As much as I would like to be, I am not a computer science academic. Not at all.
I took a different path though.
I’ve been spending a big chunk of my days reading, writing, changing, and debugging computer programs for 25 years now. During this time, I’ve earned a technical degree in Data Processing, sat on a Computer Science undergrad course for more than 3 years (before drop out on the 4th year, a semester or so before graduate), and later on ended up pursuing a postgraduate degree in Data Science & Big Data, after earn a bachelor’s in Nutrition.
In those last 25 years, you better bet I’ve read a fair bit of books, articles, blogs, and whatnot, in an honest effort to educate myself. Still, I feel myself so undereducated to offer opinions outside my field of expertise ⎼ i.e. architect software systems for the Internet.
That’s why I always look for people who know better than me. So I don’t embarrass myself for free on the Internet. It might not be cool but it is intellectually honest. I’ll take it.
LLM Hype
As of late there has been a hype on the subject of LLM (large language models, e.g. GPT-3), especially ChatGPT. You must be living under a rock to have not heard about it. This thing is everywhere. People are freaking their minds about it. Some loving, some hating, and everything in between, I guess.
Here I am.
Even though I got a postgraduate degree in the subject of data science, I’m far away from being an expert in LLM. Far far away. Not even in the sight of human eyes. So my thoughts on it are based on my observations throughout the years and a fair share of real world experience as a software engineer. Take it with a grain of salt.
What do I think about it?
I think it might be a handy tool in your programmer toolbox. Have it there, as you have Google and Stack Overflow. That’s it. Simple as that.
I mean, let me elaborate a little more on this claim.
When I first got into programming, I had to buy books and magazines or borrow them from school and public libraries; also, I had a good buddy at work that taught me a lot about Clipper, and that was it. Then I discovered the online discussion forums (e.g. GUJ). And then I got to know about and attended to user groups meetings (e.g. SouJava). And then it was Stack Overflow, GitHub, and the plethora of technical content there is all around the Internet ⎼ you know what I’m talking about, just Google whatever about the most esoteric programming language and there you have it.
Those things weren’t mutually excludents, they were adding up one upon another, like bricks of a building. Or should I say a skyscraper? Go figure.
Anyway, I guess what I’m trying to say is that, even though I’m able to search anything on Stack Overflow (or rather on Google and then point & click it), read blogs, watch all sorts of interesting talks on YouTube, and so on and so forth, I still buy books and read through them. One thing does not exclude the other.
The same thing applies to LLM tools.
Be An Education-First Programmer
I would like to make a point here: I am a firm believer in “quality” education. And by that I mean attending formal university courses and reading “fleshy” books.
I know it is not a popular opinion nowadays, with all the bootcamps, quick video courses, and nano contents being heavily advertised out there, as if they are the penicillin of the 21st century, but honestly I couldn’t care less. Solidifying knowledge that passes the test of time calls for a strong education. So take your time, do the hard work, get past the quick tutorial, and get educated yourself.
Keep in mind that with just shallow knowledge you might not even be able to discern whether a Stack Overflow answer is right or wrong; and if it’s right, and if it works as expected, why it does. And in this case, what would you do if it doesn’t work? Trial and errorad nauseam, right? Which brings us to an indisputable fact.
Nobody likes that guy/gal in the office that asks questions all the time and wants to get every piece of information chewed up to just swallow it in without having to drop a sweat. I certainly don’t.
Let me tell you: copy & paste driven programming has been a thing for quite a long time, at least since we could find candidate solutions for most computing problems we search through the Internet. This is nothing new. People have been doing this thing for ages now. Much more after the advent of open source software and powerful search engines. And there is nothing wrong with copy & paste code from the Internet. Nothing. Well, at least until it does.
After all, we can copy & paste small snippets of code here and there, sample usages of APIs that we are not too familiar with, or that we haven’t used yet, or that we are getting a quick start. We all have done that and will still do. (Regex? Cron? Yeah, I feel you.) However, if we do not have a solid base on programming and software design, if we do not take our time to understand what we’re doing, we will end up in a frustrating loop of trial and error. Worse than that, folks, we will end up introducing hard to find bugs, performance issues, and security vulnerabilities in our software ⎼ which by the way, most of the time isn’t even our software but our employers’ software. Think about that for a second.
There is much more in software development than writing an SQL query, or building an API endpoint, or calling a remote service from a mobile app, or coding a depth-first search. A complete software solution is made of much more than that. Software engineering, as a field, is what’s concerned about that. Hence my point here is, if you don’t know what to ask for, what sort of answers do you think you’re gonna get? And will you be able to discern the right answer for your particular case?
As the saying goes, Garbage in, garbage out
When you read through answers on Stack Overflow, you better be quite sure about what you are looking for, to be reasonably assertive ⎼ there is a lot of junk content out there too, mind you; and they don’t come with a label “garbage”. Then you must take into account all the context of the original question and the provided answers, skipping the garbage here and there, before you can make a decision of copy & paste some code snippet as-is or write your own solution based on the built knowledge ⎼ e.g. the specific problem you’re trying to solve owns its particular edge cases. And this very thing, over and over, will add up knowledge to you.
See where we’re going? See my point here? See how ChatGPT can be a trap? You ask it, you get an answer. An answer so confident that if you don’t have a wide and solid knowledge of programming, you buy absolute horse crap without even knowing it. I’ve seen quite a lot of that with friends on Twitter and whatnot. Even with widely known algorithms.
As such, this “much more” is the thing we should care about (beside the basics) and is what we must focus on (provided we got the basics in place). Which brings us to another merciless fact.
We don’t know what we don’t know. And the only thing we can do about that is acquiring new knowledge, again and again ⎼ broad first, depth second.
Fundamentals of Software Architecture, Mark Richards & Neal Ford
This way, hopefully, we will know what we’re looking for and have at least a grasp of the answer when we find it.
– Broad knowledge gives us a direction to go search for answers; – Deep knowledge helps us discern among found answers.
Okay. Cool. But how do we do that?
For broadening your knowledge of what’s out there to know, I think blogs and YouTube videos are great. They are short content that you can consume on a daily basis without breaking a sweat. But for deep solid knowledge, in my opinion (N=1), there is nothing better than reading books and official pieces of documentation. And if you can, if you haven’t yet, get yourself a seat (physical or online) on a university course (graduate or postgraduate accordingly).
Again, not a popular opinion. But I’m not popular myself, so who cares?
Enters LLM tools
Nonetheless I have several unpopular opinions, I think this one will hit the parade: LLM might be an awesome tool to help you gain solid knowledge. How is that? I’ll tell you how.
Start by asking ChatGPT what has to be known about, let’s say, mobile apps development. Then ask for short tutorials and YouTube videos to get the big picture. Next, ask for highly recommended books and lectures about it. Because ultimately you want to read several deep articles, from different authors, with different points of view, to get a solid understanding of the topic you’re studying.
That’s for one thing. Another thing it might be helpful is when you’re reading through a book and get stuck by lack of knowledge of a given required subject. Ask ChatGPT to sum the said subject up for you, so you get a base before going ahead. Same thing you would do with Google, reading one or two sources but quick and right to the point. Yet, afterwards, go ahead and get deep into the said subject if it’s something important for the general matter you’re studying. It’s okay to do that.
And yet another circumstance it might be very helpful is while you’re up to develop a software application for a given domain you’re not too familiar with all the ins and outs. I saw that the other day and found it fairly smart.
Let’s say you’re going to develop a fitness mobile app, because you’re into fitness and are super thrilled with the idea of helping people get healthy and everything. Okay. But you don’t know all the apps there are out there, and their most loved features, and how they are monetized, etc. These are very objective questions. So you can ask these questions to ChatGPT to get started quickly. You ask about app requirements. You ask it to, for example, write the welcome email you’re gonna send to new subscribers of your awesome fitness app, because you’re not particularly good at this. Right. Now what? If you understood what I’ve talked about until this point, you already have a good sense of what you should do next. You improve it, you make it better, you put on your special sauce. In other words, break the inertia, which is the arguably most important thing in this case, then make it particularly special ⎼ otherwise, all you’ll have is generic stuff to sell out. Not cool, I guess.
If you get access to GitHub Copilot and it’s no harm to use it on your work, you can ask it to scaffold pieces of code to you, like a method to parse a file, a repetitive test case, or whatnot. You know, that boring stuff that you have to do every now and then and can’t be fully avoided with proper code design and smart libraries. Nothing wrong with that. You don’t get extra points not doing so ⎼ as long as there is no policy in place where you work.
There might be many other similar applications, mind you. Think about that.
Oh, wait. I thought about the greatest benefit this could bring us: Do you know those guys that like to post on forums asking for solutions to their schoolwork? Like, you know, you read the question and it’s almost the literal assignment statement. You’ve probably seen that before. Yeah, now they can ask ChatGPT for that and leave us alone. Everyone is happy about it.
Will LLM replace human programmers?
No. I don’t think so. I am very skeptical about “X is going to replace human programmers”. Since I started with programming in 1997, I’ve already heard my fair bit about fads like that.
It will likely change the way we get educated on programming, how we overcome blocks when we get stuck while programming, how we deal with boring stuff, but replace us, homo sapiens, for more than CRUDs and mundane widely known apps, no, I am very skeptical about that. I might be wrong though.
And know, finally, this article comes full circle with what got me motivated to write it down.
Yesterday I had the pleasure to stumble on an amazing article by Amy J. Ko, which was a real joy to read. First because I agree with mostly everything she wrote there. Second, because unlike me, she is an academic and has been following this subject matter for more than a decade. So she definitely has one thing or two to collaborate in this whole discussion without embarrassing herself.
So do yourself a favor, cut through the hype, and read these outstanding articles to get yourself a better sense of the topic from different point of views:
There is no TLDR; there. Take your time, enjoy the ride.
Now to end this long piece with a funny thing: I used to watch people make fun of academics all the time, saying how academia is far away from real world software development, and then, all of sudden, people are amazed and freaking out about a thing brought to life straight from academia research. What a big piece of irony. What a good time to be an academic.
Poucas coisas no mundo amplificam mais incrivelmente nossa percepção de “demora” do que usar um microondas ou navegar na web. Alguns segundos de espera na frente do microondas ou até menos do que isso, quando se trata de um navegador web, e voilà, bem-vindo à eternidade. Mas sem harpas ou cantos gregorianos, somente dor e ranger de dentes. Not cool.
Se alguma coisa pode ser rápida, queremos que ela seja o mais rápido que puder. Se alguma coisa pode estar lá, pronta para ser usada quando bem quisermos usar, queremos que assim esteja. No caso do microondas, nhemmm, não há muito o que se possa fazer. Sorry. Mas felizmente, a vida não é tão cruel quando se trata de navegadores web ⎼ web engineers, sim, estes podem ser bem cruéis, cuidado! (LOL)
Web Workers
A Web Workers API torna possível que um script rode em background, em uma thread separada da thread principal da aplicação web. Isto é fantástico, porque assim a thread principal, que é a responsável pela UI, fica livre para interagir com o usuário enquanto a thread do web worker executa seu trabalho custoso e potencialmente demorado.
The main thread is where a browser processes user events and paints. By default, the browser uses a single thread to run all the JavaScript in your page, as well as to perform layout, reflows, and garbage collection. This means that long-running JavaScript functions can block the thread, leading to an unresponsive page and a bad user experience. ⎼ Main thread, MDN Web Docs Glossary.
Figura 1: As diferentes threads da aplicação, dado o uso de web workers.
Há três tipos de workers:
Dedicated — são usados por apenas um único script;
Shared — podem ser usados por múltiplos scripts, que podem estar rodando em diferentes janelas, iframes, etc, desde que estejam no mesmo domínio. Naturalmente, estes são um pouco mais complexos que os dedicados;
Service — são fundamentalmente proxies, que se colocam entre a aplicação web, o navegador e a rede. O grande objetivo deles é criar aplicações que possam rodar offline (PWA), porque eles podem interceptar requisições de rede, lidar com falhas de rede, fazer cache de conteúdo, acessar push notifications, rodar tarefas em background, entre outras coisas.
Para brevidade deste post, vamos tratar apenas de workers dedicados. Em um futuro post, podemos explorar um dos outros dois tipos ⎼ ou quem sabe os dois.
Em termos práticos, um web worker é um objeto do tipo Worker, que recebe como argumento obrigatório de construção um script, que precisa obedecer à regra de mesma origem. Opcionalmente, você pode passar também um segundo argumento, um objeto options com três atributos do tipo string: type, credentials e name. (Nosso script downloader.js brinca com o atributo name. Você vai ver isso mais adiante, quando checar o projeto de exemplo. Oops! Spoiler. Urgh!)
Mas por uma questão de thread safety, workers não tem acesso às famosas variáveis globais window e document, porque não possuem acesso à DOM API, uma vez que a thread principal é quem é a responsável pela UI.
Figura 4: Workers não tem acesso a window e document.
Okay, muito bem. Mas espere. Hmmm. Como é que eu faço então quando preciso fazer alguma modificação na página atual, por exemplo, sei lá, esconder uma div ou mostrar uma imagem?
Ótima pergunta! E para respondê-la, vamos explorar um pouco a interação entre o script principal e um dado worker. Você vai ver que tudo vai ficar evidente daqui um pouquinho.
Um objeto Worker tem basicamente um método e dois eventos que nos interessam, no propósito desta discussão.
Figura 5: Instância de worker, do lado do script principal.
Agora, do lado do worker, vamos dar uma inspecionada na propriedade read-only self, que refere-se à instância do worker em si (repare na Figura 1 que “this” está undefined). O que nos importa deste lado é o seguinte:
Basicamente, a mesma coisa, né? Típico de um modelo do comunicação baseado em troca de mensagens.
