Dados estão por toda parte. Eles sempre estiveram. Cada dia em maior número e mais diversos do que costumamos pensar.
Dados são a origem fundamental a partir da qual toda informação existe.
Any time scientists disagree, it’s because we have insufficient data. Then we can agree on what kind of data to get; we get the data; and the data solves the problem. Either I’m right, or you’re right, or we’re both wrong. And we move on.
Neil deGrasse Tyson
Dados são fatos em estado bruto, não organizados, que precisam ser processados. Por vezes, podem parecer aleatórios, mas quando processados, organizados, analisados e apresentados em um determinado contexto, nos dão informações úteis para o conhecimento factual do mundo ao nosso redor.
Evidence based medicine (EBM) is the conscientious, explicit, judicious and reasonable use of modern, best evidence in making decisions about the care of individual patients. EBM integrates clinical experience and patient values with the best available research information.
Izet Masic, Milan Miokovic, and Belma Muhamedagic [article]
Sem conhecimento factual não há como ter evidências de que algo é real ou irreal, verdadeiro ou falso, promissor ou um completo desperdício de tempo e dinheiro. Evidências são a razão para acreditar.
Primeiro as primeiras coisas
“Big data, AI, machine learning, deep learning, data-driven”, não sei se em outras áreas é assim, mas em desenvolvimento de software adoramos a nova palavra da moda. Não importa se o objeto ao qual a palavra se refere é algo novo ou não, o que importa é que se “todo mundo” está falando, vamos falar também.
No final das contas, a coisa acaba ficando mais ou menos como a famosa frase do professor de psicologia e economia comportamental Dan Ariely:
Big Data is like teenage sex: everyone talks about it, nobody really knows how to do it, everyone thinks everyone else is doing it, so everyone claims they are doing it.
Dan Ariely, Duke University [tweet]
O que é menos conhecido é um outro comentário dele, desta vez sobre educação e aprender a lidar com dados:
Instead I proposed that management education and practice should become much more experimental and data-driven in nature — and I can tell you that it is amazing to realize how little business know and understand how to create and run experiments or even how to look at their own data! We should teach the students, as well as executives, how to conduct experiments, how to examine data, and how to use these tools to make better decisions.
Dan Ariely, Duke University [post]
Educação antes de chavão. Aprender a lidar com dados para então poder ser guiado por eles. A menos que você não se importe de se deparar com a beira do penhasco tarde de mais.
Começando por baixo
