Poucas coisas no mundo amplificam mais incrivelmente nossa percepção de “demora” do que usar um microondas ou navegar na web. Alguns segundos de espera na frente do microondas ou até menos do que isso, quando se trata de um navegador web, e voilà, bem-vindo à eternidade. Mas sem harpas ou cantos gregorianos, somente dor e ranger de dentes. Not cool.
Se alguma coisa pode ser rápida, queremos que ela seja o mais rápido que puder. Se alguma coisa pode estar lá, pronta para ser usada quando bem quisermos usar, queremos que assim esteja. No caso do microondas, nhemmm, não há muito o que se possa fazer. Sorry. Mas felizmente, a vida não é tão cruel quando se trata de navegadores web ⎼ web engineers, sim, estes podem ser bem cruéis, cuidado! (LOL)
Web Workers
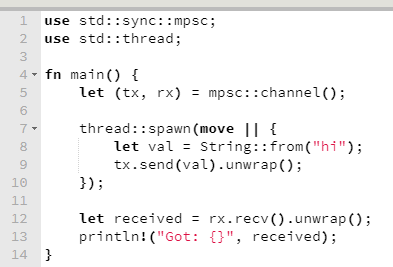
A Web Workers API torna possível que um script rode em background, em uma thread separada da thread principal da aplicação web. Isto é fantástico, porque assim a thread principal, que é a responsável pela UI, fica livre para interagir com o usuário enquanto a thread do web worker executa seu trabalho custoso e potencialmente demorado.
The main thread is where a browser processes user events and paints. By default, the browser uses a single thread to run all the JavaScript in your page, as well as to perform layout, reflows, and garbage collection. This means that long-running JavaScript functions can block the thread, leading to an unresponsive page and a bad user experience. ⎼ Main thread, MDN Web Docs Glossary.
Figura 1: As diferentes threads da aplicação, dado o uso de web workers.
Há três tipos de workers:
Dedicated — são usados por apenas um único script;
Shared — podem ser usados por múltiplos scripts, que podem estar rodando em diferentes janelas, iframes, etc, desde que estejam no mesmo domínio. Naturalmente, estes são um pouco mais complexos que os dedicados;
Service — são fundamentalmente proxies, que se colocam entre a aplicação web, o navegador e a rede. O grande objetivo deles é criar aplicações que possam rodar offline (PWA), porque eles podem interceptar requisições de rede, lidar com falhas de rede, fazer cache de conteúdo, acessar push notifications, rodar tarefas em background, entre outras coisas.
Para brevidade deste post, vamos tratar apenas de workers dedicados. Em um futuro post, podemos explorar um dos outros dois tipos ⎼ ou quem sabe os dois.
Em termos práticos, um web worker é um objeto do tipo Worker, que recebe como argumento obrigatório de construção um script, que precisa obedecer à regra de mesma origem. Opcionalmente, você pode passar também um segundo argumento, um objeto options com três atributos do tipo string: type, credentials e name. (Nosso script downloader.js brinca com o atributo name. Você vai ver isso mais adiante, quando checar o projeto de exemplo. Oops! Spoiler. Urgh!)
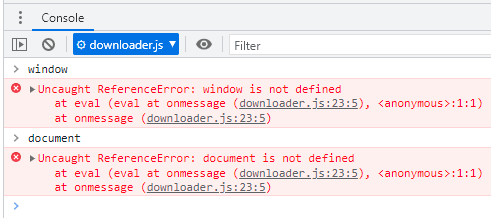
Mas por uma questão de thread safety, workers não tem acesso às famosas variáveis globais window e document, porque não possuem acesso à DOM API, uma vez que a thread principal é quem é a responsável pela UI.
Figura 4: Workers não tem acesso a window e document.
Okay, muito bem. Mas espere. Hmmm. Como é que eu faço então quando preciso fazer alguma modificação na página atual, por exemplo, sei lá, esconder uma div ou mostrar uma imagem?
Ótima pergunta! E para respondê-la, vamos explorar um pouco a interação entre o script principal e um dado worker. Você vai ver que tudo vai ficar evidente daqui um pouquinho.
Um objeto Worker tem basicamente um método e dois eventos que nos interessam, no propósito desta discussão.
Figura 5: Instância de worker, do lado do script principal.
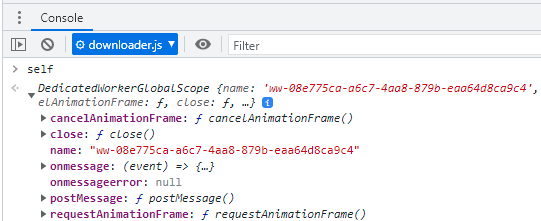
Agora, do lado do worker, vamos dar uma inspecionada na propriedade read-only self, que refere-se à instância do worker em si (repare na Figura 1 que “this” está undefined). O que nos importa deste lado é o seguinte:
Basicamente, a mesma coisa, né? Típico de um modelo do comunicação baseado em troca de mensagens.
Pois muito bem, com essas informações em mãos, você já deve ter deduzido como é que essa interação entre script principal e worker funciona, né?
Quando o script principal quer falar com o worker, ele lhe envia uma mensagem usando o método postMessage(). O worker, por sua vez, quando recebe uma mensagem do script principal, a consome através do evento onmessage. E vice-versa.
Figura 7: Os eventos de erro dispensam explicações.
O evento onmessage é onde o heavy lifting de fato acontece. Pode ser uma computação custosa, um pré-processamento, um cacheamento de recursos, ou qualquer outra operação potencialmente demorada que pode bloquear a UI e dar aquela sensação de travamento na página web.
Cache API
A Cache API oferece uma interface para o mecanismo de persistência do browser específico para pares de Request/Response, que ficam disponíveis tanto em escopo de janela quanto de worker.
Esse tipo de persistência é o que chamamos de “long lived memory” e sua implementação é totalmente dependente do navegador. Aliás, aproveitando o assunto “dependente do navegador”, a Dona Prudência recomenda que você teste sua feature pelo menos nos principais navegadores onde ela deve ser suportada, especialmente, quando se tratar de dispositivos móveis. Do contrário, há uma grande chance do Senhor Lamento lhe fazer uma visita, digamos, não muito amigável. Voltemos ao lance do storage agora.
Além da API de Cache, há ainda alguns outros serviços que usam a Storage API, mecanismo de persistência de dados do navegador, como por exemplo:
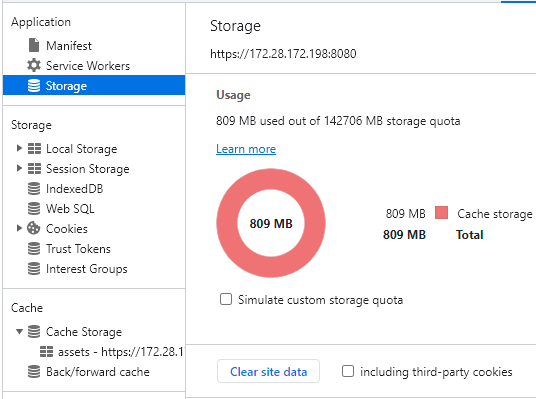
Figura 8: Quota de armazenamento de uma aplicação web rodando no Chrome, em um desktop Windows.
Agora, quanto ao tamanho desse espaço disponível, a documentação MDN Web Docs começa dizendo mais ou menos o seguinte: “olha só, pessoal, existem diversas maneiras do browser armazenar dados localmente e o processo pelo qual ele faz isso ⎼ calcular quanto espaço usar e quando liberar ⎼ é complicado e varia de browser para browser”. Super esclarecedor. Mas depois ela fica menos vaga e dá algumas informações mais concretas, que vou resumir aqui:
A espaço máximo é dinâmico, baseado no espaço livre em disco;
O limite global é essencialmente 50% do total livre do disco;
Quando o espaço livre é atingido, acontece um processo de limpeza baseado na origem, a.k.a.origin eviction;
A limpeza é por origem ⎼ não é seletivo quanto ao conteúdo “dentro” da origem ⎼, para evitar problemas de inconsistência.;
Há também um group limit, que é de 20% do limite global, sendo que o mínimo é 10 MB e o máximo 2 GB (de um modo geral, o group limit é por domínio raíz e a origem por domínio absoluto);
Se você quiser se inteirar um pouco mais sobre essa questão de espaço disponível para armazenamento e tudo mais, o que eu lhe encorajo a fazer, para poder planejar sua estratégia de origem de conteúdo, recomendo este post: Estimating Available Storage Space. Ele já é um tanto velhinho, para “os padrões da interwebs”, mas vale a pena.