Pois muito bem, com essas informações em mãos, você já deve ter deduzido como é que essa interação entre script principal e worker funciona, né?
Quando o script principal quer falar com o worker, ele lhe envia uma mensagem usando o método postMessage(). O worker, por sua vez, quando recebe uma mensagem do script principal, a consome através do evento onmessage. E vice-versa.
Figura 7: Os eventos de erro dispensam explicações.
O evento onmessage é onde o heavy lifting de fato acontece. Pode ser uma computação custosa, um pré-processamento, um cacheamento de recursos, ou qualquer outra operação potencialmente demorada que pode bloquear a UI e dar aquela sensação de travamento na página web.
Cache API
A Cache API oferece uma interface para o mecanismo de persistência do browser específico para pares de Request/Response, que ficam disponíveis tanto em escopo de janela quanto de worker.
Esse tipo de persistência é o que chamamos de “long lived memory” e sua implementação é totalmente dependente do navegador. Aliás, aproveitando o assunto “dependente do navegador”, a Dona Prudência recomenda que você teste sua feature pelo menos nos principais navegadores onde ela deve ser suportada, especialmente, quando se tratar de dispositivos móveis. Do contrário, há uma grande chance do Senhor Lamento lhe fazer uma visita, digamos, não muito amigável. Voltemos ao lance do storage agora.
Além da API de Cache, há ainda alguns outros serviços que usam a Storage API, mecanismo de persistência de dados do navegador, como por exemplo:
Figura 8: Quota de armazenamento de uma aplicação web rodando no Chrome, em um desktop Windows.
Agora, quanto ao tamanho desse espaço disponível, a documentação MDN Web Docs começa dizendo mais ou menos o seguinte: “olha só, pessoal, existem diversas maneiras do browser armazenar dados localmente e o processo pelo qual ele faz isso ⎼ calcular quanto espaço usar e quando liberar ⎼ é complicado e varia de browser para browser”. Super esclarecedor. Mas depois ela fica menos vaga e dá algumas informações mais concretas, que vou resumir aqui:
A espaço máximo é dinâmico, baseado no espaço livre em disco;
O limite global é essencialmente 50% do total livre do disco;
Quando o espaço livre é atingido, acontece um processo de limpeza baseado na origem, a.k.a.origin eviction;
A limpeza é por origem ⎼ não é seletivo quanto ao conteúdo “dentro” da origem ⎼, para evitar problemas de inconsistência.;
Há também um group limit, que é de 20% do limite global, sendo que o mínimo é 10 MB e o máximo 2 GB (de um modo geral, o group limit é por domínio raíz e a origem por domínio absoluto);
Se você quiser se inteirar um pouco mais sobre essa questão de espaço disponível para armazenamento e tudo mais, o que eu lhe encorajo a fazer, para poder planejar sua estratégia de origem de conteúdo, recomendo este post: Estimating Available Storage Space. Ele já é um tanto velhinho, para “os padrões da interwebs”, mas vale a pena.
Figura 9: TL;DR script para estimar espaço disponível para persistência.
Que tal se aproveitarmos o ensejo do snippet da Figura 9 e partirmos para ver um pouco de código daqui em diante?
Uma aplicação web pode ter mais de um cache “nomeado” (o que pode ser interessante para agrupar conteúdo baseado em algum critério) e você precisa abri-lo antes de poder usá-lo. Caso ainda não exista um cache com o nome que você especificou ao tentar abri-lo, um novo será criado automaticamente.
Figura 10: Criação “automática” de um cache chamado “blah”, que não existia até então.
Como você deve ter percebido na Figura 10, para ter acesso à Cache API, o ponto de entrada é a propriedade read-only global caches, que é do tipo CacheStorage, e oferece alguns métodos fundamentais para seu uso típico.
Figura 11: O ponto de entrada para o uso da Cache API e seus métodos.
Os métodos da CacheStore são todos assíncronos e retornam uma Promise. No caso do método open(), ela resolve para o objeto Cache que se está querendo usar, pronto para uso.
Figura 12: Abrindo para uso um dos caches da aplicação.
Uma vez que você tenha um objeto Cache na mão, você pode então procurar por uma determinada URL. Para fazer isso, você usa o método match(), cujo primeiro argumento é uma URL ou um objeto Request, e resolve para um objeto Response. Esse método tem ainda um segundo argumento, com algumas opções interessantes para configuração dos critérios da busca.
Okay. Aqui tem um detalhe que acho que vale a pena comentar.
Há pouco, eu disse que uma aplicação pode ter mais de um cache “nomeado”, não foi? Pois é. E eu também disse que você precisa abri-lo antes de usá-lo, né? Então, nhmmm, isso é semi-verdade.
Em vez de usar caches.open(“assets”) para abri-lo e depois cache.match(“https://blah.com/tldr.png”) para recuperar o response cacheado, você pode simplesmente usar caches.match(“https://blah.com/tldr.png”). A diferença, pegando este atalho, é que a busca não é feita “em um cache específico”, mas em todos. Ou seja, há um custo extra na busca.
Figura 13: Atalho para obter um objeto response do cache.
Tem mais uma coisa que acho importante comentar, que é o seguinte: diferente de alguns mecanismos de cache onde você define o tempo de expiração de um objeto e o mecanismo de cache faz o resto, aqui, você tem que deletar um objeto quando quiser revogá-lo. O mesmo vale para mantê-lo atualizado ⎼ isso é por sua conta.
Com esse recurso, você pode cachear retornos de API que não mudam com tanta frequência, imagens/vídeos de um slideshow agendados para rodar mesmo quando a rede estiver offline ⎼ pense em uma computação prévia disso, baseada no escalonamento de cada imagem ou vídeo.
Ah, sim, claro! Que bom que você notou. A interface desse projeto é super “vintage”. Thanks for asking me.
Figura 14: Yeah, this is me. Annnd the code you want me to show you.
Eu recomendo bastante que você, além de ler o código, também baixe o código na sua máquina e bote a aplicação para rodar, faça debug dela e observe o que acontece no console e nas abas network e application. Isso vai te ajudar a entender todo o mecanismo discutido até aqui. Afinal de contas, trata-se de um exemplo educativo, então, você tem que botar as mãos nele e experimentar por conta própria.
Tendo dúvidas, não hesite em me contactar.
Conclusão
A ideia desse post foi explorar um pouco dois recursos oferecidos pelos navegadores modernos, Web Workers e Cache API, para melhorar a experiência dos usuários humanos das suas aplicações, que não suportam esperar mais do que 3 segundos pelo carregamento de uma página web. E além disso, esses recursos também podem ser usados para criar aplicações que sejam tolerantes a indisponibilidades de rede e funcionem offline.
Seja você um jovem estudante de programação, uma experiente executiva de engenharia, ou qualquer coisa nesse continuum, o assunto desenvolvimento de carreira certamente aparece em seu círculo de discussões com certa frequência.
Não é por menos. Em geral, temos uma tendência natural de não nos satisfazermos com o que temos no momento, mas estamos sempre pensando no próximo. Não, não estou me referindo ao nosso análogo humano, ao nosso semelhante. Estou me referindo ao próximo momento ⎼ onde está, potencialmente, a nossa próxima conquista, o nosso próximo patamar, etc. Por um lado, isso nos rouba da apreciação do momento, do saborear a recém conquista. Por outro lado, isso nos move para frente, para o ainda inalcançado. Progresso! ⎼ alguém gritou.
Todo progresso tem seu custo. Claro, tem muitos benefícios também. Óbvio. Um dos custos do progresso é que você precisa se desapegar do passado, se empenhar no presente e mirar no futuro. O que não significa descartar o passado. Muito pelo contrário, o progresso pressupõe um incremento sobre patamares anteriores. Digamos, depois de 4 anos de treino pesado para chegar às Olimpíadas, o que acontece no dia imediatamente após voltar para casa com a medalha de ouro? O início dos treinos para a próxima Olimpíada, porque a medalha de ouro desta Olimpíada não garante sequer um bronze na próxima. Só o trabalho duro, sobre as bases construídas até então, praticando frequentemente os fundamentos, corrigindo as deficiências, adquirindo novas habilidades, etc, é que se pode garantir “a chance” de repetir a conquista.
Sim, pois é, a chance. Porque assim como você, os outros competidores provavelmente farão o mesmo, especialmente motivados por não terem conquistado o ouro nesta Olimpíada. E pode ser que na próxima, um deles traga para casa o ouro e não você. Lide com isso. Porque nem sempre você voltará para casa com o ouro. Mas tudo bem. Porque o progresso não tem compromisso com os seus sentimentos. O progresso não te chama “meu floquinho de neve”, ou qualquer coisa bem mais tupiniquim do que isso.
O ponto aqui é: nós não controlamos todas as variáveis do Universo. Sorry. Nós controlamos umas poucas variáveis da nossa própria vida ⎼ e é nisso que precisamos nos concentrar, não importa o quão pequeno isso possa parecer à primeira vista. Na dúvida, lembre-se da metáfora do efeito borboleta.
Tendo dito isso, gostaria de compartilhar, a seguir, o que tem sido para mim algumas das principais variáveis sob o meu controle, que tenho manipulado ao longo dos meus mais de 20 anos de carreira em engenharia de software, seja liderando ou executando.
DISCLAIMER: Altamente opinionated.
1. Motivação
Seja você mesmo sua própria motivação.
Há pessoas que precisam de motivações externas para progredirem em suas carreiras. Enquanto estão recebendo louros da sua líder, dos colegas de equipe, da comunidade de software, dos professores da faculdade, ou recebendo o salário que acham que merecem, ou o bônus, elas estão correndo atrás de conhecimento e de aperfeiçoamento técnico. Mas no momento que lhes falta essa motivação externa, elas estacionam, sentem-se desmotivadas a estudar, a aprender coisas novas, a refinar seus conhecimentos adquiridos até então.
Não me entenda mal, eu gosto de dinheiro e louros tanto quanto você. Mas uma coisa que aprendi muito cedo é que nem sempre vai haver quem me elogie ou me pague o quanto acho que mereço. Muitas vezes, isso vai me deixar chateado ⎼ e honestamente, já tive mais noites mal dormidas por isso do que gostaria de admitir ⎼, mas esse não é o meu drive de progresso técnico-intelectual. O meu drive de progresso está em meu próprio desejo de aprender, de saber mais, de descobrir coisas que ainda não sei. Aprender pelo fim de aprender é algo que me dá prazer. Então, o que aprendo, aprendo para mim mesmo.
Motivação externa vem e vai. Mas o que você aprende permanece. E o saber, por si só, sempre vai trazer consigo novas oportunidades, mais cedo ou mais tarde.
2. Leia
Uma das minhas principais formas de aprender é a leitura. Tem algo na palavra escrita que me fascina, que me envolve, que de algum modo encontra uma via expressa na minha massa cinzenta.
A leitura exercita a nossa mente de uma maneira singular. Bem, ao menos comigo é assim (N=1).
Livros, blog posts, artigos científicos, papers, qualquer coisa. Eu leio de tudo, todos os dias. Não apenas de programação, aliás.
Quando comecei a aprender programação, em 1997, eu passei muitas noites em claro lendo livros de programação de Clipper, Delphi, C++, Java, JavaScript, Perl, ASP, etc, e fuçando no computador, testando os exemplos, explorando os conceitos e tudo mais. Eu gastava boa parte do que ganhava na Tempo Real e Livraria Cultura; e foi assim por muitos anos.
As “pessoas técnicas” que mais admiro são pessoas dadas à leitura. As pessoas mais brilhantes e produtivas com quem já trabalhei são pessoas que cultivam este hábito.
Portanto, se você quer progredir em sua carreira de engenharia de software, seja liderando ou executando, arranje tempo para ler bons livros de programação, de arquitetura de software, de conceitos fundamentais de construção, teste e operação de sistemas de software, e não somente blogs de “how to”.
Blog posts, como os que publicamos aqui, são fantásticos para ter uma boa ideia sobre um assunto, mas para ir a fundo mesmo, você vai precisar recorrer aos livros. E como regra geral, prefira aqueles que são mais conceituais e menos “faça isso ou aquilo nesse framework da moda”.
O ser humano tem uma capacidade formidável de aprender observando ⎼ haja vista as crianças, em seus primeiros anos de vida. De algum modo, ao longo da vida, vamos nos afastando do aprendizado pela observação à medida que vamos dominando outros meios de aprendizado. Mas a observação é um meio poderoso de aprendizado.
Há desenvolvedores que ao entrarem em um novo projeto e começarem a lidar com uma nova base de código são incapazes de “observar” e “extrair padrões” de suas observações. Me frustra bastante quando tenho que explicar para alguém um padrão estabelecido na base de código, que poderia ser facilmente inferido a partir da observação cuidadosa do código existente. O mesmo acontece em relação a nomes de servidores, serviços e instâncias disso e daquilo.
Não me entenda mal, eu sou 100% a favor de guias de estilo e documentações, mas precisaríamos de muito menos formalização se gastássemos um pouco mais de tempo observando “com intenção” antes de sairmos codando.
Uma coisa que gosto muito de fazer quando estou aprendendo uma nova linguagem de programação, por exemplo, é observar um número de projetos open source escritos na tal linguagem, para tentar inferir padrões, tentar entender como as pessoas resolvem certos problemas comuns de programação e design de software naquela linguagem. Para mim, essa é uma ferramenta inestimável de aprendizado.
Isso evita, por exemplo, o famoso tentar “programar Java em Go” ou qualquer variação disso.
Já em um contexto totalmente diferente, nada a ver com códigos e servidores, a observação é super importante quando você está na liderança de um time.