Tomando emprestado um pouco da teoria da Hierarquia de Necessidades de Maslow e extrapolando para o nosso assunto dados, dá para pensar em uma pirâmide mais ou menos como a seguir:
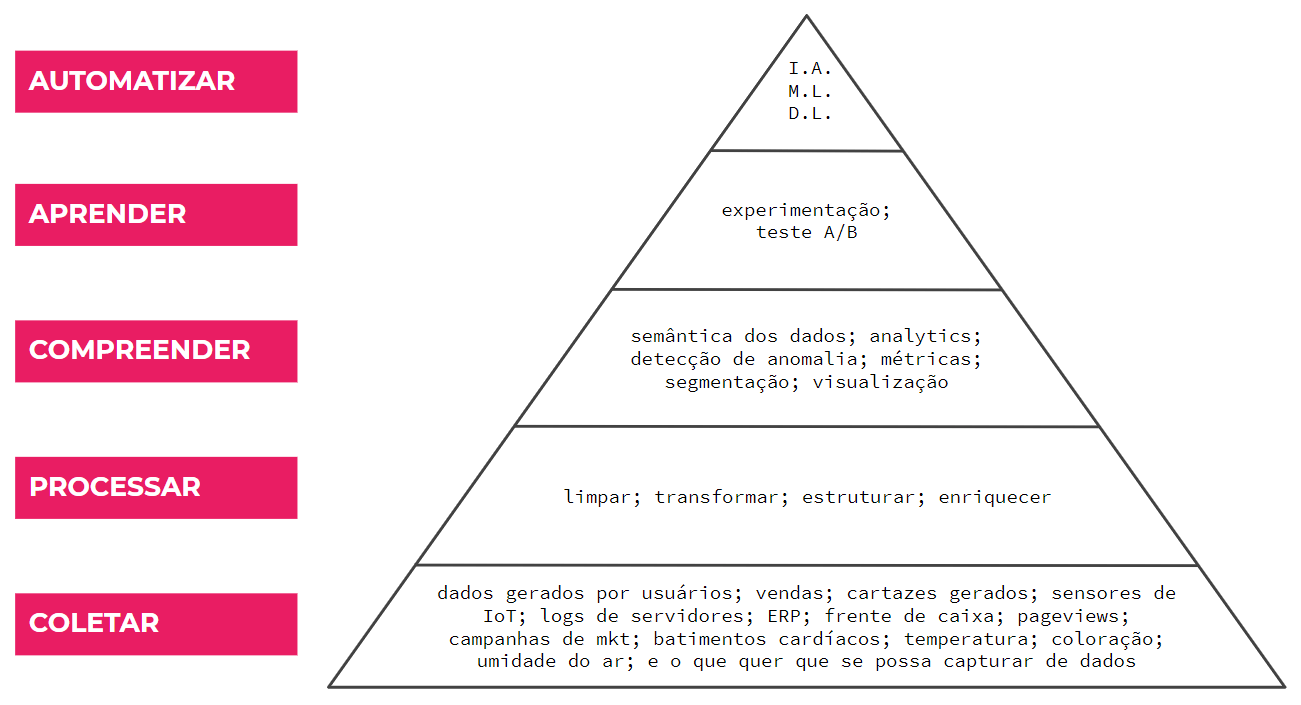
E enquanto vemos que muito se fala de inteligência artificial, machine learning, deep learning, etc, pouco ainda se discute sobre o fundamental, sobre a base da pirâmite: coletar dados de maneira consistente, confiável e que permita escalar a pirâmide com segurança. Ou pelo menos, com mais segurança do que nenhuma segurança.
Já ouvi inumeros casos de empresas que contrataram cientista de dados quando nem sequer tinham dados para serem trabalhados. Melhor dizendo, não é que não tinham dados, porque como vimos no começo deste post, dados estão por toda parte; o que eles não tinham era coletado seus dados de maneira sistemática e disponibilizado para que pudessem ser usados para analise, modelagem, predição e automação de processos.
Dados precisam fluir
Quando se pensa em coleta de dados, logo se pensa em integração de dados.
O problema de integração de dados existe há décadas, provavelmente, desde que dados armazenados e processados em um certo mainframe precisou ser transportado, armazenado e processado em outro mainframe, para servir de consolidação ou qualquer outro propósito. Bem, certamente, muito antes dos mainframes existirem, se formos considerar o modo como os censos demográficos dos países eram realizados há séculos. Mas vamos nos ater aos computadores modernos.
Denunciando um pouco a minha idade, eu entrei para o saudoso colegial técnico em processamento de dados em 1997, quando tínhamos uma matéria que se propunha a nos ensinar Técnicas de Sistemas de Processamento de Dados. Na época, usavamos DBase III+ e Clipper.
De lá para cá, vi sistemas serem integrados por arquivo texto transferidos por disquete ou modem; depois foram os drives compartilhados na rede local e o FTP para quem estava de fora.
Então, depois de um tempo, começamos a fazer integrações em banco de dados – Interbase, Oracle, DB2, Sybase. Todo mundo se conectava ao gerenciador de banco de dados que estava disponível na rede e era aquela festa. “Deadlock? Yeah, true story, bro.”
Aí foi a vez do SOA com seus imponentes ESBs. Bem, imponentes até a página dois, quando a festa da integração via banco de dados migrou para eles.
A moral da história qual é? Dados precisam fluir. Eles precisam ir de um lugar para o outro; e de uma maneira ou de outra, isso vai acontecer.
Deixando os dados fluírem
Se você chegou até aqui, você deve estar se perguntando: ok, deve haver uma maneira certa de fazer os dados fluírem, certo? A resposta é depende.
– Para aonde esses dados precisam ir?
– Com que frequência?
– Qual o seu volume?
– Eles são sensíveis? (LGPD)
– O que acontece se eles forem corrompidos?