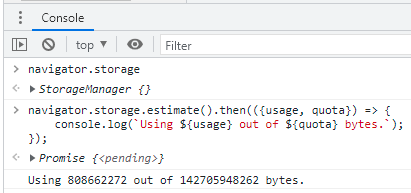
Figura 9: TL;DR script para estimar espaço disponível para persistência.
Que tal se aproveitarmos o ensejo do snippet da Figura 9 e partirmos para ver um pouco de código daqui em diante?
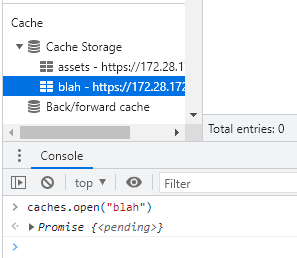
Uma aplicação web pode ter mais de um cache “nomeado” (o que pode ser interessante para agrupar conteúdo baseado em algum critério) e você precisa abri-lo antes de poder usá-lo. Caso ainda não exista um cache com o nome que você especificou ao tentar abri-lo, um novo será criado automaticamente.
Figura 10: Criação “automática” de um cache chamado “blah”, que não existia até então.
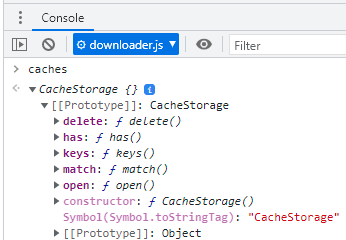
Como você deve ter percebido na Figura 10, para ter acesso à Cache API, o ponto de entrada é a propriedade read-only global caches, que é do tipo CacheStorage, e oferece alguns métodos fundamentais para seu uso típico.
Figura 11: O ponto de entrada para o uso da Cache API e seus métodos.
Os métodos da CacheStore são todos assíncronos e retornam uma Promise. No caso do método open(), ela resolve para o objeto Cache que se está querendo usar, pronto para uso.
Figura 12: Abrindo para uso um dos caches da aplicação.
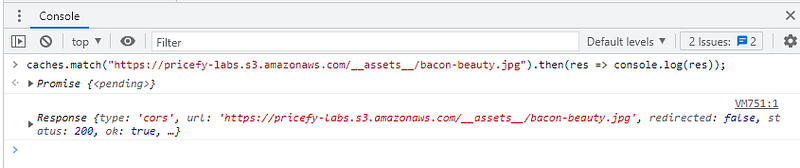
Uma vez que você tenha um objeto Cache na mão, você pode então procurar por uma determinada URL. Para fazer isso, você usa o método match(), cujo primeiro argumento é uma URL ou um objeto Request, e resolve para um objeto Response. Esse método tem ainda um segundo argumento, com algumas opções interessantes para configuração dos critérios da busca.
Okay. Aqui tem um detalhe que acho que vale a pena comentar.
Há pouco, eu disse que uma aplicação pode ter mais de um cache “nomeado”, não foi? Pois é. E eu também disse que você precisa abri-lo antes de usá-lo, né? Então, nhmmm, isso é semi-verdade.
Em vez de usar caches.open(“assets”) para abri-lo e depois cache.match(“https://blah.com/tldr.png”) para recuperar o response cacheado, você pode simplesmente usar caches.match(“https://blah.com/tldr.png”). A diferença, pegando este atalho, é que a busca não é feita “em um cache específico”, mas em todos. Ou seja, há um custo extra na busca.
Figura 13: Atalho para obter um objeto response do cache.
Tem mais uma coisa que acho importante comentar, que é o seguinte: diferente de alguns mecanismos de cache onde você define o tempo de expiração de um objeto e o mecanismo de cache faz o resto, aqui, você tem que deletar um objeto quando quiser revogá-lo. O mesmo vale para mantê-lo atualizado ⎼ isso é por sua conta.
Com esse recurso, você pode cachear retornos de API que não mudam com tanta frequência, imagens/vídeos de um slideshow agendados para rodar mesmo quando a rede estiver offline ⎼ pense em uma computação prévia disso, baseada no escalonamento de cada imagem ou vídeo.
Ah, sim, claro! Que bom que você notou. A interface desse projeto é super “vintage”. Thanks for asking me.
Figura 14: Yeah, this is me. Annnd the code you want me to show you.
Eu recomendo bastante que você, além de ler o código, também baixe o código na sua máquina e bote a aplicação para rodar, faça debug dela e observe o que acontece no console e nas abas network e application. Isso vai te ajudar a entender todo o mecanismo discutido até aqui. Afinal de contas, trata-se de um exemplo educativo, então, você tem que botar as mãos nele e experimentar por conta própria.
Tendo dúvidas, não hesite em me contactar.
Conclusão
A ideia desse post foi explorar um pouco dois recursos oferecidos pelos navegadores modernos, Web Workers e Cache API, para melhorar a experiência dos usuários humanos das suas aplicações, que não suportam esperar mais do que 3 segundos pelo carregamento de uma página web. E além disso, esses recursos também podem ser usados para criar aplicações que sejam tolerantes a indisponibilidades de rede e funcionem offline.
Há cerca de um mês, tive o prazer de apresentar um webinar da Pricefy, falando sobre programação assíncrona com C# .NET. Na ocasião, apresentei conceitos fundamentais de multithreading, I/O assíncrono, Task-based Asynchronous Programming, mostrei como async/await funciona por baixo dos panos e finalizei com código (é lógico!), mostrando exemplos de mau uso de async/await e como usar isso do jeito certo. O conteúdo está bem didático, tenho certeza que mesmo quem não é da turma do C# pode aprender uma coisa ou duas.
Durante o webinar, fiz questão de deixar claro que há uma distinção entre o que são tarefas assíncronas e o que são tarefas paralelas. Muito embora, sejam frequentemente usadas em conversas corriqueiras como sendo a mesma coisa, elas não são a mesma coisa.
Obviamente que uma discussão exaustiva sobre o assunto está fora da agenda deste post. Mas vou fazer uma nano desambiguação aqui, para então seguir com o assunto alvo deste post.
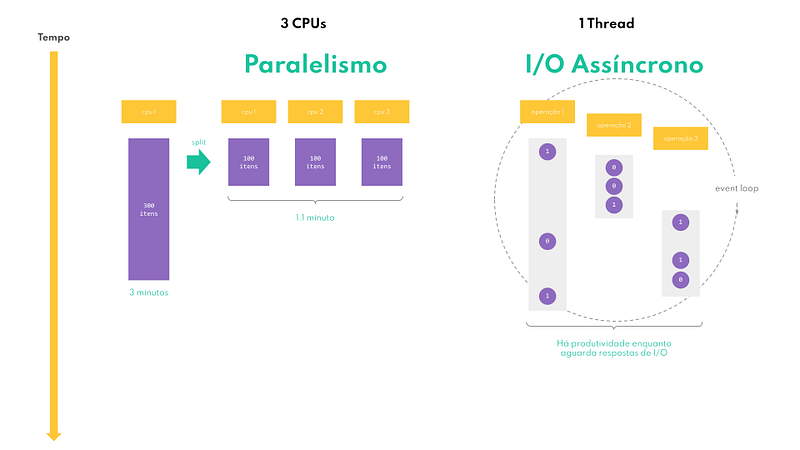
Consideramos paralelismo quando temos uma tarefa que leva um certo tempo para ser concluída e desejamos completá-la em menos tempo. Para isso, o requisito basilar é que a tal tarefa seja passível de ser dividida em múltiplos pedaços iguais (ou bem próximo disso) e que se tenha um número de unidades de trabalho de igual capacidade, para que possam trabalhar ao mesmo tempo e com equivalente desempenho.
Um exemplo cotidiano de paralelismo seria dividir a tarefa de descascar 3 kg de batatas entre três pessoas de igual habilidade (e força de vontade!). Digamos que você sozinho leve 3 horas para concluir a tarefa. Okay, o problema é que o jantar é daqui há 1 hora e meia. O que fazer? Dividir a tarefa com aqueles dois amigos que estão sentados no sofá, sem fazer nada, enquanto você prepara tudo sozinho? Sim, essa é uma ideia. Se os dois tiverem a mesma habilidade de descascar batatas que você tem, em aproximadamente 1 hora a tarefa estará concluída e você poderá partir para a próxima ⎼ assar, cozer, fritar, ou o que quer que seja.
Em termos de software, o princípio é o mesmo. Digamos que você tenha, por exemplo, uma lista com 300 itens e tenha que realizar uma determinada operação em cada um deles. Se você tiver três CPUs em seu computador, você pode dividir a lista em três e processar ⅓ em cada CPU.
“Most modern CPUs are implemented on integrated circuit (IC) microprocessors, with one or more CPUs on a single metal-oxide-semiconductor (MOS) IC chip. Microprocessors chips with multiple CPUs are multi-core processors. The individual physical CPUs, processor cores, can also be multithreaded to create additional virtual or logical CPUs.” — Wikipedia.