No grande esquema das coisas, um programador é um programador; uma arquiteta de software é uma arquiteta de software. Mas quando você sai do campo da teoria e aterriza em um time de engenharia composto por pessoas, a realidade não é tão simétrica assim. As pessoas são diferentes umas das outras, naturalmente. Muito embora, elas compartilhem certos atributos e comportamentos, o ponto de partida e jornada de cada uma delas pode ser completamente diferente.
Por isso, você que é líder, é muito importante observar as pessoas do seu time. Observar como elas se comportam em reuniões diárias de alinhamento (que devem servir não como reuniões de status report, mas de estabelecimento de contexto, para que fiquem todos na mesma página), em reuniões de planejamento, em happy hours, em all hands, em 1–1, e quando estão sozinhas realizando suas atividades individuais, só para citar algumas situações. Isso é importante para você “sacar” como elas operam no dia a dia delas, como aprendem, como lidam com problemas, como se percebem valorizadas por você e pelos seus pares, e por aí vai. Isso vai lhe ajudar a lidar com essas pessoas, de modo a potencializar as virtudes delas e ajudá-las com seus demônios manifestos no trabalho.
Você já observou como as pessoas afetam o dia a dia umas das outras em seu time? A Maria gosta de trabalhar com o José? O José faz entregas que afetam positivamente o trabalho da Maria? A Maria contribui para o aprendizado do José? E a Joana, sua última contratação, se encaixou bem no time? Ela foi bem aceita e acolhida pelo time?
Como líder, o seu trabalho é ajudar as pessoas do seu time a exercerem seu papel de modo excepcional. Observar as pessoas do seu time como indivíduos é um bom ponto de partida.
Na minha carreira, observei muitas pessoas ao longo de todos esses anos. Observei colegas de trabalho, chefes, pessoas da comunidade de software, professores, etc. Observei como elas escreviam código, como elas debugavam um problema em produção, como elas priorizavam tarefas, como elas resolviam uma crise, como elas lideravam, como elas tratavam as pessoas que trabalhavam com elas e para elas. Vi muito absurdo, vi muita coisa inspiradora, aprendi alguma coisa com cada uma delas.
4. Reflita
Pare por um minuto e pense no que leu até agora. Faz sentido essa discussão? Há algum sentido no que você leu até aqui? Pense um pouco. Reflita sobre isso.
Muitas vezes na ânsia de realizar, realizar, realizar; fazer acontecer, voar, etc e tal ⎼ todos aqueles jargões típicos das redes sociais e do startupês ⎼, a gente se priva de uma das maiores dádivas de ser humano: a capacidade de refletir e ponderar sobre as coisas.
Em uma posição de liderança, você precisa tomar decisões que vão afetar não somente a sua vida e o seu trabalho, mas em especial, a vida e o trabalho de um número de pessoas as quais você lidera, e isso não é algo que se deva fazer sem a devida reflexão. Desde a qualidade do café que você oferece no escritório até a proficiência dos pares.
Se você “economiza” no café e oferece um café “ruim” para o seu time, como você acha que eles vão se perceber? Será que eles vão se sentir valorizados na empresa? Uma equipe se sente tão apreciada quanto o café que você oferece a elas.
Outra coisa: os pares. Reflita sobre isso. Ter colegas de trabalho igualmente proficientes, cada qual correspondendo ao nível de aptidão esperado para o trabalho à mão, é fundamental para criar um ambiente de alta performance, colaborativo, maduro, onde as pessoas se sentem motivadas a dar o seu melhor, dia após dia e a estimular umas às outras em direção ao progresso. Alguns dizem que ter colegas de trabalho medíocres é pior para a satisfação de um indivíduo no trabalho do que café ruim e salário defasado.
Mais uma última coisa: quando as pessoas com frequência realizam tarefas que estão aquém da proficiência delas, elas tendem a ficar desmotivadas. As pessoas no seu time estão realizando tarefas adequadas ao nível de proficiência delas? Elas se sentem desafiadas nas tarefas que realizam? Elas exercem algum tipo de autonomia para decidir como realizar essas tarefas? Pode ser que não haja espaço para elas fazerem o que gostariam de fazer e, neste caso, a melhor alternativa mesmo seria deixá-las ir. Mas pode ser que realmente exista espaço, só que você, líder, não libera, não dá autonomia às pessoas, microgerencia, e com isso, impede que elas cresçam em escopo e se sintam desafiadas. Observar e conversar com as pessoas ajuda muito nisso, mas se desprender é fundamental.
Já partindo para um território mais técnico, enquanto arquiteto de sistemas, engenheira de software, programador de aplicativos, nós frequentemente precisamos tomar decisões que vão afetar o prazo de entrega do produto que estamos desenvolvendo, sua qualidade, facilidade de manutenção e operação ao longo de seu tempo de vida em produção. Nossas decisões neste âmbito têm impacto direto no custo de construção e de manutenção da solução por anos a fio. Pense nisso por um minuto.
Quando nós consideramos usar aquela lib “maneirinha”, aquele framework “que tá tudo mundo usando”, aquela linguagem “que vai dominar o mercado”, em um projeto crítico, que tem prazo de entrega e budget apertado, nós estamos colocando muita coisa em jogo. Isso requer reflexão.
Em geral, a pergunta que me faço nessas horas é “o que o projeto ganha em NÃO usar este x-bacanudo em favor daquele feijão-com-arroz já bem estabelecido?”
Só tome cuidado para não ficar paralizado, pensando, pensando, pensando, sem sair do lugar. É importante que você desenvolva certa cadência “reflexão vs execução”, evitando tomar decisões agora, que poderiam ser tomadas daqui há 2 meses, priorizando decisões e abraçando a ideia de “bom o bastante” para o momento. Nada é tão bom que não possa ser revisado mais adiante.
5. Discuta
Isso passa muito pela questão “ter bons pares no trabalho”. Já houve ocasiões ao longo da minha carreira, que não tive ninguém no trabalho com quem trocar ideias mais profundas sobre design de software, arquitetura de sistemas, linguagens de programação, boas práticas de liderança e coisas desse universo. Maus tempos, eu diria.
Os períodos mais satisfatórios da minha carreira aconteceram, coincidentemente ou não, quando eu tinha alguns tantos pares que eram muito, mas muito, bons técnicos e excelentes líderes.
É muito importante você ter pessoas com quem trocar ideias. Pessoas com quem você possa argumentar em favor de uma ideia, para no final, ver o quanto ela era uma péssima ideia ⎼ ou não mínimo, não tão boa assim. Pessoas que nem sempre concordam com você, que desafiam sua visão de mundo e de solução de problemas complexos.
Recomendo muito que você tenha uma rede de pessoas brilhantes com quem possa trocar ideias.
Já no seu time, líder, dê espaço para as pessoas falarem. Converse com elas. Mas esteja genuinamente disposto a ouvir. Aliás, ouça mais do que você fala. E por favor, estimule a sinceridade. Deixe que sejam 100% francas com você. Alguém precisa dizer que o rei está nú.
Agora, não se engane: estimular a discussão, por vezes, pode acabar estimulando bikeshedding, porque as pessoas podem acabar confundindo a liberdade de discussão com a trivialidade atribuída às discussões. Quero dizer, não é porque há liberdade para se discutir qualquer coisa, que vamos gastar um amontoado de tempo discutindo coisas banais, ou que, ao menos no dado momento e fórum, não são importantes. Portanto, tenha isso em mente e tente priorizar as discussões, especialmente, quando se tratar de reuniões formais, que precisem conciliar agenda de muitas pessoas. O bom senso é sempre bem vindo.
Uma dica que eu dou, então, é ter pelo menos duas abordagens de discussão: uma bem objetiva, pautada, focada em resolver problemas priorizados e bem definidos; e a outra mais passiva, onde você faz perguntas “abertas” e permite que as pessoas falem livremente, se expressem de maneira franca, sem serem interrompidas, mesmo que, ao seu ver, elas estejam falando algum absurdo. Não tem problema, deixe que falem. Pode ser que só estejam falando besteira, ao seu ver, porque lhes falta de contexto. Dar a elas contexto é sua responsabilidade, líder.
Conclusão
Não controlamos todas as variáveis do Universo. Ainda bem, por que isso sim seria a verdadeira definição de caos! (LOL) Mas tudo bem, com as poucas variáveis que controlamos, já podemos fazer grandes mudanças em nossas próprias vidas e ajudar outros a manipularem suas próprias variáveis e serem suas próprias mudanças.
Pessoas que se auto motivam, que são dadas à leitura, que observam com intenção, que refletem sobre aquilo que leem, ouvem, veem e sentem, e que estão sempre prontas para discutir e trocar ideias, em geral, são pessoas que buscam seu próprio crescimento, que traçam seu próprio caminho profissional e não dependem de planos de carreira e baby sittings de onde trabalham.
Se você quer realmente desenvolver a sua carreira, recomendo muito que aprenda a fazer isso.
Há cerca de um mês, tive o prazer de apresentar um webinar da Pricefy, falando sobre programação assíncrona com C# .NET. Na ocasião, apresentei conceitos fundamentais de multithreading, I/O assíncrono, Task-based Asynchronous Programming, mostrei como async/await funciona por baixo dos panos e finalizei com código (é lógico!), mostrando exemplos de mau uso de async/await e como usar isso do jeito certo. O conteúdo está bem didático, tenho certeza que mesmo quem não é da turma do C# pode aprender uma coisa ou duas.
Durante o webinar, fiz questão de deixar claro que há uma distinção entre o que são tarefas assíncronas e o que são tarefas paralelas. Muito embora, sejam frequentemente usadas em conversas corriqueiras como sendo a mesma coisa, elas não são a mesma coisa.
Obviamente que uma discussão exaustiva sobre o assunto está fora da agenda deste post. Mas vou fazer uma nano desambiguação aqui, para então seguir com o assunto alvo deste post.
Consideramos paralelismo quando temos uma tarefa que leva um certo tempo para ser concluída e desejamos completá-la em menos tempo. Para isso, o requisito basilar é que a tal tarefa seja passível de ser dividida em múltiplos pedaços iguais (ou bem próximo disso) e que se tenha um número de unidades de trabalho de igual capacidade, para que possam trabalhar ao mesmo tempo e com equivalente desempenho.
Um exemplo cotidiano de paralelismo seria dividir a tarefa de descascar 3 kg de batatas entre três pessoas de igual habilidade (e força de vontade!). Digamos que você sozinho leve 3 horas para concluir a tarefa. Okay, o problema é que o jantar é daqui há 1 hora e meia. O que fazer? Dividir a tarefa com aqueles dois amigos que estão sentados no sofá, sem fazer nada, enquanto você prepara tudo sozinho? Sim, essa é uma ideia. Se os dois tiverem a mesma habilidade de descascar batatas que você tem, em aproximadamente 1 hora a tarefa estará concluída e você poderá partir para a próxima ⎼ assar, cozer, fritar, ou o que quer que seja.
Em termos de software, o princípio é o mesmo. Digamos que você tenha, por exemplo, uma lista com 300 itens e tenha que realizar uma determinada operação em cada um deles. Se você tiver três CPUs em seu computador, você pode dividir a lista em três e processar ⅓ em cada CPU.
“Most modern CPUs are implemented on integrated circuit (IC) microprocessors, with one or more CPUs on a single metal-oxide-semiconductor (MOS) IC chip. Microprocessors chips with multiple CPUs are multi-core processors. The individual physical CPUs, processor cores, can also be multithreaded to create additional virtual or logical CPUs.” — Wikipedia.
Note que eu disse “CPU” e não “thread”. Isso porque o paralelismo “de verdade” é obtido com múltiplas CPUs executando threads ao mesmo tempo e não com múltiplas threads sendo escalonadas por uma única CPU. Com múltiplas threads em uma única CPU, temos o que é conhecido como multitarefas “virtualmente simultâneas”.
Por exemplo, quando eu digito algo no teclado do meu computador e como amendoins “ao mesmo tempo”, no grande esquema das coisas, digamos, em uma janela de 10 minutos, alguém pode dizer que estou comendo amendoins ao mesmo tempo em que digito coisas no computador; mas na real, encurtando essa janela de tempo, é possível ver que eu não faço as duas coisas exatamente ao mesmo tempo, mas sim, intercaladamente, mudando de uma tarefa para a outra a cada certo intervalo.
É basicamente assim que as threads funcionam: elas são como “unidades de processamento virtuais”, que uma CPU executa com exclusividade por 30 milissegundos cada. Humanamente falando, imagino que seja impossível perceber essa mudança de contexto; por isso, tudo parece realmente simultâneo para nós.
Assíncrono vs Paralelo
Já no caso da assincronicidade, consideramos assíncrono aquilo que não vai acontecer do início ao fim exatamente agora, que pode ter um curso intermitente, e não queremos ficar sem fazer nada enquanto esperamos por sua conclusão, que acontecerá em algum momento futuro. Isso é tipicamente comum com operações de I/O.
Operações de I/O não dependem apenas de software, obviamente, mas invariavelmente de dispositivos de I/O (a.k.a. hardware), que de algum modo compõe ou complementam um computador, cada qual com seu modo de funcionar, seu tempo de resposta e outras particularidades quaisqueres. Alguns dos dispositivos de I/O mais comuns são: HD, monitor de vídeo, impressora, USB, webcam e interface de rede. Qualquer programa de computador que valha seu peso em sal executa alguma operação de I/O ⎼ mostrar “hello world” em uma tela, salvar um texto qualquer em um arquivo, iniciar um socket de rede, enviar um e-mail, etc.
Voltando à cozinha para mais um exemplo, digamos que o jantar de hoje seja macarrão à bolonhesa e salada verde com tomates cerejas e cebola. Como poderia acontecer a preparação desse cardápio? Bom, eu poderia fazer uma coisa de cada vez, de modo sequencial. Ou poderia tentar otimizar um pouco meu tempo, minimizando o tempo que fico sem fazer nada, aqui e ali, esperando por algum “output” qualquer.