Estas e outras perguntas é que vão nos guiar à maneira mais correta de implementar o fluxo dos dados que entrarão, circularão e sairão da organização em que trabalhamos. Arrisco a dizer que não há certo e errado, mas sim, a maneira que dará mais ou menos dor de cabeça no curto, médio e longo prazo.
Acrescente à conta:
– Custo de implementação da solução inicial;
– Custo de manuteção da solução em produção;
– Custo de migração para uma possível nova solução;
– Expertise da equipe que vai fazer tudo isso.
Uma dentre muitas
Muito embora, possa não existir “a maneira certa” ou “a maneira errada” em absoluto, há muitas maneiras que já foram documentadas, aqui, ali, lá e acolá; e há certamente bastante terreno comum entre elas.
O que eu quero, então, é dedicar o final deste looongo post para falar brevemente, em alto nível, sobre uma maneira que há alguns anos tem emergido com sucesso e sido recomendada para muitos casos de plataforma de dados.
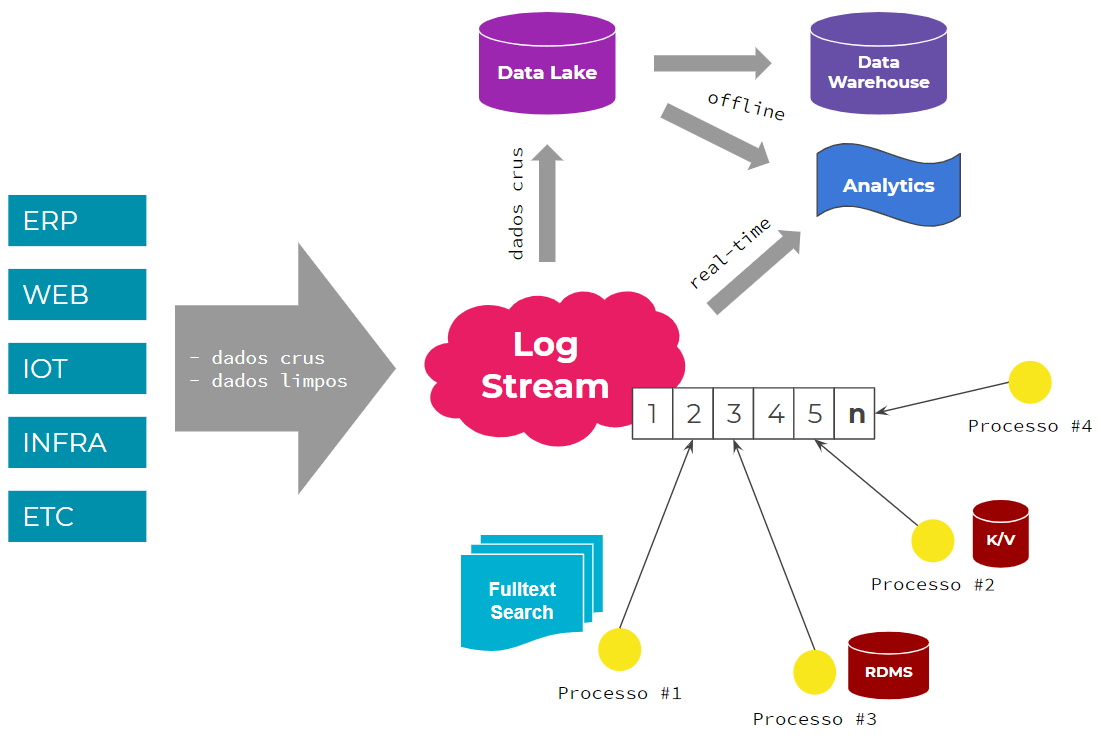
Eu acho que a primeira coisa que se pode notar no diagrama acima é que trata-se de uma arquitetura de sistemas centrada em um log stream.
Arquiteturas desta natureza tem o log stream como canal de entrada de dados para um contexto onde possam ser conhecidos, usados e manipulados por diversos sistemas e aplicações de um ecossistema.
Uma característica fundamental de logs é que são append only por natureza. Já a durabilidade de seus registros pode variar de acordo com a finalidade deles, podendo ser finita ou indeterminada.