Note que eu disse “CPU” e não “thread”. Isso porque o paralelismo “de verdade” é obtido com múltiplas CPUs executando threads ao mesmo tempo e não com múltiplas threads sendo escalonadas por uma única CPU. Com múltiplas threads em uma única CPU, temos o que é conhecido como multitarefas “virtualmente simultâneas”.
Por exemplo, quando eu digito algo no teclado do meu computador e como amendoins “ao mesmo tempo”, no grande esquema das coisas, digamos, em uma janela de 10 minutos, alguém pode dizer que estou comendo amendoins ao mesmo tempo em que digito coisas no computador; mas na real, encurtando essa janela de tempo, é possível ver que eu não faço as duas coisas exatamente ao mesmo tempo, mas sim, intercaladamente, mudando de uma tarefa para a outra a cada certo intervalo.
É basicamente assim que as threads funcionam: elas são como “unidades de processamento virtuais”, que uma CPU executa com exclusividade por 30 milissegundos cada. Humanamente falando, imagino que seja impossível perceber essa mudança de contexto; por isso, tudo parece realmente simultâneo para nós.
Assíncrono vs Paralelo
Já no caso da assincronicidade, consideramos assíncrono aquilo que não vai acontecer do início ao fim exatamente agora, que pode ter um curso intermitente, e não queremos ficar sem fazer nada enquanto esperamos por sua conclusão, que acontecerá em algum momento futuro. Isso é tipicamente comum com operações de I/O.
Operações de I/O não dependem apenas de software, obviamente, mas invariavelmente de dispositivos de I/O (a.k.a. hardware), que de algum modo compõe ou complementam um computador, cada qual com seu modo de funcionar, seu tempo de resposta e outras particularidades quaisqueres. Alguns dos dispositivos de I/O mais comuns são: HD, monitor de vídeo, impressora, USB, webcam e interface de rede. Qualquer programa de computador que valha seu peso em sal executa alguma operação de I/O ⎼ mostrar “hello world” em uma tela, salvar um texto qualquer em um arquivo, iniciar um socket de rede, enviar um e-mail, etc.
Voltando à cozinha para mais um exemplo, digamos que o jantar de hoje seja macarrão à bolonhesa e salada verde com tomates cerejas e cebola. Como poderia acontecer a preparação desse cardápio? Bom, eu poderia fazer uma coisa de cada vez, de modo sequencial. Ou poderia tentar otimizar um pouco meu tempo, minimizando o tempo que fico sem fazer nada, aqui e ali, esperando por algum “output” qualquer.
Eu começo colocando uma panela de água para ferver, onde vou cozer o macarrão. Enquanto ela não ferve, eu corto cebola, alho e bacon para refogar a carne moída;
Terminando, a tarefa de pré-preparo, sequencialmente, enquanto ainda espero a água para o macarrão chegar à fervura, começo então a preparar a carne moída ⎼ refogo, coloco temperos diversos, extrato de tomate e deixo cozer em fogo médio;
Vejo que a água começou a ferver, então, acrescento um tanto de sal e ponho o macarrão para cozer. Okay, agora, enquanto o macarrão cozinha por aproximadamente 8–10 minutos e a carne moída também está cozendo, apurando o sabor, o que eu faço? Sento e espero? Não! Ainda tenho que preparar a sala;
Lavo as folhas verdes, os tomates, corto a cebola, junto tudo em uma saladeira (trriiimmm!!!) ouço o alarme indicando que o macarrão está cozido e é hora de escorrê-lo rapidamente, mesmo que tenha que parar o preparo da salada, momentaneamente, afinal de contas, só falta temperar e isso não é algo tão crítico, pode acontecer daqui um pouco; já o macarrão, precisa ser escorrido agora!
Escorro o macarrão, coloco em uma travessa de macarronada, despejo a carne moída por cima, misturo cuidadosamente e finalizo ralando uma generosa quantidade de queijo parmesão por cima;
Levo a travessa de macarronada para a mesa de jantar, volto à cozinha, tempero a salada rapidamente e levo para mesa também;
Tá na mesa, pessoalll!!!
Vê como tudo aconteceu de modo predominantemente assíncrono, porque cada preparo teve seu tempo e sua prioridade? Tudo aconteceu de modo intercalado. Foram 40 minutos intensos, sem ficar um minuto parado sem fazer nada, mas aproveitei muito melhor o meu tempo.
É basicamente assim que funcionam as operações de I/O assíncronas: uma única thread é capaz de despachar milhares de operações de leitura ou escrita para os diversos dispositivos de hardware de um computador, conforme as requisições vão chegando; e enquanto as respostas dos dispositivos não chegam, indicando que as operações foram bem sucedidas ou não, elas vão atendendo a outras requisições; e assim seguem, em um loop semi-infinito.
Por que uma thread ficaria parada, bloqueada, esperando pela resposta de uma escrita em um socket, que pode levar certo tempo, enquanto poderia estar escrevendo algo em um arquivo no disco rígido? Essa é a magia do I/O assíncrono in a nutshell. Depois, assista à minha talk no YouTube, que lá eu me aprofundo mais no assunto; não quero me repetir aqui.
Como você provavelmente já notou, tanto a abordagem paralela, quanto a assíncrona, são maneiras de se implementar concorrência em uma aplicação, cada qual com sua finalidade. A primeira, envolve threads de execução em múltiplas CPUs simultâneas; a segunda se baseia em máquinas de estado, futures e callbacks, executando possivelmente em uma única thread.
Espero que essa introdução tenha sido suficiente para ficarmos todos na mesma página.
Paralelismo está no menu hoje
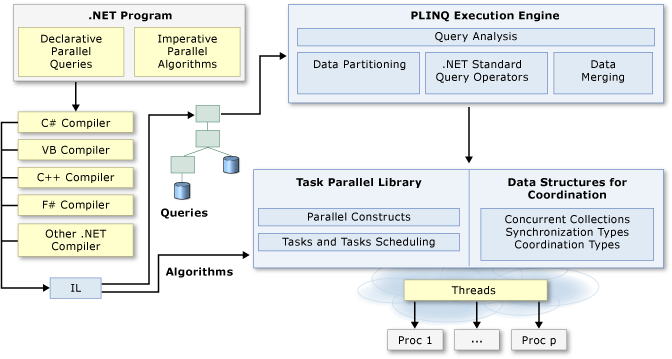
O assunto da vez hoje é paralelismo com C#. E para continuar se aprofundando no assunto, uma visão de alto-nível da arquitetura de programação paralela oferecida pela plataforma .NET.
Eu acho importante começar com essa big picture, porque infelizmente, a plataforma .NET não ajuda muito com aquela distinção de assíncrono vs paralelo, que vimos há pouco. A razão disso é que a classe Task é o ponto de partida da Task Parallel Library (TPL) tanto para algoritmos assíncronos quanto para paralelos.
A documentação sobre Task-based Asynchronous Programming (TAP) define “task parallelism” como “uma ou mais tarefas independentes executando concorrentemente”, o que soa um pouco fora do que vimos há pouco.
Já a documentação sobre Parallel Programming in .NET (fonte do diagrama acima), por sua vez, diz que “muitos computadores pessoais e estações de trabalho têm vários núcleos de CPU que permitem que várias threads sejam executadas simultaneamente”, e então, conclui dizendo que “para aproveitar as vantagens do hardware, você pode paralelizar seu código para distribuir o trabalho entre vários processadores”. Isso faz mais sentido para mim.
Uma dica de ouro, que para mim ajuda bastante, é olhar para a classe Task sob a ótica daquilo que tenho a intenção de implementar.
Os membros .Result, .Wait(), .WaitAll(), .WaitAny() são bloqueantes (a.k.a. síncronos) e devem ser usados somente quando se tem a intenção de implementar paralelismo. Tarefas paralelas estão relacionadas ao que chamamos de CPU-bound e devem ser criadas usando preferencialmente os métodos .Run() e .Factory.StartNew();
Além da palavra-mágica await, usada para aguardar assíncronamente a conclusão de um método assíncrono (na prática, uma instância de Task ou Task<T>), os métodos .WhenAll() e .WhenAny(), que não são bloqueantes (a.k.a. assíncronos), devem ser usados quando a intenção for implementar assincronicidade. Tarefas assíncronas estão relacionadas ao que chamamos de I/O-bound.
A propósito, TaskCreationOptions.AttachedToParent pode ser usada na criação de uma tarefa paralela (estratégia “divide and conquer” / “parent & children”), mas não por uma tarefa assíncrona. Tarefas assíncronas, de certo modo, já criam sua própria “hierarquia” via await.
Okay, vamos focar em paralelismo a partir daqui e ver um pouco de código.