Eu começo colocando uma panela de água para ferver, onde vou cozer o macarrão. Enquanto ela não ferve, eu corto cebola, alho e bacon para refogar a carne moída;
Terminando, a tarefa de pré-preparo, sequencialmente, enquanto ainda espero a água para o macarrão chegar à fervura, começo então a preparar a carne moída ⎼ refogo, coloco temperos diversos, extrato de tomate e deixo cozer em fogo médio;
Vejo que a água começou a ferver, então, acrescento um tanto de sal e ponho o macarrão para cozer. Okay, agora, enquanto o macarrão cozinha por aproximadamente 8–10 minutos e a carne moída também está cozendo, apurando o sabor, o que eu faço? Sento e espero? Não! Ainda tenho que preparar a sala;
Lavo as folhas verdes, os tomates, corto a cebola, junto tudo em uma saladeira (trriiimmm!!!) ouço o alarme indicando que o macarrão está cozido e é hora de escorrê-lo rapidamente, mesmo que tenha que parar o preparo da salada, momentaneamente, afinal de contas, só falta temperar e isso não é algo tão crítico, pode acontecer daqui um pouco; já o macarrão, precisa ser escorrido agora!
Escorro o macarrão, coloco em uma travessa de macarronada, despejo a carne moída por cima, misturo cuidadosamente e finalizo ralando uma generosa quantidade de queijo parmesão por cima;
Levo a travessa de macarronada para a mesa de jantar, volto à cozinha, tempero a salada rapidamente e levo para mesa também;
Tá na mesa, pessoalll!!!
Vê como tudo aconteceu de modo predominantemente assíncrono, porque cada preparo teve seu tempo e sua prioridade? Tudo aconteceu de modo intercalado. Foram 40 minutos intensos, sem ficar um minuto parado sem fazer nada, mas aproveitei muito melhor o meu tempo.
É basicamente assim que funcionam as operações de I/O assíncronas: uma única thread é capaz de despachar milhares de operações de leitura ou escrita para os diversos dispositivos de hardware de um computador, conforme as requisições vão chegando; e enquanto as respostas dos dispositivos não chegam, indicando que as operações foram bem sucedidas ou não, elas vão atendendo a outras requisições; e assim seguem, em um loop semi-infinito.
Por que uma thread ficaria parada, bloqueada, esperando pela resposta de uma escrita em um socket, que pode levar certo tempo, enquanto poderia estar escrevendo algo em um arquivo no disco rígido? Essa é a magia do I/O assíncrono in a nutshell. Depois, assista à minha talk no YouTube, que lá eu me aprofundo mais no assunto; não quero me repetir aqui.
Como você provavelmente já notou, tanto a abordagem paralela, quanto a assíncrona, são maneiras de se implementar concorrência em uma aplicação, cada qual com sua finalidade. A primeira, envolve threads de execução em múltiplas CPUs simultâneas; a segunda se baseia em máquinas de estado, futures e callbacks, executando possivelmente em uma única thread.
Espero que essa introdução tenha sido suficiente para ficarmos todos na mesma página.
Paralelismo está no menu hoje
O assunto da vez hoje é paralelismo com C#. E para continuar se aprofundando no assunto, uma visão de alto-nível da arquitetura de programação paralela oferecida pela plataforma .NET.
Eu acho importante começar com essa big picture, porque infelizmente, a plataforma .NET não ajuda muito com aquela distinção de assíncrono vs paralelo, que vimos há pouco. A razão disso é que a classe Task é o ponto de partida da Task Parallel Library (TPL) tanto para algoritmos assíncronos quanto para paralelos.
A documentação sobre Task-based Asynchronous Programming (TAP) define “task parallelism” como “uma ou mais tarefas independentes executando concorrentemente”, o que soa um pouco fora do que vimos há pouco.
Já a documentação sobre Parallel Programming in .NET (fonte do diagrama acima), por sua vez, diz que “muitos computadores pessoais e estações de trabalho têm vários núcleos de CPU que permitem que várias threads sejam executadas simultaneamente”, e então, conclui dizendo que “para aproveitar as vantagens do hardware, você pode paralelizar seu código para distribuir o trabalho entre vários processadores”. Isso faz mais sentido para mim.
Uma dica de ouro, que para mim ajuda bastante, é olhar para a classe Task sob a ótica daquilo que tenho a intenção de implementar.
Os membros .Result, .Wait(), .WaitAll(), .WaitAny() são bloqueantes (a.k.a. síncronos) e devem ser usados somente quando se tem a intenção de implementar paralelismo. Tarefas paralelas estão relacionadas ao que chamamos de CPU-bound e devem ser criadas usando preferencialmente os métodos .Run() e .Factory.StartNew();
Além da palavra-mágica await, usada para aguardar assíncronamente a conclusão de um método assíncrono (na prática, uma instância de Task ou Task<T>), os métodos .WhenAll() e .WhenAny(), que não são bloqueantes (a.k.a. assíncronos), devem ser usados quando a intenção for implementar assincronicidade. Tarefas assíncronas estão relacionadas ao que chamamos de I/O-bound.
A propósito, TaskCreationOptions.AttachedToParent pode ser usada na criação de uma tarefa paralela (estratégia “divide and conquer” / “parent & children”), mas não por uma tarefa assíncrona. Tarefas assíncronas, de certo modo, já criam sua própria “hierarquia” via await.
Okay, vamos focar em paralelismo a partir daqui e ver um pouco de código.
Colocando a mão na massa
Como vimos há pouco, tarefas paralelas vão bem para implementar processos que sejam CPU-bound; ou seja, que levam menos tempo para conclusão em função do número de CPUs disponíveis para particionamento/execução do trabalho.
Podemos dividir esse cenário em duas categorias de processamento:
Estático — data parallelism
Dinâmico — task parallelism
Processamento paralelo “estático”
Chamamos essa categoria de estática, porque se trata de iterar uma coleção de dados e aplicar um dado algoritmo em cada um de seus elementos. Para isso, a TPL nos oferece três métodos a partir da classe Parallel.
Repare nos parâmetros passados na invocação do método Parallel.For(), na linha 14. Além dos típicos limites inicial e final, há também uma Action<int, ParallelLoopState>, que provê o índice da iteração atual e um objeto com o estado do loop. É a partir deste objeto de estado que solicitamos um “break” no loop.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Uma outra coisa a se notar é o seguinte: diferente de um loop for clássico, que acontece sequencialmente, este Parallel.For() pode ter sido escalonado para rodar em múltiplos processadores simultaneamente; portanto, um break não é imediato, evitando que a próxima iteração aconteça. Pelo contrário, é bem provável que um número de iterações tenham sido iniciadas em um breve momento anterior ao .Break() ser invocado. É por isso que, na linha 19, precisamos checar se podemos ou não continuar a iteração atual.
E finalmente, note que na linha 32 há um lock da variável random. Isso é necessário por se tratar de um processo paralelo, que vai potencialmente mutar essa variável concorrentemente ao longo das iterações. Idealmente, você vai evitar esse tipo de cenário, porque onde há lock, há contenção; e onde há contenção, há tempo despendido esperando. Você não quer isso, mas às vezes é preciso.
— A little break here —
Acho que esse é o momento ideal para dizer que paralelismo pode criar situações de concorrência, intencional ou acidentalmente, dependendo do que você está implementando — porque programação paralela é um tipo de multithreading; e multithreading é um tipo de concorrência.
Se você ficou com dúvidas sobre isso, se ficou confuso com a terminologia, se acha que é tudo a mesma coisa, ou algo assim, tudo bem, não se desespere. Eu sei que, como acontece com assincronicidade e paralelismo, concorrência e paralelismo também são confundidos o tempo todo.
O artigo da Wikipedia sobre concorrência (em inglês) traz um ótimo resumo do Rob Pike, que distingue bem uma coisa da outra: “Concurrency is the composition of independently executing computations, and concurrency is not parallelism: concurrency is about dealing with lots of things at once but parallelism is about doing lots of things at once. Concurrency is about structure, parallelism is about execution, concurrency provides a way to structure a solution to solve a problem that may (but not necessarily) be parallelizable.”
Se tiver um tempo extra, recomendo que você veja a apresentação do Rob Pike, Concurrency is not Parallelism, para ter uma introdução amigável ao assunto.
Semelhantemente ao que se pode fazer com um loop foreach, aqui, Parallel.ForEach() está recebendo um IEnumerable<int> provido por um generator (a.k.a.yield return). Além deste parâmetro, há ainda outros dois: um com opções de configuração de paralelismo e uma Action<int, ParallelLoopState, long>, que pode ser usada como no exemplo anterior.
O ponto de destaque neste exemplo vai para a linha 29, onde é definido um CancellationToken para o loop. Naturalmente, o objetivo do CancellationToken é sinalizar o cancelamento de um processo que está em curso. E neste caso, o cancelamento ocorre na linha 18, depois de um intervalo randômico ⎼ to spice it up.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Este é um pattern bastante comum na plataforma .NET, que você já deve estar bem acostumado, pois se vê isso por toda parte da biblioteca padrão.
3. Invoke() ⎼ neste caso, a coleção iterada é de algoritmos
Este caso é um pouco diferente dos dois anteriores. Nos casos anteriores, o problema que você estava querendo resolver era o seguinte: você tinha uma coleção de itens sobre os quais você queria aplicar um dado algoritmo, e para fazer isso o mais rápido possível, você queria tirar proveito do número de CPUs disponíveis e escalonar o trabalho entre elas.
Agora, neste caso, o problema é que você tem um número de algoritmos para executar (independentes uns dos outros, de preferência) e gostaria de fazer isso o mais rápido possível. A solução, no entanto, é essencialmente a mesma.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Um bônus no código acima, que não tem exatamente a ver com a questão do .Invoke(), mas que é super interessante e vale a pena comentar, é o método .AsParallel() sendo invocado no long[], na linha 13. Este método é parte da chamada Parallel LINQ (PLINQ), que torna possível a paralelização de queries LINQ.
Como você já deve imaginar, o que a PLINQ faz é particionar a coleção em um número de segmentos, e então, executar a query em worker threads separadas, em paralelo, usando os processadores disponíveis.
A propósito, assim como os dois métodos anteriores, .Invoke() também suporta CancellationToken via ParallelOptions.
Processamento paralelo “dinâmico”
Chamamos essa categoria de dinâmica, porque não se trata de iterar em uma coleção e aplicar um determinado algoritmo; também não se trata de invocar uma lista de métodos em paralelo. Na verdade, trata-se de iniciar uma nova Task (ou mais de uma), que vai executar um processo custoso em uma worker thread, em paralelo, se possível, e poderá iniciar outras Tasks “filhas” a partir dela, criando uma hierarquia, onde a tarefa mãe só será concluída quando suas filhas tiverem concluído.
Inicia, se divide, trabalha, converge e finaliza.
Essa é a uma categoria de paralelismo em que, questões como: quantas tarefas mães, quantas tarefas filhas, que processos cada uma delas realiza, em que circunstâncias, em que ordem, etc, etc, etc, são todas respondidas em runtime, de acordo com as regras xpto de cada caso de uso. Daí referir-se a ela como dinâmica.
Os métodos da classe Parallel e a PLINQ são super amigáveis, convenientes, e você deve tentar usar sempre que possível. Mas quando o problema for um tanto mais flexível, dependente de informações conhecidas somente em runtime, o negócio é partir para Task. Por exemplo, você precisa percorrer uma estrutura de árvore e, dependendo do nó, executar um processo ou outro.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Note que o exemplo acima usa o método Task.Factory.StartNew(), para criar e disparar a execução de instâncias de Task, e não o famoso Task.Run(), que estamos bem acostumados a usar, quando estruturamos aplicações para lidar com problemas de modo concorrente.
O caso é que, o método .Run(), na real, nada mais é do que uma maneira conveniente de invocar.StartNew() com parâmetros “padrões” (veja o fronte dele aqui). E como você já deve imaginar a essa altura do campeonato, é justamente por conta desses parâmetros “padrões” que ele não atende aos requisitos do exemplo acima. Bem, para ser mais específico, estou me referindo ao parâmetro TaskCreationOptions.DenyChildAttach, que nos impede de ter tarefas filhas. Quer testar isso? Substitua .StartNew() por .Run() na linha 12, ou então, o parâmetro TaskCreationOptions.None por TaskCreationOptions.DenyChildAttach, na linha 15, e veja o que acontece ⎼ repare bem na ordem das saídas de console.
Viu?
A regra então é: sempre que for criar e disparar a execução de uma Task, priorize .Run(), a menos que o caso que você vai implementar peça por parâmetros específicos, diferentes dos padrões. Nestas circunstâncias, use .StartNew() e configure a gosto.
[Para ser mais correto com a informação que estou entregando, eu tenho que dizer que, nem o método .Run(), nem o método .StartNew(), “disparam” a execução de uma Task. O que eles fazem, na verdade, é “colocar a Task na fila de execução do ThreadPool, através de um TaskScheduler”. Veja que a própria classe Task tem uma propriedade Status que ajuda a entender seu o ciclo de vida.]
Dica #1 ⎼ Long Running Tasks
Podemos dizer que uma Task é long-running quando ela permanece rodando por minutos, horas, dias, etc. Ou seja, não é uma tarefa de alguns poucos segundos de duração. Para isso, há a opção TaskCreationOptions.LongRunning, que pode ser passada para o método .StartNew().