Algumas empresas vão tão longe quanto terem seu log stream como fonte única de verdade para seu ecossistema de aplicações. Na prática, um registro histórico. Ou seja, em caso de perda de dados por falha humana ou bug em alguma aplicação, que tornou seu estado persistente inválido, é possível usar o log para voltar no tempo, reprocessar seus registros factuais cronologicamente e chegar a um novo estado persistente, agora correto.
Viagem no tempo, eles disseram.
Desnecessário mencionar que, em arquiteturas orientadas a eventos, o log stream é a espinha dorsal de onde os eventos são propagados.
Okay, vamos segmentar um pouco o diagrama acima.
A Entrada
A ideia é que este canal permida a entrada tanto de dados brutos quanto limpos. Podendo os últimos serem fatos e eventos do processo de negócio, tais como perfil de usuário criado, pedido de compra realizado, pagamento confirmado, etc. Já os primeiros, dizem mais respeito a logs de acessos, telemetria, clickstream, tudo o que precise ser analisado dentro de um contexto, para então produzir alguma possível informação útil para o negócio em um futuro não imediato.
Protocolos, schemas, metadados, são todos importantes desde este momento para que o fluxo dos dados seja confiável e sem entraves ao longo do caminho; principalmente, porque o tempo de vida dos dados pode ser indeterminado. O que quer dizer que você pode ter que lidar com um registro malformado por muito, muito, muito tempo mesmo. Mas isto não quer dizer que não deva haver flexibilidade. Pelo contrário, significa que deve haver intenção no formato dos dados, seja ele bruto ou tratado, e metadados que os descrevam. Isto vai promover descoberta e uso por um longo tempo.
Uma coisa interessante sobre dados é que eles geralmente vivem mais tempo do que as aplicações pelo meio das quais foram registrados pela primera vez.
Dados brutos, crus, podem ser trasnformados em algo útil para uma determinada aplicação (a.k.a. event sourcing) e/ou serem enviados para um data lake, para depois então servir de input para analises diversas ao escalar a pirâmide que vimos há pouco.
Dados limpos, por sua vez, geralmente vão ser eventos que precisam ser respondidos por algum agente primário e podem ter muitos outros espectadores secundários, outros agentes interessados em fazer algo com o fato noticiado. Por exemplo, a notícia de que um pedido acabou de ser finalizado por um determinado cliente de e-commerce. Quantos processos podem ser iniciados a partir deste fato? Desde processos transacionais, para que o produto seja finalmente entregue, quanto processos analítcos, para entender a venda realizada, colocando tudo no papel, a lista poderia ficar tão longa quanto este post.
O Processamento
O que acontece nessa etapa? Quem é que sabe! Isso vai depender da organização.
Em geral, o que vai acontecer são limpezas, transformações, reestruturações, enriquecimentos de dados, para então serem carregados em outras bases de dados com finalidades específicas, sejam elas relacionais, não-relacionais, analíticas, fulltext search, ou mesmo sistemas ERP, CRM e o que quer que se possa imaginar.
Como mencionado no estágio anterior, processos de negócio podem ter seu início aqui também. Aliás, sendo uma arquitetura centrada em log stream, este é o mais provável. Na ocasião do registro de que um pedido foi finalizado no site, um sistema de pagamento que faz integração com um sistema de terceiro, pode reagir chamando uma API, para processar a transação financeira; um sistema de CRM pode reagir registrando características da venda; e assim por diante.
Seguindo esta linha de raciocínio, no caso de um provedor de cloud computing, por exemplo, vai haver um serviço de provisionamento de infraestrutura, registro de domínios e aplicações SaaS, na expectativa do evento de pagamento realizado ser incluído no log.
Poderia ser também uma campanha de marketing que acabou de ser criada e registrada no log stream, que… okay, você já pegou a ideia.
O ponto crucial aqui é que o sistema que reage a um evento, não está acoplado ao sistema que produz o evento. Idealmente, eles nem se conhecem. Em outras palavras, quem produz o dado não sabe exatamente quem vai consumi-lo e para que finalidade.