Colocando a mão na massa
Como vimos há pouco, tarefas paralelas vão bem para implementar processos que sejam CPU-bound; ou seja, que levam menos tempo para conclusão em função do número de CPUs disponíveis para particionamento/execução do trabalho.
Podemos dividir esse cenário em duas categorias de processamento:
Estático — data parallelism
Dinâmico — task parallelism
Processamento paralelo “estático”
Chamamos essa categoria de estática, porque se trata de iterar uma coleção de dados e aplicar um dado algoritmo em cada um de seus elementos. Para isso, a TPL nos oferece três métodos a partir da classe Parallel.
Repare nos parâmetros passados na invocação do método Parallel.For(), na linha 14. Além dos típicos limites inicial e final, há também uma Action<int, ParallelLoopState>, que provê o índice da iteração atual e um objeto com o estado do loop. É a partir deste objeto de estado que solicitamos um “break” no loop.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Uma outra coisa a se notar é o seguinte: diferente de um loop for clássico, que acontece sequencialmente, este Parallel.For() pode ter sido escalonado para rodar em múltiplos processadores simultaneamente; portanto, um break não é imediato, evitando que a próxima iteração aconteça. Pelo contrário, é bem provável que um número de iterações tenham sido iniciadas em um breve momento anterior ao .Break() ser invocado. É por isso que, na linha 19, precisamos checar se podemos ou não continuar a iteração atual.
E finalmente, note que na linha 32 há um lock da variável random. Isso é necessário por se tratar de um processo paralelo, que vai potencialmente mutar essa variável concorrentemente ao longo das iterações. Idealmente, você vai evitar esse tipo de cenário, porque onde há lock, há contenção; e onde há contenção, há tempo despendido esperando. Você não quer isso, mas às vezes é preciso.
— A little break here —
Acho que esse é o momento ideal para dizer que paralelismo pode criar situações de concorrência, intencional ou acidentalmente, dependendo do que você está implementando — porque programação paralela é um tipo de multithreading; e multithreading é um tipo de concorrência.
Se você ficou com dúvidas sobre isso, se ficou confuso com a terminologia, se acha que é tudo a mesma coisa, ou algo assim, tudo bem, não se desespere. Eu sei que, como acontece com assincronicidade e paralelismo, concorrência e paralelismo também são confundidos o tempo todo.
O artigo da Wikipedia sobre concorrência (em inglês) traz um ótimo resumo do Rob Pike, que distingue bem uma coisa da outra: “Concurrency is the composition of independently executing computations, and concurrency is not parallelism: concurrency is about dealing with lots of things at once but parallelism is about doing lots of things at once. Concurrency is about structure, parallelism is about execution, concurrency provides a way to structure a solution to solve a problem that may (but not necessarily) be parallelizable.”
Se tiver um tempo extra, recomendo que você veja a apresentação do Rob Pike, Concurrency is not Parallelism, para ter uma introdução amigável ao assunto.
Semelhantemente ao que se pode fazer com um loop foreach, aqui, Parallel.ForEach() está recebendo um IEnumerable<int> provido por um generator (a.k.a.yield return). Além deste parâmetro, há ainda outros dois: um com opções de configuração de paralelismo e uma Action<int, ParallelLoopState, long>, que pode ser usada como no exemplo anterior.
O ponto de destaque neste exemplo vai para a linha 29, onde é definido um CancellationToken para o loop. Naturalmente, o objetivo do CancellationToken é sinalizar o cancelamento de um processo que está em curso. E neste caso, o cancelamento ocorre na linha 18, depois de um intervalo randômico ⎼ to spice it up.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Este é um pattern bastante comum na plataforma .NET, que você já deve estar bem acostumado, pois se vê isso por toda parte da biblioteca padrão.
3. Invoke() ⎼ neste caso, a coleção iterada é de algoritmos
Este caso é um pouco diferente dos dois anteriores. Nos casos anteriores, o problema que você estava querendo resolver era o seguinte: você tinha uma coleção de itens sobre os quais você queria aplicar um dado algoritmo, e para fazer isso o mais rápido possível, você queria tirar proveito do número de CPUs disponíveis e escalonar o trabalho entre elas.
Agora, neste caso, o problema é que você tem um número de algoritmos para executar (independentes uns dos outros, de preferência) e gostaria de fazer isso o mais rápido possível. A solução, no entanto, é essencialmente a mesma.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Um bônus no código acima, que não tem exatamente a ver com a questão do .Invoke(), mas que é super interessante e vale a pena comentar, é o método .AsParallel() sendo invocado no long[], na linha 13. Este método é parte da chamada Parallel LINQ (PLINQ), que torna possível a paralelização de queries LINQ.
Como você já deve imaginar, o que a PLINQ faz é particionar a coleção em um número de segmentos, e então, executar a query em worker threads separadas, em paralelo, usando os processadores disponíveis.
A propósito, assim como os dois métodos anteriores, .Invoke() também suporta CancellationToken via ParallelOptions.
Processamento paralelo “dinâmico”
Chamamos essa categoria de dinâmica, porque não se trata de iterar em uma coleção e aplicar um determinado algoritmo; também não se trata de invocar uma lista de métodos em paralelo. Na verdade, trata-se de iniciar uma nova Task (ou mais de uma), que vai executar um processo custoso em uma worker thread, em paralelo, se possível, e poderá iniciar outras Tasks “filhas” a partir dela, criando uma hierarquia, onde a tarefa mãe só será concluída quando suas filhas tiverem concluído.
Inicia, se divide, trabalha, converge e finaliza.
Essa é a uma categoria de paralelismo em que, questões como: quantas tarefas mães, quantas tarefas filhas, que processos cada uma delas realiza, em que circunstâncias, em que ordem, etc, etc, etc, são todas respondidas em runtime, de acordo com as regras xpto de cada caso de uso. Daí referir-se a ela como dinâmica.
Os métodos da classe Parallel e a PLINQ são super amigáveis, convenientes, e você deve tentar usar sempre que possível. Mas quando o problema for um tanto mais flexível, dependente de informações conhecidas somente em runtime, o negócio é partir para Task. Por exemplo, você precisa percorrer uma estrutura de árvore e, dependendo do nó, executar um processo ou outro.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Note que o exemplo acima usa o método Task.Factory.StartNew(), para criar e disparar a execução de instâncias de Task, e não o famoso Task.Run(), que estamos bem acostumados a usar, quando estruturamos aplicações para lidar com problemas de modo concorrente.
O caso é que, o método .Run(), na real, nada mais é do que uma maneira conveniente de invocar.StartNew() com parâmetros “padrões” (veja o fronte dele aqui). E como você já deve imaginar a essa altura do campeonato, é justamente por conta desses parâmetros “padrões” que ele não atende aos requisitos do exemplo acima. Bem, para ser mais específico, estou me referindo ao parâmetro TaskCreationOptions.DenyChildAttach, que nos impede de ter tarefas filhas. Quer testar isso? Substitua .StartNew() por .Run() na linha 12, ou então, o parâmetro TaskCreationOptions.None por TaskCreationOptions.DenyChildAttach, na linha 15, e veja o que acontece ⎼ repare bem na ordem das saídas de console.
Viu?
A regra então é: sempre que for criar e disparar a execução de uma Task, priorize .Run(), a menos que o caso que você vai implementar peça por parâmetros específicos, diferentes dos padrões. Nestas circunstâncias, use .StartNew() e configure a gosto.
[Para ser mais correto com a informação que estou entregando, eu tenho que dizer que, nem o método .Run(), nem o método .StartNew(), “disparam” a execução de uma Task. O que eles fazem, na verdade, é “colocar a Task na fila de execução do ThreadPool, através de um TaskScheduler”. Veja que a própria classe Task tem uma propriedade Status que ajuda a entender seu o ciclo de vida.]
Dica #1 ⎼ Long Running Tasks
Podemos dizer que uma Task é long-running quando ela permanece rodando por minutos, horas, dias, etc. Ou seja, não é uma tarefa de alguns poucos segundos de duração. Para isso, há a opção TaskCreationOptions.LongRunning, que pode ser passada para o método .StartNew().
O que essa opção faz é sinalizar ao TaskScheduler que se trata de um caso de oversubscription, dando a chance do TaskScheduler se precaver contra um fenômeno conhecido como “thread starvation”. Para tanto, duas ações são possíveis ao TaskScheduler: (1) criar mais threads do que o número de CPUs disponíveis; (2) criar uma thread adicional dedicada à Task, para que assim, ela não engargale o fluxo natural de trabalho das worker threads do ThreadPool.
Até aí, tudo bem. Problema resolvido. Espere. Mesmo?
Tarefas com corpo async, ou seja, que seu delegate await por outras tarefas, por si só, naturalmente, já possuem um fluxo de execução escalonado de acordo com sua máquina de estado. Portanto, elas não consomem uma mesma thread por muito tempo; cada passo da máquina de estado pode ser executado em uma thread diferente.