O que essa opção faz é sinalizar ao TaskScheduler que se trata de um caso de oversubscription, dando a chance do TaskScheduler se precaver contra um fenômeno conhecido como “thread starvation”. Para tanto, duas ações são possíveis ao TaskScheduler: (1) criar mais threads do que o número de CPUs disponíveis; (2) criar uma thread adicional dedicada à Task, para que assim, ela não engargale o fluxo natural de trabalho das worker threads do ThreadPool.
Até aí, tudo bem. Problema resolvido. Espere. Mesmo?
Tarefas com corpo async, ou seja, que seu delegate await por outras tarefas, por si só, naturalmente, já possuem um fluxo de execução escalonado de acordo com sua máquina de estado. Portanto, elas não consomem uma mesma thread por muito tempo; cada passo da máquina de estado pode ser executado em uma thread diferente.
Se você não sabe do que estou falando, veja a minha talk.
O que fazer então? A menos que seu processo long-running não use await, não aguarde a execução de nenhuma Task, seja lá de que maneira, esqueça a opção TaskCreationOptions.LongRunning. Use .Run() e deixe que o TaskScheduler faça seu trabalho autonomamente ⎼ em raros casos ele realmente precisa de “dicas”.
Dica #2 ⎼ Exceções
Sim, elas existem e uma hora ou outra vão ocorrer. Lide com isso. Quero dizer, literalmente!
Quando você estiver trabalhando com tarefas aninhadas, parent & children, como no exemplo que vimos há pouco, quando ocorrer uma exceção, você vai receber uma AggregateException borbulhando. Não importa se você await ou .Wait() a Task, uma AggregateException é o que você vai ter. Sendo assim, muito do que eu falo sobre o uso de .Wait() e exceções na minha talk não se aplicam a esse tópico de hoje. Mas isso não significa que você deva preferir .Await() em lugar de await ⎼ pelo contrário. Evite bloquear a “thread chamadora” desnecessariamente.
Uma dica para lidar com isso é usar o método .Flatten() da AggregateException. A grosso modo, o que esse método faz é criar uma única exceção com a exceção original incluída na propriedade InnerExceptions. Assim você não tem que ficar iterando por exceções aninhadas.
Programação paralela visa aumentar o uso das CPUs, temporariamente, com intuito de aumentar o throughput da aplicação. Ótimo! Queremos isso. Afinal, muitos desktops ficam com a CPU idle boa parte do tempo. Mas cuidado, porque isso não é sempre verdade quando se trata de servidores.
Servidores rodando aplicações ASP.NET, por exemplo, podem ter menos tempo de CPU idle, dependendo do volume de requisições simultâneas, porque o próprio framework lida com múltiplas requisições em paralelo, visando tirar melhor proveito do ambiente multicore disponível. Portanto, botar código que atende a requisições de clientes para rodar em paralelo, pode acabar sendo um baita de um tiro no pé, quando houver um grande volume de requisições simultâneas.
Via de regra, muito cuidado com multithreading em aplicações web.
Concluindo
Ao longo deste mais do que longo post, diferenciamos tarefas assíncronas de tarefas paralelas, nos aprofundamos nas paralelas e vimos algum código para ilustrar a discussão. Também vimos que concorrência não significa necessariamente paralelismo. Mas pode vir a ser, eventualmente.
Se você chegou até aqui e gostou, por favor, compartilhe com seus amigos, deixe seu comentário, suas dúvidas, e vamos nos falando.
Se mesmo tendo visto o meu webinar, você ainda tiver dúvidas sobre async/await, bota suas dúvidas aqui nos comentários. Quem sabe não consigo te ajudar? Não custa tentar.
Ah! E por falar em webinar, talvez eu faça um webinar discutindo o conteúdo deste post. Ou talvez me aprofunde mais no assunto concorrência, algo nessa linha. Seria a última peça do quebra-cabeças. Vou pensar a respeito.
Até a próxima!
—
BTW, estamos contratando 🙂
Se você ainda não conhece a nossa stack e quer saber como você poderia nos ajudar a construir a Pricefy, que foi recentemente adquirida pela Selbetti, dá uma checada nesses bate-papos:
ProdOps ⎼ Engenharia e Produto com Leandro Silva (link 1 e link 2);
ElvenWorks ⎼ Conhecendo a tecnologia por trás de uma solução muito inteligente de Precificação (link).
Lá pelo idos de 2000, quando tive meu primeiro contato com C#, eu era um jovem “programador Java”, com alguns poucos anos de experiência em Delphi, sonhando com um futuro onde Java seria ubíquo e nada mais seria importante. Mas C#, em especial, capturou minha atenção por estar sendo desenvolvida por Anders Hejlsberg, o mesmo cara que já havia criado o Turbo Pascal e o Delphi, que eu era muito fã ⎼ e ainda tenho certa nostalgia, vez ou outra, confesso.
Na época, achei que não passava de um Microsoft copycat do Java e segui a vida.
O reencontro
Fast forward uns 9 anos e lá estava eu, na Locaweb, assumindo a gestão de um time que era quase 100% baseado em C#, depois de quase uma década sem dar qualquer 5 minutos de atenção à linguagem ou à plataforma .NET em si.
A primeira surpresa que tive foi que .NET ainda não tinha ferramentas robustas de build, gerenciamento de artefatos, dependências, etc e tal, como tínhamos Maven (a.k.a. The Official Internet Download Tool), Ant, Ivy, Hudson (a.k.a.Jenkins) e Artifactory na comunidade Java. Isso, obviamente, dava espaço para que diversos problemas emergissem do desenvolvimento de aplicações distribuídas, como era o nosso caso. Problemas estes, que a comunidade Java já tinha passado há anos e coçado a sua própria coceira.
Uma das minhas primeiras iniciativas no time, então, foi dar apoio aos ótimos engenheiros de software que tínhamos, para que eles resolvessem esse problema. (Alguns de nós éramos programadores Java experientes, by the way.) Além de liberar certo tempo nas sprints, para que pudessem se dedicar a isso, também contribui com algum código. E foi dessa iniciativa que nasceu o projeto IronHammer ⎼ curiosamente, escrito em Ruby, não C#. Assunto para um outro momento.
A segunda surpresa que tive foi o quanto C# tinha evoluído e se tornado, na minha opinião, um Java melhor (a linguagem em si, não a plataforma), o que contrastava com a questão do ferramental precário, que me chamou atenção inicialmente. O próprio Visual Studio era super precário; sem ReSharper, ele não era muito mais do que um Notepad glorificado.
Propriedades auto-implementadas, inferência de tipos (var), expressões lambda, LINQ (que é uma das coisas mais fantásticas do .NET), extension methods, tipos anônimos, etc, eram features que C# já possuía há pelo menos 2 anos quando tomei conhecimento. E passados alguns poucos meses, quando eu mal tinha emergido da minha imersão em C# 3, veio o C# 4, trazendo dynamic e parâmetros opcionais, entre outras coisas.
C# 4.0 Breaking News! ⎼ Tech talk que fiz com um colega à época
É bom que se reconheça uma coisa: se a linguagem Java foi a grande influência da criação e dos primeiros anos de vida do C#, muito de sua evolução posterior se deu por influência de F#, que apesar de mais jovem, tem em seu DNA a família ML de linguagens, descendendo diretamente de OCaml. Uma bagagem e tanto.
Ela segue em frente
Fast forward mais uma década e aqui estou eu, construindo a Pricefy há 5 anos, mantendo uma base de código majoritariamente C#, e mais uma vez impressionado com o quanto a linguagem evoluiu desde a última vez que parei para refletir a respeito. Do async/await do C# 5 aos avanços de pattern matching e top-level statements do C# 9, o que fica muito claro para mim é que a evolução da linguagem continua a todo vapor, mantendo-a jovial e moderna. Até quando? Não sei. É verdade que tem gente que já está reclamando que a linguagem está ficando complicada demais e inchada. Aliás, essa não é uma reclamação nova, sejamos francos; já tem certo tempo que essa questão tem sido levantada. Há até quem diga que está se transformando em C++.
Mas a verdade é que não temos que usar todas as features e capacidades de uma linguagem, sejam elas novas ou de berço, simplesmente porque elas estão lá, disponíveis. Há tempo e utilidade para cada funcionalidade ⎼ “à moda antiga” não é automaticamente errado.
No caso específico de C#, que estamos discutindo, a esmagadora maioria das novidades que chegaram ao longo dos anos foram para simplificar o código que se escreve e não para deixá-lo mais complicado. O mesmo vale para C++, diga-se de passagem.
Como as coisas foram ficando mais simples ao longo dos anos.
Complicado é tentar guardar na cabeça cada uma das zilhares de funcionalidades da linguagem ou as trocentas maneiras de se fazer a mesma coisa.
Honestamente? Eu não sei todas as features da linguagem. Não sei. Eu provavelmente nem devo saber, de bate pronto, assim, pá pum, todas as maneiras de se declarar e atribuir uma variável qualquer para salvar a minha própria vida. Isso porque, é quase impossível bem difícil você “modernizar” sua base de código de negócio pari passu com a linguagem de programação (ou mesmo framework) que você usa. Primeiro, porque com o passar dos anos a base de código vai ficando cada vez maior e essa “modernização” nem sempre vai trazer um retorno substancial para o problema de negócio, que o código se propõe a resolver, em função do esforço necessário para a tal “modernização”. Segundo que, vintage é cool. Não, é brincadeira. (Mas é verdade.)
O meu ponto é: manter uniformidade na base de código é mais importante e traz mais valor real ao negócio do que manter a base de código atualizada com as últimas novidades da linguagem. Um código uniforme, que qualquer dev do time navega bem e se sente em casa para implementar novas funcionalidades, modificar funcionalidades existentes e corrigir bugs, na minha cartilha, é mil vezes mais importante. Ou bem próximo disso.
Prefira a homogeneização
O que eu advogo é ir incorporando à base de código novidades da linguagem, especialmente, syntactic sugars, de maneira homogênea, para evitar criar uma colcha de retalhos. Sabe aquela base de código, que se você abrir três arquivos diferentes, parece que foram três pessoas de três lugares remotos do planeta que escreveram? Pois é. Em um arquivo, todas as variáveis são declaradas com anotação de tipo (a.k.a. tipo à esquerda); no outro, todas as variáveis são declaradas com inferência de tipo (var); e no último, há uma mistura dos dois estilos de sintaxe. E você, precisando editar o arquivo fica: e agora, que estilo devo seguir?
Eu sou do tipo que, em geral, segue o padrão do arquivo e mantém o estilo dele, seja este qual for. Exceto quando o dito arquivo não tem padrão nenhum ou não segue as convenções gerais do projeto; aí eu mudo, para enquadrá-lo no estilo majoritário do projeto.
Uma boa abordagem para solucionar este exemplo é ir homogeneizando em favor de var tanto quanto possível. Abriu um arquivo para editar, viu um trecho de código que está fora do “padrão”, refatora, padroniza. Um padrão ruim ainda é melhor do que a ausência de um padrão, porque se no futuro o time decidir mudar o padrão, vai ser muito mais fácil do que se não houvesse padrão algum.
Que tal um outro exemplo? Você precisa implementar uma nova funcionalidade na aplicação e, no processo, se depara com um método que possui uma cadeia de ifs relativamente complexa e tudo mais. Aí, analisando, você vê que o problema não é tão complexo quanto a implementação da solução. Você vê que a implementação poderia ser drasticamente simplificada usando pattern matching, que você andou estudando, mas em nenhum outro lugar da aplicação há uso de pattern matching ainda, muito embora o runtime da aplicação dê suporte a isso. O que você faz? Refatora. Porque vai haver ganho para o negócio. Quero dizer, a próxima pessoa que precisar dar manutenção neste código vai fazer isso de maneira mais confiante e rápida.
Um último exemplo que gostaria de dar aqui é o caso de interpolação de strings, que é super mundano. C# faz interpolação de strings de maneira elegante desde a versão 6, se não estou enganado, mas ainda é comum ver código por aí que não se beneficia disso, o que é uma pena. Porque além do código ficar mais limpo, quando você faz interpolação de strings, o compilador, gratuitamente, gera para você o código equivalente usando string.Format, que no final das contas, vai usar um StringBuilder. De graça e elegantemente. Quem não quer isso?
As minhas favoritas
Se você acompanhou meu rant até aqui, provavelmente, já teve uma ideia das minhas features favoritas do C# “moderno”, se é que posso chamar assim. Além delas, vou citar mais algumas.
Inferência de tipos
De longe, eu acho que o que eu mais gosto da linguagem C# é a inferência de tipos que ela proporciona o tempo todo (uma salva de palmas para a dupla “linguagem & compilador”), tanto na declaração de variáveis (var / dynamic), quanto na invocação de métodos que possuem type parameters (a.k.a.generics).
Out variables
Eu odiava quando tinha que declarar uma variável antes de usá-la em um método que tem parâmetros out.
Declaração prévia.
Mas aí, finalmente, no C# 7, alguém teve a brilhante ideia de resolver isso, permitindo que se declarasse variáveis outdireto da invocação de métodos com parâmetros out.
Declaração concomitante ao uso.
Named Tuples, Discarts e Deconstruction
Tuplas estão entre minhas construções favoritas em qualquer linguagem de programação. Meu primeiro contato com elas foi em Scala, depois em Erlang. Para expressar retorno de métodos e aplicar pattern matching, por exemplo, tuplas são extremamente poderosas. Junte a isso a capacidade de fazer desconstrução de objetos e descartar valores que não importam no momento e você tem uma oportunidade fantástica de escrever código limpo e expressivo. C# 7 nos deu isso.
O snippet que apresentei na seção anterior, falando de pattern matching, é outro exemplo prático e elegante do uso de tuplas.