A Saída
Suficiente dizer que o céu é o limite.
Vantagens
A principal vantagem que vejo é que uma arquitetura centrada em log stream reduz a complexidade de integração de aplicações a 1-para-1. Em vez de ter que escrever código de integração para se comunicar com N aplicações e sistemas heterogênios, criar processos de ETL, você escreve código para apenas um canal de comunicação, um ponto único de integração. É claro que cada input é um input e você vai ter que lidar com isso semi-individualmente, porque é algo mais relacionado à semântica da comunicação do que qualquer outra coisa. Mas é possível criar alguns padrões para ajudar nisto, apenas tomando o cuidado de não incorrer no erro da generalização generalizada.
A segunda vantagem é o desacoplamento, que até tem um pouco a ver com a vantagem anterior. Mas o ponto aqui é que um sistema não fica dependendo de fazer as chamadas imperativas a outros sistemas diretamente, em uma exata ordem, tendo que lidar com latências diversas, modos de falha, etc. Você registra um fato, notifica a ocorrência de um evento, e o que vai acontecer depois disso torna-se mais flexível do que se você tivesse que fazer uma chamada imperativa dizendo “faça isso agora”.
Finalmente, você tem um registro temporal durável de tudo que aconteceu desde um determinado ponto no tempo, como a nossa história que não pode ser apagada. E como benefício adicional, você tem a possibilidade de voltar no tempo e reprocessar dados desde certo ponto, não alterando a história, que é imutável, mas criando novos registros que são uma correção histórica.
É claro que se você não tem todo espaço em disco do mundo e não tem interesse eterno em tudo que é inserido no log, você pode definir políticas diferenciadas de retenção. O meio do caminho é uma opção. Não precisa ser sempre oito ou oitenta.
Desvantagens
Não é fácil. Não, é sério. Não é fácil. Se te disseram que é fácil, mentiram.
Você precisa de pessoal capacitado, com múltiplos conhecimentos e especialidades. Não dá para pegar meia dúzia de juniores e se colocar a implementar uma arquitetura deste tipo da noite para o dia.
Você tem o custo de infraestrutura, de operação, de mantenção, etc.
O que se precisa analisar é o suposto benefício que se terá com uma arquitetura destas em função de onde a organização está hoje e onde se imagina que ela estará em, digamos, 3-5 anos. Chegariam melhores, com menos dores de cabeça e mais noites bem dormidas se caminhassem para uma arquitetura semelhante a essa?
Decisões de arquitetura não precisam ser todas tomadas no dia 1, podem ser incrementais. Mas um bom roadmap ou um mapa de possíbilidades nunca deixou ninguém com insônia.
Comece seu desenho de arquitetura de sistemas sempre pelo mais simples e vá incrementando. Baby steps. Você vai ver que o mais simples pode ser bem sofisticado, quando permite que a complexidade inevitável seja adicionada aos poucos.
A tecnologia da vez
Provavelmente, você deve ter notado que em momento algum eu cito uma tecnologia específica para implementar esta arquitetura. Nenhuma. Isto porque a minha ideia com este post é tratar a coisa do ponto de vista dos primeiros princípios, dos princípios fundamentais de arquitetura de sistemas e não de tecnologias específicas, que mudam com o tempo.
Como você vai implementar a arquitetura particular da sua organização, tendo domínio conceitual do que pretende fazer e de padrões arquiteturais que emergiram ao longo dos anos, é que é outra coisa. É isto que importa. Esta é a maneira de você não ficar vendido por tecnologias específicas, por vendors, e acabar querendo fazer isso e aquilo por conta de uma tecnologia ou vendedor. Princípios vêm primeiro. Ouch!
Para você ter uma ideia, há 10 anos eu trabalhava em uma empresa onde implementamos um baita sistema usando muitos conceitos que vimos até aqui (propagação de eventos, message brokers, feeds, entre outras coisas), um pipeline bem robusto, sem usar a maioria das tecnologias mais populares de hoje.
O importante é cuidar bem de seus dados na base da pirâmide e estar preparado para escalar com eles para o próximo nível.

Uma consideração sobre “Dados, necessidades básicas e arquitetura de sistemas”