Se você não sabe do que estou falando, veja a minha talk.
O que fazer então? A menos que seu processo long-running não use await, não aguarde a execução de nenhuma Task, seja lá de que maneira, esqueça a opção TaskCreationOptions.LongRunning. Use .Run() e deixe que o TaskScheduler faça seu trabalho autonomamente ⎼ em raros casos ele realmente precisa de “dicas”.
Dica #2 ⎼ Exceções
Sim, elas existem e uma hora ou outra vão ocorrer. Lide com isso. Quero dizer, literalmente!
Quando você estiver trabalhando com tarefas aninhadas, parent & children, como no exemplo que vimos há pouco, quando ocorrer uma exceção, você vai receber uma AggregateException borbulhando. Não importa se você await ou .Wait() a Task, uma AggregateException é o que você vai ter. Sendo assim, muito do que eu falo sobre o uso de .Wait() e exceções na minha talk não se aplicam a esse tópico de hoje. Mas isso não significa que você deva preferir .Await() em lugar de await ⎼ pelo contrário. Evite bloquear a “thread chamadora” desnecessariamente.
Uma dica para lidar com isso é usar o método .Flatten() da AggregateException. A grosso modo, o que esse método faz é criar uma única exceção com a exceção original incluída na propriedade InnerExceptions. Assim você não tem que ficar iterando por exceções aninhadas.
Programação paralela visa aumentar o uso das CPUs, temporariamente, com intuito de aumentar o throughput da aplicação. Ótimo! Queremos isso. Afinal, muitos desktops ficam com a CPU idle boa parte do tempo. Mas cuidado, porque isso não é sempre verdade quando se trata de servidores.
Servidores rodando aplicações ASP.NET, por exemplo, podem ter menos tempo de CPU idle, dependendo do volume de requisições simultâneas, porque o próprio framework lida com múltiplas requisições em paralelo, visando tirar melhor proveito do ambiente multicore disponível. Portanto, botar código que atende a requisições de clientes para rodar em paralelo, pode acabar sendo um baita de um tiro no pé, quando houver um grande volume de requisições simultâneas.
Via de regra, muito cuidado com multithreading em aplicações web.
Concluindo
Ao longo deste mais do que longo post, diferenciamos tarefas assíncronas de tarefas paralelas, nos aprofundamos nas paralelas e vimos algum código para ilustrar a discussão. Também vimos que concorrência não significa necessariamente paralelismo. Mas pode vir a ser, eventualmente.
Se você chegou até aqui e gostou, por favor, compartilhe com seus amigos, deixe seu comentário, suas dúvidas, e vamos nos falando.
Se mesmo tendo visto o meu webinar, você ainda tiver dúvidas sobre async/await, bota suas dúvidas aqui nos comentários. Quem sabe não consigo te ajudar? Não custa tentar.
Ah! E por falar em webinar, talvez eu faça um webinar discutindo o conteúdo deste post. Ou talvez me aprofunde mais no assunto concorrência, algo nessa linha. Seria a última peça do quebra-cabeças. Vou pensar a respeito.
Até a próxima!
—
BTW, estamos contratando 🙂
Se você ainda não conhece a nossa stack e quer saber como você poderia nos ajudar a construir a Pricefy, que foi recentemente adquirida pela Selbetti, dá uma checada nesses bate-papos:
ProdOps ⎼ Engenharia e Produto com Leandro Silva (link 1 e link 2);
ElvenWorks ⎼ Conhecendo a tecnologia por trás de uma solução muito inteligente de Precificação (link).
Desde março de 2018, eu vinha vendo uma coisa aqui, outra ali, sobre a linguagem Rust, após ter visto a apresentação do Florian Gilcher na GOTO 2017, intitulada “Why is Rust successful?”, mas nada realmente sério. Me lembro de ter ficado especialmente empolgado com duas talks do Bryan Cantrill, uma na QCon 2018, “Is it Time to Rewrite the Operating System in Rust?”, em junho de 2019, e outra em um meet up, “The Summer of Rust”, alguns dias depois, mas ainda assim, nada de pegar um livro para ler, de rabiscar algum código.
Histórico do YouTube #1 – Primeiro contato com Rust
Na época eu até tinha uma desculpa compreensível: tinha acabado de completar um bacharelado de Nutrição. Sim, isso mesmo. Quatro anos em uma sala de aula há 17km de casa, lendo um tanto de livros, artigos científicos; fazendo trabalhos, estudando para provas, apresentando seminários; estágios de 6 horas diárias em dois hospitais, uma clínica de nutrição esportiva e uma escola de educação infantil; e ainda o fadigante TCC sobre a relação entre nutrição e depressão. Tudo isso enquanto ajudava a construir a Pricefy do zero.
Dá para imaginar que o tema do TCC veio bem a calhar.
Histórico do YouTube #2 – Talks que por um momento me empolgaram
Mas então virou o ano, chegou 2020, a fadiga mental diminuiu significantemente e resolvi gastar algum tempo com Rust, estudar com um pouco mais de dedicação, rabiscar uns programas, experimentar por mim mesmo e não ficar somente no que vejo da experiência dos outros.
Esse post é para registrar um pouco das minhas impressões até aqui.
Rust, a linguagem
Não quero, aqui, dar uma introdução à linguagem, porque já existe uma documentação oficial maravilhosa, muito material educativo disponível gratuitamente, pois isso seria um tanto redundante.
O que é importante se ter em mente, a princípio, é que Rust foi criada com o objetivo de ser uma linguagem de sistema, para ser usada em casos de uso onde normalmente se usaria C/C++, como: drivers, sistemas embarcados, microcontroladores, bancos de dados, sistemas operacionais; programas que vivem extremamente próximos ao hardware, que requerem alta performance, com baixo consumo de memória e overhead de execução próximo de zero.
Portanto, algumas decisões de design foram:
– Ser compilada para binários nativos; – Ter um sistema de tipos estático, forte e extensível; – Não ter coletor de lixo; – Ter um sistema seguro de gestão de memória; – Ser imutável por padrão; – Dar suporte a concorrência imune a data races e race conditions; – Ter checagem de uso de memória em tempo de compilação; – Permitir código “não seguro”, quando explicitamente desejado; – Oferecer tratamento de erro simples, mas robusto; – Ter um ótimo ferramental de desenvolvimento.
Dentre outras coisas. Esta não é uma lista exaustiva. Mas é o suficiente para contextualizar o que vou falar sobre minhas impressões.
Em poucas palavras, eu diria que o objetivo principal era que ela fosse uma linguagem de baixo nível, extremamente performática, porém absolutamente segura e produtiva.
Vamos então à minhas impressões.
O Compilador
Eu fiquei realmente pirado no compilador. Não, é sério. Tendo gastado boa parte dos últimos anos programando em C#, JavaScript, Go e Python, acho que não preciso dizer muito mais.
Mas vamos ver um exemplo:
O que nos diria o compilador sobre este programinha?
Hmm? E você, o que me diz?
Ao longo do post vão aparecer mais exemplos legais da atuação do compilador, portanto não vou me prolongar aqui.
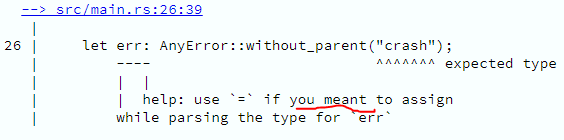
Imutável por natureza
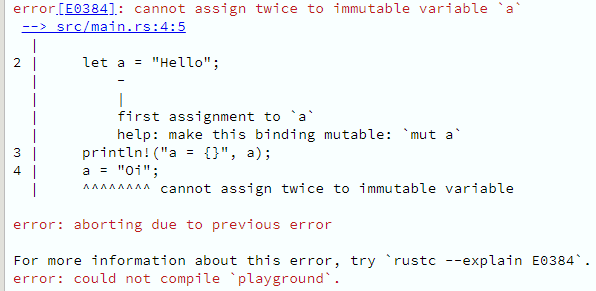
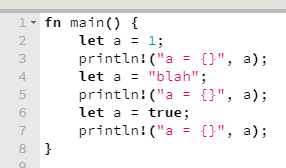
Variáveis são sempre imutáveis, a menos que explicitamente dito que não, como no caso que vimos há pouco.
Isso favorece o desenvolvimento de código concorrente seguro, o que há muito tem sido um dos principais atrativos de linguagens funcionais – ou melhor dizendo, do paradigma funcional de programação.
Não há porque temer o compartilhamento de valores que não mudam; aliás, que não podem ser modificados. Nenhuma linha de execução vai crashear esperando que a seja "Hello", quando na verdade, agora, a é "Oi".