Throw Expressions
Essa feature, também do C# 7, tornou bastante prático, quando é preciso checar se um determinado identificador contém um valor e, se sim, atribuí-lo a um outro identificador; ou senão, lançar uma exceção.
Anteriormente, esse código obrigaria um tipo de if-else.
Null-coalescing Assignment
C# 6 havia introduzido Null-conditional Operator(.? e []?) na linguagem com bastante sucesso, eliminando uma série de expressões check-before-access. C# 8, por sua vez, trouxe um novo syntactic sugar para ir um pouco além (?? e ??=), super útil para fazer check-then-assign. Trocando em miúdos e exemplificando com o código abaixo, o que isso significa é que, usando o operador ??=, o valor da direita só será atribuído à variável da esquerda, se esta variável for nula.
That sugar, baby!
Record Types
Para fechar, uma feature mais recente, do C# 9, que eu sinceramente ainda não apliquei em códigos de produção. Diferente das structs, que são value types que todos nós conhecemos de longa data, os records são, na verdade, syntactic sugar para classes que implementam uma série de funcionalidades que favorecem o emprego de “imutabilidade” de dados, como é o caso do operador with, que faz cópia com modificação (a.k.a. Nondestructive Mutation). É isso. Embora, eles também possam ser mutáveis, seu objetivo principal é ser immutable & data-centric types.
De início, quando comecei a ouvir falar dessa feature, achei que fosse só hype e pensei: já temos struct e class, para que mais um tipo? Mas quando fui me informar melhor, estudar a proposta, enxerguei benefícios práticos.
Essa é, portanto, uma feature que vejo como forte candidata a ser introduzida em bases de código mais datadas. E isso, porque ela diminui a quantidade de código que você tem que escrever para ter certas garantias e comportamentos por vezes desejados (imutabilidade, igualdade de valor, etc). C# 9 faz isso de graça, sem que você tenha que escrever um tanto de código boilerplate, que teria que dar manutenção depois.
Conclusão
C# evoluiu demais nos últimos anos. Especialmente, na última década.
A linguagem tem ficado mais complexa? Tem. Mas não é o tipo de complexidade que você e eu somos obrigados a lidar no nosso dia a dia. É complexidade que os desenvolvedores da linguagem precisam lidar. Você e eu podemos, ou não, usar as novas features que ela oferece; que na maioria dos casos, insisto, só facilitam o nosso trabalho.
Você não precisa guardar toda a sintaxe da linguagem na sua cabeça. Há coisas melhores para ocupar a nossa memória. Apenas lembre-se de sempre checar se não há uma maneira melhor ou mais simples de fazer a tarefa da vez.
Desde que me lembro, sempre fui autodidata. Muito do que aprendi, aprendi por iniciativa própria, movido por uma curiosidade que arde dentro de mim, lendo livros técnicos, artigos científicos (eu sou nutricionista, btw), blog posts, assistindo a vídeos e, não menos importante, observando atentamente pessoas que sabem mais do que eu sobre determinado assunto.
Ao longo dos anos, tive uns tantos mentores, formais ou informais, que me ensinaram muitas coisas e me sinto bastante afortunado por isso.
Continuando o cíclo
Ensinar sempre foi algo que me interessou bastante. Seja de modo formal ou informal, sempre tive um impulso natural de compartilhar com os outros aquilo que eu sei. O que sempre fez com que a roda girasse na minha vida, em um ciclo contínuo de aprendizado e compartilhamento.
E é por isso que estou iniciando um trabalho independente e gratuito de mentoria em tecnologia e liderança.
Público alvo
Jovens líderes, engenheiros de software, arquitetos de sistemas, etc. Qualquer pessoa que esteja a fim de aprender, crescer e dar o próximo passo em sua carreira, seja lá qual for.
Se você:
– está iniciando sua carreira em engenharia de software, está meio perdido com tanta sopa de letrinha, não sabe no que foca ou que caminho trilhar;
– está responsável pela arquitetura de sistemas da firma e está enfrentando um problema técnico que não sabe como resolver;
– está responsável pela liderança técnica de uma jovem startup e as incertezas estão te deixando apavorado;
– está a cargo de escalar o time de engenharia de produtos digitais e não faz ideia de por onde começar;
– está enfrentando problemas com seu sistema em produção dia sim, dia também, com bugs, gargalos, problemas de escalabilidade;
Essa mentoria pode ser para você. Pode ser que conversando, te ouvindo e dividindo com você um pouco da minha experiência, você encontre a resposta, a solução, o caminho, ou seja lá o que esteja buscando.
Essa mentoria não é para amigos, chegados. Vocês podem me chamar a hora que for preciso. É isso que significa ser chegado, né?
Como vai funcionar?
Vamos ter encontros de 1 hora, 1 vez por semana, durante 4 semanas. Estes encontros acontecerão via Google Meet, no melhor horário que atenda às nossas agendas.
A ideia é iniciar a mentoria na segunda semana de janeiro de 2022.
Aos interessados
Se você se interessou, se é justamente o que você está precisando, basta preencher o formulário abaixo:
Andei batendo um papo muito bacana sobre a construção da Pricefy, engenharia de produtos digitais e a vida real em produção, com Christiano Milfont e Bruno Pereira, dois veteramos da tecnologia, que muita gente conhece desde os bons tempos de GUJ.
Para quem ainda não conhece o canal deles no YouTube, recomendo bastante dar um checada. Tem muita entrevista legal lá, com outros veteranos da área. Vale a pena conferir.
Tempo de compilação é uma coisa que me incomoda um pouco quando estou mexendo com Rust, por exemplo. Cada cargo build ou check é uma esperinha chata. Com Go isso não acontece.
Além da simplicidade, a linguagem se propõe a trazer para mesa um tanto de features desejáveis de outras linguagens e mais alguns bônus. Como eles dizem na documentação, V foi criada porque nenhuma das linguagens que os inspiraram tinha “todas” as features que eles buscavam.
Outra coisa que gostei bastante: baterias inclusas. Não tem coisa mais irritante do que ter que ficar instalando um pacote para cada coisa trivial que você precisa fazer.
V traz built-in uma biblioteca multiplataforma de UI nativa, biblioteca gráfica 3D, ORM (que atualmente suporta SQLite, mas há trabalho em curso para MySQL e Postgres; e no futuro também Oracle), frameworks de Web e Teste, etc. O mínimo que você usa no dia a dia.
E finalmente, a interoperabilidade com C. V compila para C; e na versão que está por vir, vai ser capaz de traduzir C para V também. Isso é fantástico por dois motivos: C roda em qualquer lugar; você vai poder dar uma vida nova ao seu código C legado.
Tem mais algumas outras coisas que achei bacana na proposta da linguagem. Algumas delas são coisas que também gosto em Rust, Go, C++, enfim, acho que não vale a pena comentar, para não chover no molhado. O principal é o que falei mesmo.
Do que não gostei?
Honestamente, de nada exatamente. Mas encontrei algumas limitações, que são naturais para o estado de maturidade da linguagem.
Uma das features da linguagem é que o backend dela é C e não LLVM, como já mencionei. Isso é interessante. Mas às vezes, você se depara com alguns erros de compilação que te apontam para o código C. Se você souber C, okay, você está em casa. Mas se você não souber, provavelmente vai ficar mais assustado do que esclarecido.
Para mim, documentação, exemplos de uso e casos de erro vs. solução (a.k.a. StackOverflow) são fundamentais para a adoção de qualquer linguagem ou tecnologia em ambiente produtivo. É preciso ter uma comunidade sólida ao redor de uma linguagem para que sua adoção possa acontecer em ambiente comercial. Do contrário, boa sorte tentando convencer o seu chefe de que Xyz é a melhor solução.
Dito isso, muito embora, eu, particularmente, não ache que V esteja pronta para produção (ao menos, não para o meu contexto atual), já há bastante coisa legal sendo feita em V, desde computação científica até bot de Telegram.
Tem um repositório bacana, que segue aquela ideia de “awesome alguma coisa”, que você pode dar uma olhada, para ver o que já fizeram com V.
E como usuário de software open source, membro da comunidade, este é um ótimo momento para contribuir com o amadurecimento da linguagem, se ela te interessar. (Senão V, que seja outra linguagem ou tecnologia open source qualquer que você se interesse. Contribuir de volta é sempre uma boa.)
O que eu fiz para ajudar? Escrevi um exemplo de interop com C para converter HTML em PDF usando libwkhtmltox e mandei um PR para os mantenedores da linguagem incluírem no repo oficial.
Fonte: Convert HTML to PDF using V and libwkhtmltox (Source)
Talvez contribua mais no futuro, conforme acompanho de perto a evolução e o amadurecimento da linguagem.
Vamos ver.
—
UPDATE: 03-01-2021 – Pull request foi aceito e incorporado à master.
Nos últimos 4 anos e pouco, a maior parte do código que lido no meu dia a dia profissional na Pricefy é C# .NET. É verdade que tem um tanto de JavaScript no front-end e Node.js em pontos específicos do back-end, mas a maioria esmagadora é .NET mesmo. Por isso não escrevo muito sobre .NET e procuro fazer meus projetos pessoais em outras tantas linguagens que também me interessam. Não porque não gosto de C#, mas porque não gosto só de C#.
Eu gosto de exercitar minha “mente de programador” em paradigmas diferentes e tentar caminhos alternativos para chegar ao mesmo lugar; às vezes mais rápidos, às vezes mais eficientes e outras vezes até mais elegantes. Com sorte, tudo isso junto.
Eu gosto disso.
Hoje, então, é um desses raros episódios em que C# aparece no blog.
O que é gRPC afinal?
Parafraseando longamente o próprio site oficial, gRPC é um framework de RPC open source, moderno, de alto desempenho, que pode ser executado em qualquer ambiente. Ele pode conectar serviços de forma eficiente dentro e entre data centers, com suporte plugável para balanceamento de carga, tracing, verificação de integridade e autenticação. Também é aplicável na última milha da computação distribuída para conectar dispositivos, aplicativos móveis e navegadores a serviços de back-end.
Inicialmente, foi desenvolvido pelo Google, lá pelos idos de 2015, juntando duas peças fundamentais já existentes: HTTP/2, para fazer o transporte, e Protocol Buffers, como IDL e método eficiente de serialização/deserialização de dados. Protobuf, para os mais chegados, também foi desenvolvido no Google.
Muitas empresas usam massivamente gRPC para otimizar a comunicação de microsserviços. Netflix e Spotify são algumas delas.
Também é muito empregado no segmento de Blockchain ⎼ eu mesmo, quando escrevi meu I.N.A.C.A.B.A.D.O.blockchain de brinquedo, há uns 3 anos, também lancei mão de gRPC em Go.
Complexidade de uso
No back-end e dispositivos móveis, seu uso é trivial. Você escreve um arquivo .proto que define o serviço (IDL), usa uma ferramenta para gerar código para uma determinada linguagem que vai implementar o servidor do serviço e para outras N linguagens que vão implementar o cliente do serviço. Voilà.
Já em navegadores a coisa não é tão simples assim.
Por se tratar de um protocolo que faz uso avançado de HTTP/2, seu uso em navegadores é mais “complicado” em servidores, para dizer o mínimo.
Basicamente, o que você precisa é ter um proxy na frente, fazendo traduções do cliente rodando no browser para o serviço no servidor. Não é o fim do mundo, mas com certeza passa longe do trivial. Mais sobre isso adiante.
Para tentar facilitar seu uso em navegadores, surgiu a iniciativa gRPC-Web.
O protocolo gRPC-Web
Sem muito rodeio, indo direto ao que importa, o que o protocolo gRPC-Web faz é prover uma API Javascript para navegadores baseada na mesma API do Node.js, mas por baixo dos panos, implementando um protocolo diferente do gRPC padrão, que facilita o trabalho do proxy na tradução entre o protocolo cliente e o protocolo servidor.
O proxy default dessa implementação é o Envoy. Mas há planos para que os próprios frameworks web das diversas linguagens implementem in-process proxy, eliminando a necessidade de um proxy terceiro.
Entra o ASP.NET Core
O que o time do ASP.NET Core fez foi exatamente isso: escreveram um middleware que faz o papel de proxy, eliminando a necessidade de se ter um proxy terceiro na jogada. Thanks, Sir Newtonsoft.
Seu uso ficou muito, muito prático. Uma vez que você tenha adicionado ao projeto referência ao pacote Grpc.AspNetCore.Web, basta duas linhas no Startup.cs:
Fonte: Configure gRPC-Web in ASP.NET Core (link | source)
E no cliente JavaScript, nada muito diferente do que já estamos acostumados a fazer em Node.js.
Fonte: gRPC for .NET / Examples / Browser (source)
Okay. Neste momento, se você lida com aplicações web requisitando serviços em servidores diferentes, provavelmente já pensou em quatro letras: CORS. O pessoal do ASP.NET Core também.
Difícil dizer se vale a pena ou não para seu projeto, para sua equipe, porque cada caso é um caso. Como quase tudo na vida, a resposta mais provável é DEPENDE.
Não é porque é novo e fácil, que é bom para tudo. Vamos pensar, então, em cenários de uso.
Um dos potenciais cenários de uso é quando você precisa lidar com grandes volumes de dados, trafegando pra lá e pra cá. Há algumas maneiras de se lidar com esse tipo de problema. Uma delas é usar um protocolo binário, pois o tamanho das mensagens é muito, muito menor, do que o de um protocolo texto, como JSON, e a serialização/deserialização é absurdamente mais rápida.
Fonte: How to boost application performance by choosing the right serialization (link)
Pensando neste caso de uso e possível solução, a equipe do ASP.NET Core em parceria com a equipe do Blazor, escreveram uma aplicação web (Blazor WebAssembly) para demonstrar o uso do gRPC-Web vs o bom e velho JSON.
