.ForEach() está recebendo um IEnumerable<int> provido por um generator (a.k.a. yield return). Além deste parâmetro, há ainda outros dois: um com opções de configuração de paralelismo e uma Action<int, ParallelLoopState, long>, que pode ser usada como no exemplo anterior.
O ponto de destaque neste exemplo vai para a linha 29, onde é definido um CancellationToken para o loop. Naturalmente, o objetivo do CancellationToken é sinalizar o cancelamento de um processo que está em curso. E neste caso, o cancelamento ocorre na linha 18, depois de um intervalo randômico ⎼ to spice it up.
Este é um pattern bastante comum na plataforma .NET, que você já deve estar bem acostumado, pois se vê isso por toda parte da biblioteca padrão.
3. Invoke() ⎼ neste caso, a coleção iterada é de algoritmos
Este caso é um pouco diferente dos dois anteriores. Nos casos anteriores, o problema que você estava querendo resolver era o seguinte: você tinha uma coleção de itens sobre os quais você queria aplicar um dado algoritmo, e para fazer isso o mais rápido possível, você queria tirar proveito do número de CPUs disponíveis e escalonar o trabalho entre elas.
Agora, neste caso, o problema é que você tem um número de algoritmos para executar (independentes uns dos outros, de preferência) e gostaria de fazer isso o mais rápido possível. A solução, no entanto, é essencialmente a mesma.
Um bônus no código acima, que não tem exatamente a ver com a questão do .Invoke(), mas que é super interessante e vale a pena comentar, é o método .AsParallel() sendo invocado no long[], na linha 13. Este método é parte da chamada Parallel LINQ (PLINQ), que torna possível a paralelização de queries LINQ.
Como você já deve imaginar, o que a PLINQ faz é particionar a coleção em um número de segmentos, e então, executar a query em worker threads separadas, em paralelo, usando os processadores disponíveis.
A propósito, assim como os dois métodos anteriores, .Invoke() também suporta CancellationToken via ParallelOptions.
Processamento paralelo “dinâmico”
Chamamos essa categoria de dinâmica, porque não se trata de iterar em uma coleção e aplicar um determinado algoritmo; também não se trata de invocar uma lista de métodos em paralelo. Na verdade, trata-se de iniciar uma nova Task (ou mais de uma), que vai executar um processo custoso em uma worker thread, em paralelo, se possível, e poderá iniciar outras Tasks “filhas” a partir dela, criando uma hierarquia, onde a tarefa mãe só será concluída quando suas filhas tiverem concluído.
Inicia, se divide, trabalha, converge e finaliza.
Essa é a uma categoria de paralelismo em que, questões como: quantas tarefas mães, quantas tarefas filhas, que processos cada uma delas realiza, em que circunstâncias, em que ordem, etc, etc, etc, são todas respondidas em runtime, de acordo com as regras xpto de cada caso de uso. Daí referir-se a ela como dinâmica.
Os métodos da classe Parallel e a PLINQ são super amigáveis, convenientes, e você deve tentar usar sempre que possível. Mas quando o problema for um tanto mais flexível, dependente de informações conhecidas somente em runtime, o negócio é partir para Task. Por exemplo, você precisa percorrer uma estrutura de árvore e, dependendo do nó, executar um processo ou outro.
Note que o exemplo acima usa o método Task.Factory.StartNew(), para criar e disparar a execução de instâncias de Task, e não o famoso Task.Run(), que estamos bem acostumados a usar, quando estruturamos aplicações para lidar com problemas de modo concorrente.
O caso é que, o método .Run(), na real, nada mais é do que uma maneira conveniente de invocar.StartNew() com parâmetros “padrões” (veja o fronte dele aqui). E como você já deve imaginar a essa altura do campeonato, é justamente por conta desses parâmetros “padrões” que ele não atende aos requisitos do exemplo acima. Bem, para ser mais específico, estou me referindo ao parâmetro TaskCreationOptions.DenyChildAttach, que nos impede de ter tarefas filhas. Quer testar isso? Substitua .StartNew() por .Run() na linha 12, ou então, o parâmetro TaskCreationOptions.None por TaskCreationOptions.DenyChildAttach, na linha 15, e veja o que acontece ⎼ repare bem na ordem das saídas de console.
Viu?
A regra então é: sempre que for criar e disparar a execução de uma Task, priorize .Run(), a menos que o caso que você vai implementar peça por parâmetros específicos, diferentes dos padrões. Nestas circunstâncias, use .StartNew() e configure a gosto.
[Para ser mais correto com a informação que estou entregando, eu tenho que dizer que, nem o método .Run(), nem o método .StartNew(), “disparam” a execução de uma Task. O que eles fazem, na verdade, é “colocar a Task na fila de execução do ThreadPool, através de um TaskScheduler”. Veja que a própria classe Task tem uma propriedade Status que ajuda a entender seu o ciclo de vida.]