Possessiva, porém generosa
Agora, espere. O que aconteceria se seguíssemos a sugestão do compilador e tornássemos a variável a mutável?
O efeito colateral seria observado. A variável a poderia ter seu valor modificado e os prints refletiriam isso.
Primeiro porque ela teria sido explicitamente anotada como mutável. Justo. E depois, porque a macro println! faz parte de uma família de casos específicos de macros, em que o parâmetro é implicitamente tomado por referência (a.k.a. borrowing), por questão de conforto, praticidade, mas não causam efeitos colaterais neles.
Okay. Isso coloca em cheque o que vimos no tópico anterior, não? Nhmm… não tão depressa.
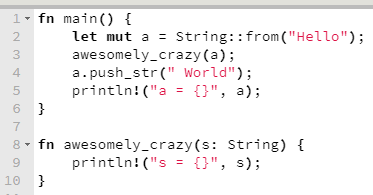
Vamos modificar um pouco o exemplo anterior e ver o que aconteceria em uma função que recebe uma variável não por referência, como é o caso da macro println!, mas por transferência de posse (a.k.a. ownership).
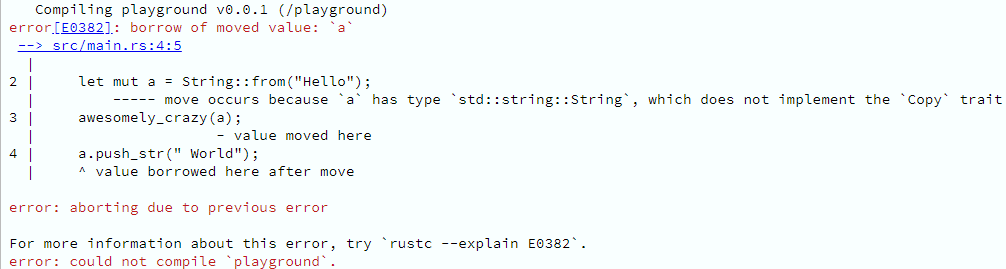
O compilador logo chia, dizendo que se está tentando emprestar o valor supostamente possuído pela variável a, para poder modificá-lo, enquanto este, na verdade, teve sua posse transferida para a função awesomely_crazy. Ou seja, o que quer que awesomely_crazy faça com o que recebeu, a variável a não tem mais nada a ver com isso.
O que acontece é que, em Rust, como você já deve ter percebido, um valor só pode ser possuído por uma única variável por vez; e quando o escopo em que esta está contida termina, seu valor é destruído. No entanto, essa posse pode ser cedida a outro.
Quem garante essa coisa de ownership, borrowing e lifetime em tempo de compilação é o chamado borrow checker, que muitas vezes se recusa a compilar um programa que você tem “certeza” que está tudo certo.
No nosso caso, somente a variável a era dona do valor "Hello" até ter transferido sua posse para a função awesomely_crazy. A partir de então, a função awesomely_crazy (nominalmente o parâmetro s) é quem passou a ser sua única proprietária; e ao final de sua execução, ao término de seu escopo, esse valor será destruído. É por isso que ele não pode ser emprestado novamente para modificação, através de a.push_str, ou mesmo emprestada para println!, que sequer modifica alguma coisa.
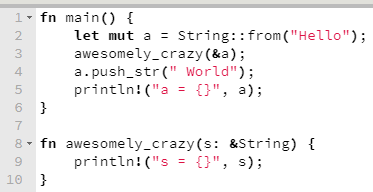
Portanto, se quisessemos fazer esse código compilar, teríamos que modificar a implementação da função awesomely_crazy, de modo que ela passasse a tomar o valor da variável a emprestado, por referência (& – C/C++ feelings, anybody else?), e não por posse.
Não haveria qualquer problema.
Mas note que awesomely_crazy toma o valor de a emprestado, por referência, mas não pode modificá-lo, como é o caso em outras linguagens. Se quiséssemos permitir que awesomely_crazy modifique o valor possuído pela variável a, teríamos que fazer um desencorajador malabarismo de mut, que provavelmente nos faria pensar um pouco mais no algoritmo que estamos tentando escrever.
Eu sei que tudo isso pode parecer complicado (e na prática é mesmo; tente implementar uma estrutura de dados recursiva, por exemplo), mas essas características da linguagem:
– Imutabilidade por padrão; – Mutabilidade por decisão explícita; – Posse exclusiva de valor; – Empréstimo de valor com restrições.
Com regras rigidamente observadas pelo compilador, são super interessantes na hora de escrever programas que rodam continuamente, por tempo indeterminado, sem crashear depois de devorar toda a memória disponível, por causa leaks; ou então, programas com processos concorrentes, que não crasheiam por conta de data races e race conditions.
Essa é a maneira de Rust possibilitar um runtime de alta performace, seguro para processos concorrentes, que não correm o risco de lidar com dangling pointers, data races, e ainda livres do overhead de um coletor de lixo para garantir isso.
Confesso que volta e meia ainda passo perrengue com isso e tenho que repensar meu código, mas isso tem acontecido cada vez menos e tenho gostado cada vez mais. O que realmente me deixa puto são certos casos de inferências, que penso pqp, como é que ele não consegue saber em tempo de compilação o quanto essa p@%$# vai consumir de memória.
Anyway. De qualquer forma, não existe null pointer em Rust e isso por si só já me deixa feliz.
Sintaxe, bizarra sintaxe
Olha quem está falando: alguém que gastou um tanto de horas de sua vida programando em Erlang. Okay. Não tenho muito o que reclamar.
Mas a real é que esse título é mais clickbait do que verídico.
A verdade é que eu gosto da sintaxe de Rust. Sempre fui fã de linguagens com sintaxe C-like, tipo: Java, JavaScript, C#, Scala, Go, e outras. Mas em todas essas linguagens sempre tem alguma coisa que acho chata, irritante ou bizarra. Às vezes as três.
No caso de Rust, o que acho bizarro é a anotação de escopo para ajudar na validação de tempo de vida de referências à memória. Como vimos anteriormente, não há coletor de lixo, então toda referência tem um tempo de vida baseado no escopo em que esta está contida. Terminado o escopo, essa referência é destruída e sua memória liberada. A maior parte do tempo, o compilador consegue inferir isso sem ajuda, mas às vezes, você precisa dar uma mãozinha, usando o chamado generic lifetime parameter, para garantir que em tempo de execução as dadas referências serão de fato válidas.
Side note – Olha o compilador aí, dando aquela ajuda Google-like
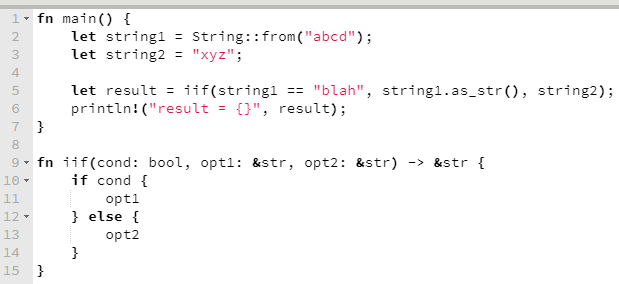
O código abaixo implementa um if-ternário sem sucesso, porque há uma ambiguidade sobre que referência será retornada.
O compilador, naturalmente, não gosta disso, diz o motivo e sugere uma solução.
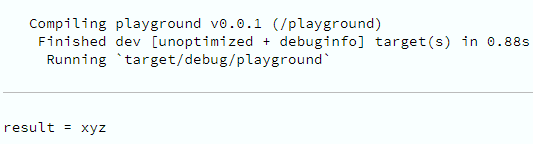
Implementada a solução sugerida; ou seja, anotado o escopo de vida do que a função recebe e do que retorna, para que a ambiguidade seja eliminada.
Vòila! O código compila e, a menos que tenha um erro de lógica, roda perfeitamente como esperado.
Tudo bem. Foi só uma anotaçãozinha. Mas isso porque também foi só uma funçãozinha. Imagine algo com escopo de vida um pouco mais completo, que precise de mais de uma anotação de lifetime e ainda outras anotações de tipos genéricos.
É, a coisa pode escalar bem rápido. Generics é um recurso fantástico, sem sombra de dúvidas, mas imagine isso na assinatura de uma função, que também tem outros parâmetros, e retorno, e… Pff!
Mas por outro lado, o lado bom, agora, é que há um recurso robusto de definição de tipos. Em lugar de escrever algo assim:
Você pode definir um tipo que defina essa especificação gigantesca, fazendo bom uso de generics e tudo mais; e inclusive, dar um nome para o que ela representa. Só espero que você seja melhor do que eu com nomes.
Vê? Com isso é possível tornar o código bem mais semântico, comunicar mais significado, porque no final das contas, você passa mais tempo lendo código do que escrevendo ou apagando código.