Abaixo, um printscreen que acabei de tirar, comparando uma requisição obtendo 10 mil registros em formato JSON vs 10 mil registros com gRPC-Web.
gRPC-Web traz para o ambiente de aplicações web muitas vantagens já consolidadas pelo gRPC tradicional, como por exemplo, o uso de mensagens binárias bem menores que o bom o velho JSON, serialização/deserialização consequentemente mais rápida, APIs de streaming e a adoção de contratos de API formalizados por IDL.
Outro dia desses, pensando sobre software, arquitetura de sistemas, gente e a natureza falível de tudo isso, enquanto tomava a primeira xícara de café do dia, recém coado, me lembrei de um trecho do livro ZeroMQ, do Pieter Hintjens:
Most people who speak of “reliability” don’t really know what they mean by it. We can only define reliability in terms of failure. That is, if we can handle a certain set of well defined and understood failures, we are reliable with respect to those failures. No more, no less.
ZeroMQ: Messaging for Many Applications, Pieter Hintjens, page 141.
O que eu, na modéstia do meu intelecto, reduzi à frase:
Um sistema é tão confiável quanto foi preparado para ser.
À qual, eu certamente poderia acrescentar “nem mais, nem menos” ao final. Mas não tenho tanta certeza de que “nem menos” é tão verdade assim. Principalmente, em se tratando de sistemas distribuídos; ainda que se tenha um projeto super minucioso. Vou deixar com está.
Foi daí que saiu a motivação de fazer este post. Porque este é o tipo de assunto que fica subentendido em muitas conversas que temos em nosso dia a dia, projetando, implementando e mantendo software em produção. Parece que todo mundo sabe do que está falando, presume que a pessoa ao lado sabe do que está falando e que estão todos na mesma página, falando sobre a mesma coisa, partindo das mesma premissas e reconhecendo as mesmas limitações. Ainda mais em tempos de cloud, microsserviços, serverless e essa coisa toda.
Entretanto, embora isto deva ser bem óbvio, acho que devo pecar pelo excesso aqui e dizer que não tenho a pretensão de escrever um post que esgote o assunto “confiabilidade” de software e sistemas. Aliás, muito longe disto. A literatura sobre confiabilidade de software e sistemas é vasta e impossível de se cobrir em um post. Eu nem mesmo já consumi toda a literatura de que tenho ciência da existência. Portanto, não assuma que isto é tudo.
A ideia é ser um pequeno aperitivo, que desperte o seu apetite e te leve a buscar por mais.
Confiabilidade de Software
Para começar, então, vamos trazer um pouco de definição à mesa.
The probability of failure-free software operation for a specified period of time in a specified environment [ANSI91].
Michael R. Lyu, Handbook of Software Reliability Engineering, page 5. [pdf]
Ele expande ainda um pouco mais esta ideia, logo em seguida, explicando que a confiabilidade de software é um dos atributos da qualidade de software ⎼ que por si só é uma propriedade multidimensional, que inclui outros fatores também ligados à satisfação do cliente, como funcionalidade, usabilidade, performance, suportabilidade, capacidade, instalabilidade, manutenibilidade e documentação.
The system should continue to work correctly (performing the correct function at the desired level of performance) even in the face of adversity (hardware or software faults, and even human error).
Martin Kleppmann, Designing Data-Intensive Applications, page 6.
Mais adiante, ele fala sobre o que tipicamente se espera de um software ⎼ que ele realize as funcionalidade esperadas pelo usuário; tolere erros cometidos do usuário; tenha desempenho bom o bastante para os casos de uso suportados, dentro do volume de dados esperado; e que previna acessos não autorizados e abusivos. Resumindo, o que ele diz é que o software deve continuar funcionando corretamente, mesmo quando as circunstâncias são adversas.
Enquanto Lyu apresenta 3 pontos importantíssimos para qualquer discussão sobre confiabilidade de software:
– Probabilidade de ausência de falhas; – Por período específico; – Em ambiente específico.
Kleppmann fala sobre continuidade de funcionamento correto dos sistemas mesmo quando as circunstâncias não são favoráveis a isto.
Aos sistemas que toleram tais situações adversas, ou falhas, damos o rótulo de “tolerantes à falhas”. Mas isto não significa que sejam tolerantes a todas e quaisquer falhas, porque isto seria absolutamente impossível. Há sempre uma restrição imposta por tempo para se projetar, implementar e testar uma solução, custo de viabilização, habilidade humana para realização e tamanho do retorno sobre todo investimento empregado. Em outras palavras, ter “tudo” nunca é uma opção.
Este é o ponto chave da menção que fiz de Hintjens no início deste post: um sistema tolerante à falhas é um sistema que está preparado para lidar com aquelas falhas que são bem conhecidas e compreendidas, em cujo qual certo esforço foi empregado para prepará-lo para tal. Nem mais, nem menos.
Agora, seja lá qual for a régua que adotemos, a verdade fria da coisa é que a confiabilidade de software é um fator crucial na satisfação do cliente, uma vez que falhas de software podem tornar um sistema completamente inoperante.
E não estou me referindo apenas a sistemas de ultra missão crítica, que podem causar a morte de pessoas, destruir vidas de verdade, como alguns exemplos que Pan oferece em seu artigo, mas de coisas mais mundanas mesmo, como Kleppmann cita em seu livro. Quero dizer, bugs em aplicações de negócio, que fazem seus usuários perder produtividade; indisponibilidades em e-commerces que impedem que vendas sejam concluídas; produtos de software que são vendidos, mas nunca provisionados no prazo prometido; e por aí vai. Você provavelmente deve ter ótimos exemplos muito melhores do que estes.
É claro que há momentos em que, conscientemente, decidimos sacrificar a confiabilidade de um sistema para reduzir seu custo inicial de desenvolvimento, porque estamos, por exemplo, desenvolvendo um protótipo ou MVP, que pode acabar indo para o lixo; ou pode ser o caso de termos que manter o custo total de um produto super baixo, porque sua margem de lucro não justifica nada além do mínimo possível. Ou simplesmente porque aquela funcionalidade incrível, que ninguém pode viver mais um dia sem, era para ontem.
Quem sabe se não é essa tal funcionalidade incrível, ainda que meio bugada, que vai fazer a diferença entre o sucesso ou a ruína de um produto?
Temos que estar realmente muito conscientes das decisões que tomamos, que afetam direta ou indiretamente a confiabilidade dos softwares que de algum modo comercializamos, já que este é um fator tão fundamental à satisfação dos nossos clientes.
Precisamos estar seguros em relação a pelo menos estes seis pontos:
– De onde estamos cortando; – Porque estamos cortando; – Por quanto tempo estamos cortando; – Se é um corte remediável no futuro; – O quanto o usuário vai sofrer com os cortes; – E o quanto estamos ganhando com tudo isto.
Não se pode ter tudo. Mas pode-se ter consciência sobre o que não se tem e suas consequências imediatas e futuras.
A triste realidade de software
Diferente de bens materiais, como um carro, uma torneira, uma fotocópia, ou um equipamento eletroeletrônico qualquer, um software não envelhece, não enferruja, não se desgasta e perde funcionalidade com o tempo. Dado que todas as condições externas ao software, às quais ele depende, sejam exatamente as mesmas, não importa quantos anos de existência tenha uma determinada versão do software, ela vai funcionar tão bem (ou tão mal) quanto da primeira vez. Nhmmmm, sort of…
A verdade deprimente é que softwares que rodam continuamente por longos períodos de tempo, fazendo qualquer coisa minimamente importante para alguém, ainda que sob as mesmas [supostas] condições de ambiente nos quais estão inseridos (hardware, sistema operacional, rede, etc), com o tempo, vão se degradando, porque estas [supostas] condições externas vão se alterando e assim também suas próprias condições internas, ainda que seu código fonte ou mesmo binário permaneçam absolutamente inalterados.
Daí a importância de se ter um time de operação capacitado, munido com ferramentas de gestão de configuração, monitoria, telemetria e todo o mais possível.
Isto é, tanto quanto o conteúdo do código fonte mantém-se intacto quando este é submetido à execução, também a sua qualidade permanece a mesma. O que significa que, quanto menor a qualidade do código fonte, maior a probabilidade de seu estado em execução se degradar em um menor espaço de tempo e resultar em incidentes em produção ⎼ o que, em última análise, se traduz em cliente insatisfeito e imagem da organização arranhada.
E isto não é tudo. Em um ensaio sobre confiabilidade de software da Carnegie Mellon University, Jiantao Pan escreve que a complexidade de um software está inversamente relacionada à sua confiabilidade; quanto maior sua complexidade, menor sua confiabilidade. Já a relação entre complexidade e funcionalidade tende a ser causal; quando maior o número de funcionalidades, maior sua complexidade.
Lembra-se da máxima de que menos é mais? E daquela estimativa de que 80% dos usuários usam apenas 20% das funcionalidades? Pois é, chunchar funcionalidades para competir pode ser não apenas uma estratégia ineficaz, como também um ofensor da confiabilidade do sistema como um todo.
Diferentemente do que acontece com bens materiais, como disse há pouco, que vão se deteriorando e sofrendo aumento na ocorrência de falhas ao longo de sua vida útil, softwares tendem a ter maior ocorrência de falhas em sua fase inicial e muito menos em sua fase de obsolescência.
Note que o que causa aumento da chance de falhas, com efeito levemente residual, é justamente a implantação de novas versões; em especial, se elas trouxerem consigo novas funcionalidades. Não que esta informação deva nos deixar acanhados de publicar novas versões, absolutamente. O que devemos, sim, é não ignorá-la. Precisamos ser mais responsáveis com o que publicamos em produção, investindo tempo em testes melhores, detectando falhas mais rapidamente e oferecendo maneiras de revertê-las o quanto antes.
A bem da verdade, até mesmo novas capacidades que visam aumentar a confiabilidade podem causar novas falhas. Senão por falhas no código em si, resultado do novo ciclo (seja ele de um dia ou um mês) de projeto, implementação e teste, pelo simples fato do ambiente sistêmico de produção não ser exatamente o mesmo de desenvolvimento. Eles podem até ser muito, muito, semelhantes um ao outro, mas frequentemente não são o mesmo. Muitas vezes, o ambiente de produção de ontem nem mesmo é o de hoje. Quem dirá, o de uma semana atrás.
Dispositivos móveis são um ótimo exemplo disto. Você nunca tem certeza sobre o estado que vai estar o dispositivo móvel quando seu aplicativo for instalado. Isso sem falar em sistemas embarcados.
Outro exemplo é o caso de softwares que compõem um sistema distribuído. Uma nova versão de um software coincide com uma nova versão de outro software, que torna-os de algum modo conflitantes e incompatíveis. Pau!
O fator “pessoas”
Eu acho um baita clichê quando dizem que tudo é sobre pessoas; ou alguma variação disso, com o mesmo significado. Mas no final das contas, a verdade é que é isso mesmo.
As pessoas projetam expectativas. As pessoas fazem promessas. As pessoas não conseguem cumprir suas promessas. As pessoas sequer conseguem fazer as coisas direito 100% do tempo. Porque no final das contas, como dizem, isto é ser humano, não é? É, pois é.
Em seu ensaio sobre confiabilidade de software, Pan faz referência ao paper de Peter A. Keiller e Douglas R. Miller, intitulado On the use and the performance of software reliability growth models, e escreve que falhas de software podem ser decorrente de erros, ambiguidades, omissões ou má interpretações da especificação; podem ser também descuido ou incompetência na escrita do código, teste inadequado, uso incorreto ou inesperado do software; ou outros problemas imprevistos. Em resumo, pessoas sendo pessoas.
E a despeito dele ter escrito isto em 1999, mesmo com o posterior advento do desenvolvimento de software ágil, ainda não erradicamos os fatores causadores de “falhas de software”. Diminuímos, sim, mas não eliminamos. Talvez porque, como ele diz, eles estejam intimamente relacionados a fatores humanos confusos e ao processo de projeto da coisa que estamos construindo, os quais ainda não temos um entendimento sólido. Pessoas, right?
O guard-rail
Se você chegou até aqui, talvez esteja se perguntando: se não dá para erradicar completamente, tem que dar ao menos para controlar a magnitude, mitigar de alguma maneira, certo?
Sim, certo. Nem tudo está perdido. Já vimos algumas dicas ao longo do caminho.
Em muitos casos, com processos de desenvolvimento sólidos, com ciclos curtos de projeto, implementação e teste; com práticas de engenharia cínicas, que sempre esperam pelo pior; com engenheiros de qualidade que caçam pêlo em ovo; com processos de governança super defensivos; e com real atenção à operação desde a concepção do que se está construindo.
Em outros casos, sentando e chorando. Okay, este último não é exatamente uma opção.
Ciclos menores
Promover ciclos menores de “concepção à produção” é uma ótima prática para se adotar, se não por tudo que vimos até aqui (especialmente a questão dos pacotes novo em produção), porque as pessoas tem limiares de atenção diferentes. Mas não é só isso.
Muitas vezes, a velocidade do negócio e suas incertezas nos obrigam a mudar de foco antes de conseguirmos concluir uma determinada atividade e isto é super frustrante, mesmo que você tente entrar naquele estado mental de “estamos fazendo isso pelo negócio”, “este é o melhor a se fazer”, “estamos aqui pelo cliente”. Yeah, I get it. Mas ainda assim é frustrante. Como seres humanos nos sentimos frustrados de começar algo e não concluir, seja por desinteresse momentâneo ou por força maior. Então, o quanto antes concluirmos, melhor.