Dica #1 ⎼ Long Running Tasks
Podemos dizer que uma Task é long-running quando ela permanece rodando por minutos, horas, dias, etc. Ou seja, não é uma tarefa de alguns poucos segundos de duração. Para isso, há a opção TaskCreationOptions.LongRunning, que pode ser passada para o método .StartNew().
O que essa opção faz é sinalizar ao TaskScheduler que se trata de um caso de oversubscription, dando a chance do TaskScheduler se precaver contra um fenômeno conhecido como “thread starvation”. Para tanto, duas ações são possíveis ao TaskScheduler: (1) criar mais threads do que o número de CPUs disponíveis; (2) criar uma thread adicional dedicada à Task, para que assim, ela não engargale o fluxo natural de trabalho das worker threads do ThreadPool.
Até aí, tudo bem. Problema resolvido. Espere. Mesmo?
Tarefas com corpo async, ou seja, que seu delegate await por outras tarefas, por si só, naturalmente, já possuem um fluxo de execução escalonado de acordo com sua máquina de estado. Portanto, elas não consomem uma mesma thread por muito tempo; cada passo da máquina de estado pode ser executado em uma thread diferente.
Se você não sabe do que estou falando, veja a minha talk.
O que fazer então? A menos que seu processo long-running não use await, não aguarde a execução de nenhuma Task, seja lá de que maneira, esqueça a opção TaskCreationOptions.LongRunning. Use .Run() e deixe que o TaskScheduler faça seu trabalho autonomamente ⎼ em raros casos ele realmente precisa de “dicas”.
Dica #2 ⎼ Exceções
Sim, elas existem e uma hora ou outra vão ocorrer. Lide com isso. Quero dizer, literalmente!
Quando você estiver trabalhando com tarefas aninhadas, parent & children, como no exemplo que vimos há pouco, quando ocorrer uma exceção, você vai receber uma AggregateException borbulhando. Não importa se você await ou .Wait() a Task, uma AggregateException é o que você vai ter. Sendo assim, muito do que eu falo sobre o uso de .Wait() e exceções na minha talk não se aplicam a esse tópico de hoje. Mas isso não significa que você deva preferir .Await() em lugar de await ⎼ pelo contrário. Evite bloquear a “thread chamadora” desnecessariamente.
Uma dica para lidar com isso é usar o método .Flatten() da AggregateException. A grosso modo, o que esse método faz é criar uma única exceção com a exceção original incluída na propriedade InnerExceptions. Assim você não tem que ficar iterando por exceções aninhadas.
Outra dica é usar o método .Handle().
Dica #3 ⎼ Cuidado com aplicações web
Programação paralela visa aumentar o uso das CPUs, temporariamente, com intuito de aumentar o throughput da aplicação. Ótimo! Queremos isso. Afinal, muitos desktops ficam com a CPU idle boa parte do tempo. Mas cuidado, porque isso não é sempre verdade quando se trata de servidores.
Servidores rodando aplicações ASP.NET, por exemplo, podem ter menos tempo de CPU idle, dependendo do volume de requisições simultâneas, porque o próprio framework lida com múltiplas requisições em paralelo, visando tirar melhor proveito do ambiente multicore disponível. Portanto, botar código que atende a requisições de clientes para rodar em paralelo, pode acabar sendo um baita de um tiro no pé, quando houver um grande volume de requisições simultâneas.
Além disso, o ASP.NET pode limitar o número de threads usadas até mesmo pela TPL. Sendo assim, até mesmo um Task.Tactory.StartNew() da vida pode ser uma senhora martelada no dedão.
Via de regra, muito cuidado com multithreading em aplicações web.
Concluindo
Ao longo deste mais do que longo post, diferenciamos tarefas assíncronas de tarefas paralelas, nos aprofundamos nas paralelas e vimos algum código para ilustrar a discussão. Também vimos que concorrência não significa necessariamente paralelismo. Mas pode vir a ser, eventualmente.

Se você chegou até aqui e gostou, por favor, compartilhe com seus amigos, deixe seu comentário, suas dúvidas, e vamos nos falando.
Se mesmo tendo visto o meu webinar, você ainda tiver dúvidas sobre async/await, bota suas dúvidas aqui nos comentários. Quem sabe não consigo te ajudar? Não custa tentar.
Ah! E por falar em webinar, talvez eu faça um webinar discutindo o conteúdo deste post. Ou talvez me aprofunde mais no assunto concorrência, algo nessa linha. Seria a última peça do quebra-cabeças. Vou pensar a respeito.
Até a próxima!
—
BTW, estamos contratando 🙂
Se você ainda não conhece a nossa stack e quer saber como você poderia nos ajudar a construir a Pricefy, que foi recentemente adquirida pela Selbetti, dá uma checada nesses bate-papos:
- ProdOps ⎼ Engenharia e Produto com Leandro Silva (link 1 e link 2);
- ElvenWorks ⎼ Conhecendo a tecnologia por trás de uma solução muito inteligente de Precificação (link).
Se tiver interesse: leandro.silva@pricefy.com.br. A gente segue de lá.