Side note – Outra vez, o compilador amigão
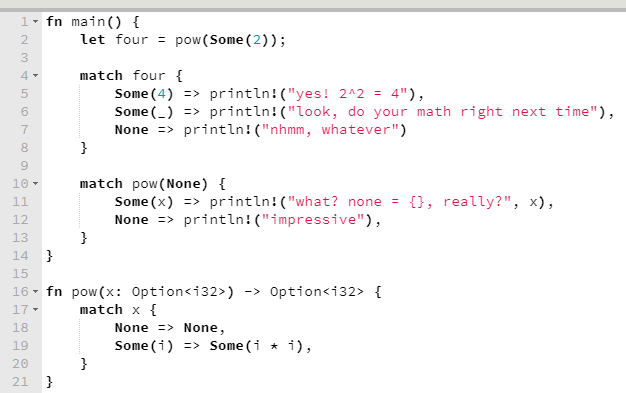
Pattern Matching e tratamento de erros
Quem me conhece e já trocou ideias de programação comigo, sabe que sou bem fã de pattern matching. Essa é uma das coisas que mais gosto em Erlang e é também uma das que mais gosto em Rust.
Lindo, não? Okay. Eu sei que estou exagerando um pouco.
Mas a questão é que este recurso, além de favorecer que se escreva código mais declarativo e com viés mais funcional, também encoraja o tratamento de erros mais simples, menos complicado.
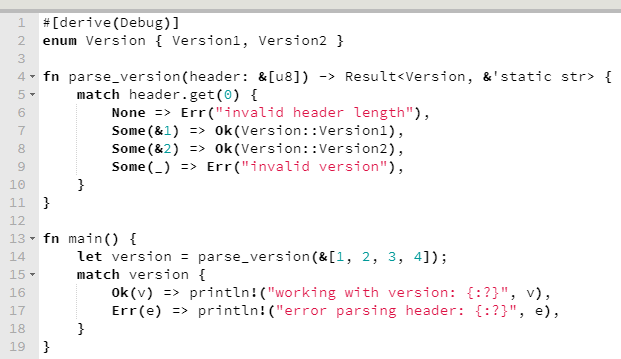
Em Rust, a forma idiomática de tratamento de erros é que o retorno de uma função seja uma enumResult, que pode conter o resultado do sucesso ou o famigerado erro.
Este é um exemplo que peguei da própria documentação da enumResult. Ele dispensa explicação, tão simples e declarativo que é.
Uma coisa interessante para se mencionar aqui, que tem tudo a ver com pattern matching e tratamento de erros, é que enums em Rust estão muito próximas do que em linguagens funcionais chamamos de tipos algébricos, o que favorece muito a expressividade do código.
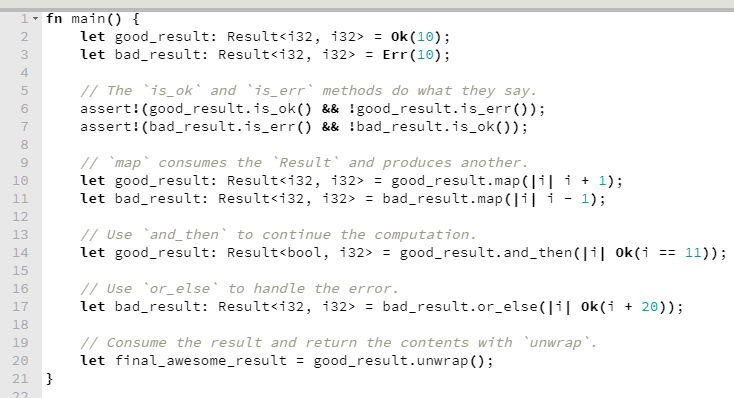
Okay. Mas voltando à Result e ao tratamento de erros, expandindo um pouco no exemplo acima, retirado da própria documentação, perceba que há uma série de funções bacanas, incluindo map e or_else.
De novo, essa é a maneira idiomática de se lidar com erros em Rust. Sim, existe uma macro panic!, muito parecida com o que há em Go, mas use com moderação.
Aliás, falando em Go, eu tenho que dizer que gosto bastante de Go e prova disso é que desde 2012 tenho estudado e feito Go aqui e ali, quando faz sentido. Dito isso, eu acho a forma idiomática de tratamento de erros super simples e compreensível, porém tosca e pobre. Nada sofisticada. Mas tudo bem, este não é o ponto da linguagem.
Recursos funcionais
Rust não é uma linguagem funcional. Rust não foi desenvolvida para ser uma linguagem funcional. Mas tendo sido significantemente influenciada por programação funcional, Rust oferece muitas ferramentas para que programadores experientes em programação funcional escrevam código com conformação funcional.
São todos recursos disponíveis na linguagem, que possibilitam escrever código expressivo, com estilo funcional; e com um detalhe importante: em geral, uma das reclamações que se faz de linguagens funcionais (e não quero aqui discutir isso) é a questão de se preterir performance de execução em função do rigor conceitual do código, mas este não é o caso de Rust, que tem massiva influência da filosofia C++ de custo zero de abstração.
Tudo ao mesmo tempo agora
Concorrência em Rust, na minha visão, não é tão natural como é em Erlang ou Go, mas isso é ok. Por outro lado, Rust oferece mais de uma ferramenta para se implementar concorrência:
Este é um exemplo simples de message passing que peguei emprestado de Klabnik & Nichols. Bem semelhante ao que se tem em Go, por exemplo, porém um tanto mais verboso.
Aliás, um parênteses aqui: às vezes acho Rust um pouco verbosa de mais. Fecha parênteses.
Este modelo de troca de mensagens é um que me agrada bastante e que estou bem familiarizado. Em muitas situações tendo a pensar primeiro neste modelo antes de considerar outro, porque ele favorece o desacoplamento.
Sinceramente, não gosto muito deste modelo. Mas programação não é sempre sobre o que se gosta, mas sobre o que se precisa fazer para ir da maneira mais segura e eficiente possível do ponto A ao ponto B. Então, quando é necessário usar o bom e velho lock, cá está ele à disposição. Implementação de estruturas de dados thread safe, semáforos de acesso a recursos, são exemplos de uso.
Já este exemplo abaixo é de concorrência com futures, usando a relativamente nova implementação de async/await, que também segue a filosofia de abstração com custo zero. Acho que este modelo dispensa qualquer introdução, por ter se popularizado tanto nos últimos anos, desde que foi implementado em F# e C# e mais recentemente em JavaScript.
Pensando bem, nos últimos anos, escrevendo um monte de C# e Node.js quase diariamente (e ocasionalmente algum Python com Async IO/ASGI nos finais de semana) este é o modelo que mais uso. É simples de ler código com async/await, fácil de entender, de explicar, não tem tempo ruim.
É bom ter mais de uma ferramenta à disposição e ser capaz de implementar mais de um modelo de concorrência, para então escolher o que melhor atende à tarefa em questão; e isso não é exclusivo, um ou outro. Em um sistema, pode haver uma combinação desses modelos que vimos. Aliás, esse é o mais provável.
A propósito, se você ainda se confunde um pouco com concorrência vs paralelismo, recomendo 2 minutos de leitura aqui.
Bem, apesar da minha reclamação sobre a verbosidade do message passing de Rust, no final do dia, a conta ainda fica positiva.
Odeio redefinição de variável
Uma coisa que odeio com todas as minhas forças é shadowing de variável.
Pqp, que p%#*@ é essa?!?!?!
Tá. Eu sei que shadowing não é o puro mal encarnado, tem lá sua razão de ser, blá, blá, blá…
I’m done.
Conclusão
Não existe bala de prata e isso você já deveria saber. Também não existe a linguagem perfeita e própria para todas as situações. O que existe são ferramentas em uma caixa; e o que se espera de você é que você saiba escolher a ferramenta certa, para o trabalho certo, na hora certa.
Eu tenho gostado bastante de Rust até então. Tenho tropeçado em alguns pontos aqui e ali, odiado uma coisa ou outra, mas no geral, estou muito satisfeito.
Uma confusão bem comum quando se começa a escrever programas concorrentes em Erlang é quanto ao uso da BIF (built-in function) self(). Mais especificamente, quanto ao seu retorno.
A BIFself() é analoga ao this do Java, por exemplo, que é capaz de responder quem é o objeto contenedor do método atualmente em execução. Semelhantemente, em Erlang, self() é capaz de dizer quem é o processo contenedor da função atualmente em execução avaliação. Assim, se você chamar self() no Erlang shell, você vai receber como retorno o Pid (identificador de processo) do próprio Erlang shell.
Faça um teste no seu Erlang shell:
1> self().