Então, quanto menores? Tão pequenos quanto o suficiente para se fazer um bom projeto, implementação limpa e testes de verdade. Em alguns casos, tudo isto pode acontecer em horas; em outros, pode levar semanas. O importante é que se saiba bem o que se está programando e como testar que tudo está saindo conforme o esperado.
Quebrar grandes requisitos em diversos requisitos menores, que vão se complementando, é um caminho para se ter ciclos menores. Com certeza, é um bom começo.
Transparência
Aqui me refiro à transparência do software rodando em produção, como ensina Michael T. Nygard, em Release It, na página 226.
Nygard diz que um sistema sem transparência não pode sobreviver por muito tempo em produção. Ele diz que se os administradores do sistema não sabem o que os componentes do sistema estão fazendo, eles não podem otimizar este sistema. Bem, seria muito perigoso mexer no que não se tem controle. E não se pode ter controle do que não se faz a menor ideia.
Se os desenvolvedores não sabem “o que funciona” e “o que não funciona” em produção, eles não podem aumentar a confiabilidade e resiliência do sistema ao longo do tempo.
E quanto aos sponsors de negócio? Se eles não sabem se eles estão ganhando dinheiro com o sistema, eles não podem investir em trabalho futuro de melhoria, etc.
Ele conclui, então, em tom meio apocalíptico, penso eu, dizendo que um sistema sem transparência vai seguir em decadência, funcionando um pouco pior a cada nova versão.
Segundo Nygard ⎼ e tendo a concordar fortemente, depois de anos e anos escrevendo software e mantendo-os em produção ⎼, sistemas que amadurecem bem são sistemas que oferecem algum grau de transparência.
elegÂnCIA
Vimos que não é possível um sistema ser tolerante a toda e qualquer falha possível e imaginável. Devemos priorizar de modo consciente quais falhas toleraremos, para mantermos o funcionamento correto do sistema para o usuário final, se possível, sem que sequer se perceba que houve algo de errado.
Reliability means making systems work correctly, even when faults occur. Faults can be in hardware (typically random and uncorrelated), software (bugs are typically systematic and hard to deal with), and humans (who inevitably make mistakes from time to time). Fault-tolerance techniques can hide certain types of faults from the end user.
Martin Kleppmann, Designing Data-Intensive Applications, page 22.
Mas haverá momentos, como já vimos, em que não será possível manter funcionalidades completas do sistema diante de certas falhas, seja por decisão ou impossibilidade técnica. Nestes momentos, precisaremos recorrer a outros artifícios, se não quisermos torturar nosso cliente com tanta insatisfação. Graceful Degradation é um desses artifícios, mas ele não vem “de graça”.
One approach to achieving software robustness is graceful degradation. Graceful degradation is the property that individual component failures reduce system functionality rather than cause a complete system failure. However, current practice for achieving graceful degradation requires a specific engineering effort enumerating every failure mode to be handled at design time, and devising a specific procedure for each failure [Herlihy91].
Charles P. Shelton and Philip Koopman, Developing a Software Architecture for Graceful Degradation in an Elevator Control System. [pdf]
A “degradação elegante” de um sistema, chamemos assim, é um atributo que às vezes é confundido com a tolerância à falhas, mas há diferença entre eles.
Enquanto a tolerância à falhas diz respeito a lidar com componentes falhos do sistema, fazendo algum tipo de substituição, alguma manobra, que não cause degradação da experiência do usuário e continue a prover as funcionalidades esperadas, a degradação elegante, é a última instância do gerenciamento eficaz de falhas, quando a falha em componentes do sistema chega a um ponto em que não é mais possível manter as funcionalidades completas, com desempenho adequado, mas apenas parte delas, visando sobretudo evitar falhas generalizadas.
The purpose of graceful degradation is to prevent catastrophic failure. Ideally, even the simultaneous loss of multiple components does not cause downtime in a system with this feature. In graceful degradation, the operating efficiency or speed declines gradually as an increasing number of components fail.
Então, quando tudo for inevitavelmente para o despenhadeiro, porque o seu sistema chegou ao limite do quão confiável foi preparado para ser, tente ao menos ser elegante.

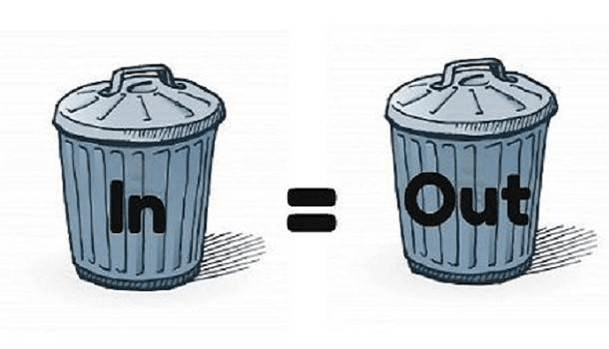



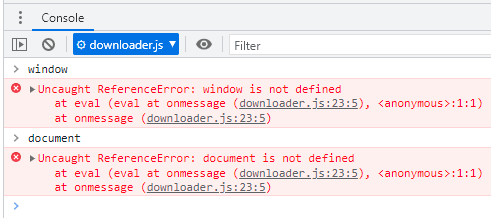
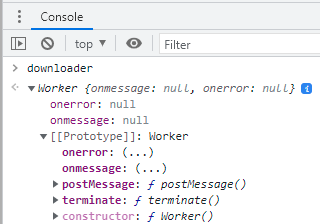
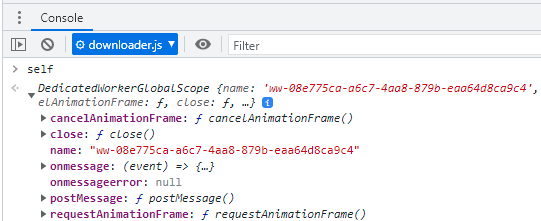

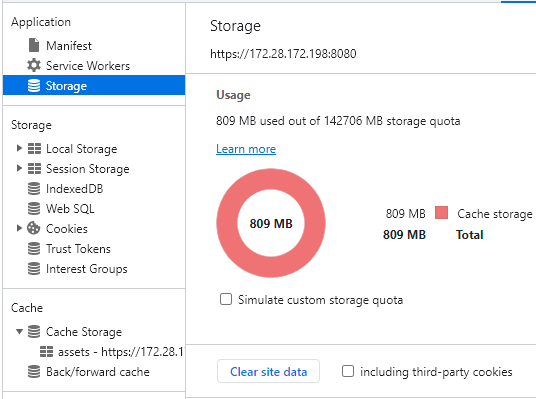
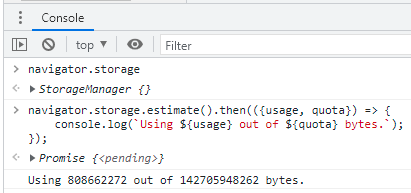
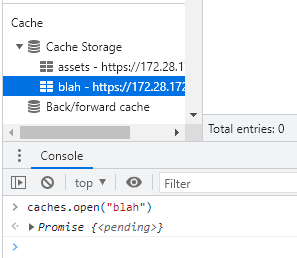
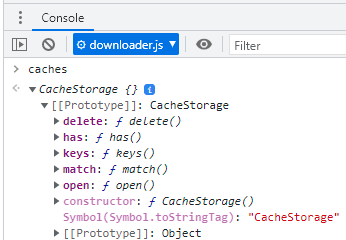

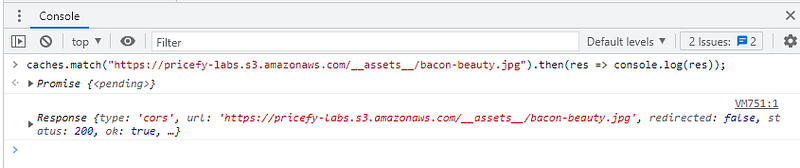





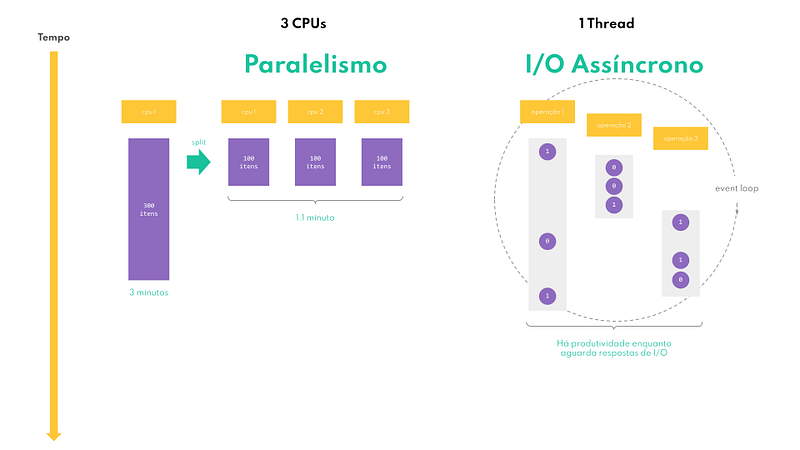
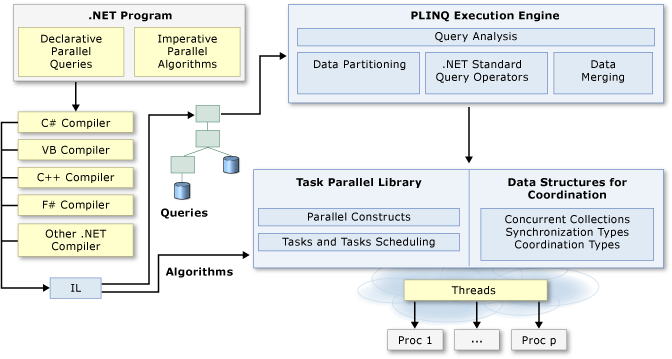



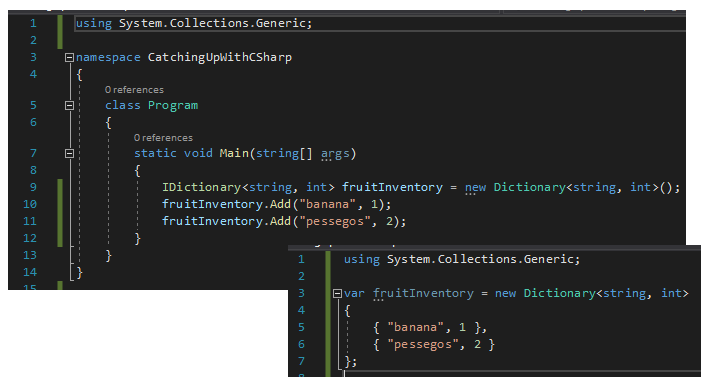
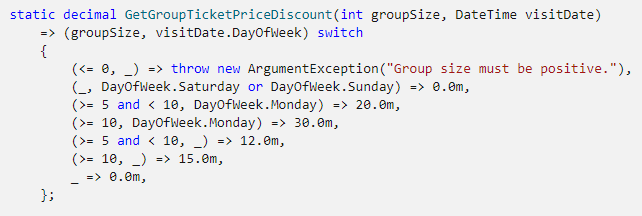
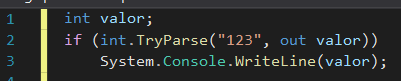



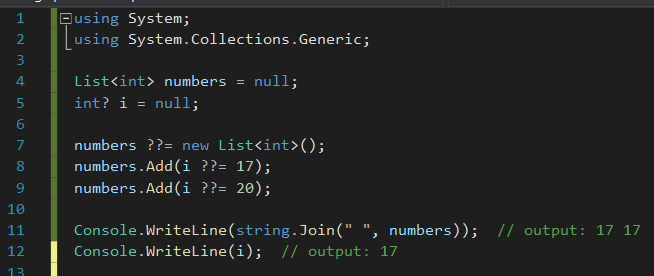
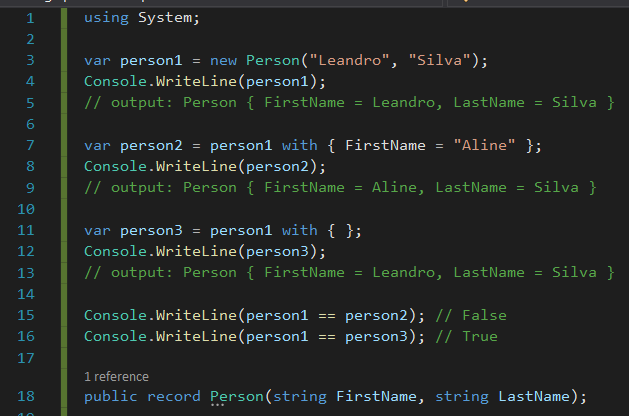











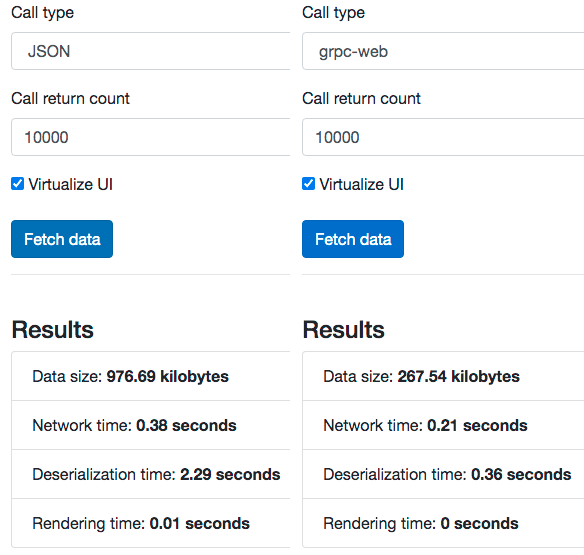

{kind=link}