Você deve ter recebido algo semelhante a <0.31.0> com retorno. Isto porque o Erlang shell nada mais é do que um processo Erlang com um comportamento REPL.
Ok. Agora, o que acontece se você tiver um programa com um único módulo em que há duas funções que trocam mensagens entre dois processos? Qual seria o retorno de self() nestas duas funções?
Um pequeno exemplo
Vejamos um exemplo bem simples deste caso extraído do livro Erlang Programming:
De maneira bem objetiva, o que este código faz é o seguinte:
1- Quando um processo já existente— que no nosso caso será o próprio Erlang shell — faz uma chamada à função start(), um novo processo é gerado, tendo como ponto de partida a função loop(), o seu identificador é associado à variável Pid e, por fim, ele recebe o apelido add_two.
2- Todas as vezes que a função request(Int) é chamada, uma mensagem é enviada para o processo add_two, para que este some 2 ao número passado como parâmetro e envie o resultado de volta ao processo solicitante.
3- Sempre que o processo add_two recebe uma nova mensagem, esta é capturada na sentença receive ... end da função loop(), que verifica se é um “pedido de soma”, e então, envia o resultado da soma ao processo solicitante, identificado por Pid.
A confusão
Bem simples mesmo, certo? Então, por que acontece a tal confusão?
A confusão acontece, porque o retorno de self() não é o mesmo em todas as funções deste módulo. Isto porque a função loop(), apesar de estar contida no mesmo módulo que as funções start() e request(Int), não está rodando sendo avaliada no mesmo processo que elas estão. A função loop() está sendo avaliada no processo add_two, enquanto que start() e request() estão sendo avaliadas no primeiro processo — o Erlang shell. Assim, self() em loop() retorna um identificador de processo diferente do que retornaria as demais funções.
Quer tirar a prova?
Mais um simples exemplo, só que desta vez, esclarecedor!
Eu adicionei um bocado de “prints” no código que apresentei anteriormente e se você executá-lo agora, terá a prova do que foi discutido. (Tá tudo bem, você não precisa de uma prova a estas alturas do campeonato, mas vai ser divertido.)
Ao ler o título deste post, talvez você esteja se perguntando: por que eu deveria considerar Erlang para meu próximo grande projeto? Bem, meu objetivo com este post é te apresentar alguns importantes motivos para fazer isto.
Erlang nasceu no laboratório de ciência da computação da Ericsson na década de 1980, influenciada por linguagens como ML, Ada, Module, Prolog e Smalltalk, quando um time de três cientistas — entre eles, o grande Joe Armstrong — receberam a missão de descobrir qual seria a melhor linguagem de programação para escrever a próxima geração de sistemas de telecom. Após dois anos de investigação e prototipação, estes cientistas descobriram que nenhuma linguagem era completa o bastante para tal objetivo e, conclusivamente, decidiram criar uma nova linguagem. Nasceu então Erlang, the Ericsson Language.
De lá pra cá, Erlang tem sido evoluida e usada para escrever grandes sistemas críticos, porque é exatamente nesse cenário que Erlang faz mais sentido. Se seu projeto é construir um sistema crítico, altamente tolerante a falhas, com disponibilidade 24×7 e veloz como o papa-léguas, sim, Erlang é para você. Mas se não é bem esta sua necessidade, se você quer apenas construir um pequeno sistema, com baixa concorrência, poucos usuários, pouca necessidade de performance e possibilidade de passar horas down em manutenção, não, você não precisa de Erlang. Que tal Basic?
Diferente de algumas linguagens que nascem para encontrar um nicho, Erlang nasceu com um problema a ser resolvido, com requisitos a serem atendidos. Tolerância a falhas, concorrência realmente pesada, computação distribuída, atualização da aplicação sem derrubá-la, sistemas de tempo real, este é o nicho de Erlang; foi para isto que Erlang nasceu.
Quem usa Erlang atualmente?
Além da Ericsson, é lógico, há algumas outras grandes empresas e projetos usando Erlang, como por exemplo:
– Facebook, no backend de seu sistema de chat, lidando com 100 milhõs de usuários ativos;
– Delicious, que tem mais de 5 milhões de usuários e mais de 150 milhões de bookmarks;
– Amazon SimpleDB, o serviço de dados do seu poderoso EC2;
– Motorola, CouchDB, RabbitMQ, Ejabbed, etc.
Ok, mas Erlang é propriedade da Ericsson?
Não, felizmente, não. Em 1998 a Ericsson tornou Erlang open source sob a licença EPL.
Quer mais uma boa notícia? Você não precisa de um servidor de aplicações para rodar sua aplicação Erlang, nem mesmo uma pesada IDE para escrevê-las. Tudo o que você precisa é de uma distribuição de Erlang para sua plataforma, seja Mac OS X, Linux, Windows, Solaris, ou qualquer outro sistema Unix-like, que traz consigo máquina virtual, compilador e vasta bibliotéca de módulos muito úteis — além do banco de dados Mnesia; e um editor de textos de sua preferência — TextMate, por exemplo, tem um ótimo bundle para Erlang.
Algumas características de Erlang
1- Expressividade e beleza
Há quem diga que não, mas Erlang é uma linguagem muito bonita — ao menos pra mim. Dado as já citadas influências de Erlang, ela é uma linguagem bem expressiva e declarativa, que encoraja a escrita de código simples e objetivo, o que certamente torna seu código fácil de ler, de escrever e de organizar [em módulos reutilizáveis]. O snippet abaixo é um exemplo de implementação do famoso fatorial:
-module(sample1).
-export([fac/1]).
fac(0) -> 1;
fac(N) -> N * fac(N-1).
2- Forte uso de recursividade
Isto certamente é uma herança da veia funcional de Erlang que torna o código muito menos imperativo e mais declarativo. Mas além da beleza declarativa óbvia, é importante saber que Erlang foi projetada para lidar com iterações recursivas gigantescas sem qualquer degradação — e sem estourar o “heap” de memória.
3- Livre de efeito colateral
Uma das grandes capacidades dadas por Erlang é a construção de sistemas altamente concorrentes rodando em processadores com multiplos núcleos. Isto não combina nada com efeito colateral, por isso, em Erlang, uma vez que um dado valor tenha sido atribuído a uma variável, esta não poderá mais ser modificada — ou seja, estão mais para o que conhecemos por constantes do que para o que conhecemos por variaveis.
Se você já escreveu código concorrênte sabe o quanto tê-lo livre de efeitos colaterais te faz livre de dores de cabeça. Poucas coisas são tão deprimentes quanto debugar código concorrênte repleto de efeitos colaterais.
4- Pattern matching
Pattern matching em Erlang é usado para associar valores a variáveis, controlar fluxo de execução de programs, extrair valores de estruturas de dados compostas e lidar com argumentos de funções. Mais um ponto para código declarativo e expressividade. Vejamos o código abaixo:
-module(sample2).
-export([convert_length/1]).
convert_length(Length) ->
case Length of
{centimeter, X} ->
{inch, X / 2.54};
{inch, Y} ->
{centimeter, Y * 2.54}
end.
Fala por si, não?
5- Concorrência baseada em passagem de mensagens (a.k.a. Actors)
Acho que concorrência baseada em passagem de mensagem entre atores é uma das features mais populares de Erlang. Vejamos o porque com o famoso exemplo do Ping-Pong:
Neste pequeno snippet podemos observar algumas características de Erlang já citadas neste post, tal como pattern matching na captura das mensagens e recursividade no controle das iterações.
Agora, falando do aspecto concorrente em sim, algumas coisas são particularmente interessantes aqui:
a. Em Erlang, a concorrência acontece entre processos leves, diferente de linguagens como C++ e Java, que baseiam sua concorrência em threads nativas de sistema operacional [caríssimas];
b. Em Erlang, há um tipo de dado chamado PID, o qual é o identificador do processo paralelo (mais conhecido como Actor) e para o qual as mensagens podem ser enviadas.
Releia o código acima com estas informações em mente e veja como concorrência em Erlang é algo completamente descomplicado e natural. Depois, pense no mesmo código implementado em C#, Java ou C++.
Gostei de Erlang, há algum livro para eu começar a estudar?
Sim, há dois livros excepcionais. Um, do próprio criador da linguagem, Joe Armstrong:
Além disso, há o próprio material on line que é muito bom e barato. 🙂
Conclusão
Erlang possui muitas outras características e informações bem interessantes, mas que me falta espaço neste post para citar e apresentar, senão ele ficará absurdamente gigantesco para o meu gosto. Mas acredito que pelo que já apresentei até aqui, você já tenha motivos suficientes para pensar em Erlang com carinho e conciderá-la para seu próximo grande projeto.
Em breve devo escrever algo sobre OTP, já que neste post apresentei características mais inerentes à linguagem em si e nem tanto sobre a plataforma.