Poucas coisas no mundo amplificam mais incrivelmente nossa percepção de “demora” do que usar um microondas ou navegar na web. Alguns segundos de espera na frente do microondas ou até menos do que isso, quando se trata de um navegador web, e voilà, bem-vindo à eternidade. Mas sem harpas ou cantos gregorianos, somente dor e ranger de dentes. Not cool.

Se alguma coisa pode ser rápida, queremos que ela seja o mais rápido que puder. Se alguma coisa pode estar lá, pronta para ser usada quando bem quisermos usar, queremos que assim esteja. No caso do microondas, nhemmm, não há muito o que se possa fazer. Sorry. Mas felizmente, a vida não é tão cruel quando se trata de navegadores web ⎼ web engineers, sim, estes podem ser bem cruéis, cuidado! (LOL)
Web Workers
A Web Workers API torna possível que um script rode em background, em uma thread separada da thread principal da aplicação web. Isto é fantástico, porque assim a thread principal, que é a responsável pela UI, fica livre para interagir com o usuário enquanto a thread do web worker executa seu trabalho custoso e potencialmente demorado.
The main thread is where a browser processes user events and paints. By default, the browser uses a single thread to run all the JavaScript in your page, as well as to perform layout, reflows, and garbage collection. This means that long-running JavaScript functions can block the thread, leading to an unresponsive page and a bad user experience. ⎼ Main thread, MDN Web Docs Glossary.
Há três tipos de workers:
- Dedicated — são usados por apenas um único script;
- Shared — podem ser usados por múltiplos scripts, que podem estar rodando em diferentes janelas, iframes, etc, desde que estejam no mesmo domínio. Naturalmente, estes são um pouco mais complexos que os dedicados;
- Service — são fundamentalmente proxies, que se colocam entre a aplicação web, o navegador e a rede. O grande objetivo deles é criar aplicações que possam rodar offline (PWA), porque eles podem interceptar requisições de rede, lidar com falhas de rede, fazer cache de conteúdo, acessar push notifications, rodar tarefas em background, entre outras coisas.
Para brevidade deste post, vamos tratar apenas de workers dedicados. Em um futuro post, podemos explorar um dos outros dois tipos ⎼ ou quem sabe os dois.
Em termos práticos, um web worker é um objeto do tipo Worker, que recebe como argumento obrigatório de construção um script, que precisa obedecer à regra de mesma origem. Opcionalmente, você pode passar também um segundo argumento, um objeto options com três atributos do tipo string: type, credentials e name. (Nosso script downloader.js brinca com o atributo name. Você vai ver isso mais adiante, quando checar o projeto de exemplo. Oops! Spoiler. Urgh!)

Nesse tal script, que abrange o escopo global do worker, você tem acesso a uma série de objetos e funções built-in comuns do JavaScript, que provavelmente já está acostumado a usar, tais como:
- String, Array, Object, JSON, XMLHttpRequest e Cache;
- console, navigator e location;
- atob(), btoa(), setTimeout(), clearTimeout(), setInterval() e clearInterval().
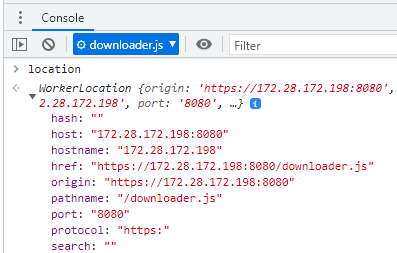
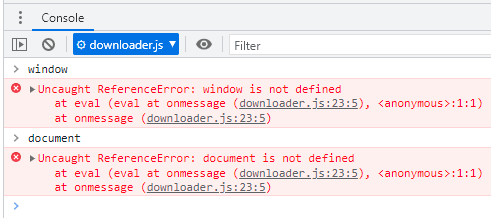
Mas por uma questão de thread safety, workers não tem acesso às famosas variáveis globais window e document, porque não possuem acesso à DOM API, uma vez que a thread principal é quem é a responsável pela UI.
Okay, muito bem. Mas espere. Hmmm. Como é que eu faço então quando preciso fazer alguma modificação na página atual, por exemplo, sei lá, esconder uma div ou mostrar uma imagem?
Ótima pergunta! E para respondê-la, vamos explorar um pouco a interação entre o script principal e um dado worker. Você vai ver que tudo vai ficar evidente daqui um pouquinho.
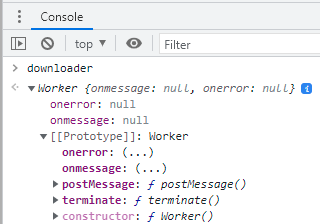
Um objeto Worker tem basicamente um método e dois eventos que nos interessam, no propósito desta discussão.
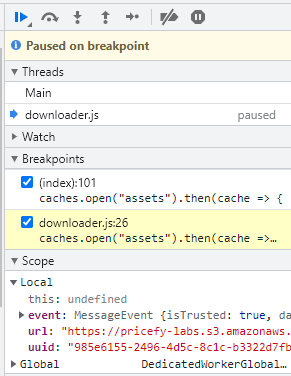
Agora, do lado do worker, vamos dar uma inspecionada na propriedade read-only self, que refere-se à instância do worker em si (repare na Figura 1 que “this” está undefined). O que nos importa deste lado é o seguinte:
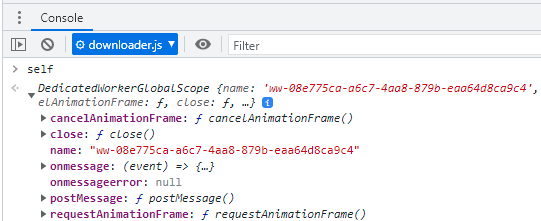
Basicamente, a mesma coisa, né? Típico de um modelo do comunicação baseado em troca de mensagens.
Pois muito bem, com essas informações em mãos, você já deve ter deduzido como é que essa interação entre script principal e worker funciona, né?
Quando o script principal quer falar com o worker, ele lhe envia uma mensagem usando o método postMessage(). O worker, por sua vez, quando recebe uma mensagem do script principal, a consome através do evento onmessage. E vice-versa.

O evento onmessage é onde o heavy lifting de fato acontece. Pode ser uma computação custosa, um pré-processamento, um cacheamento de recursos, ou qualquer outra operação potencialmente demorada que pode bloquear a UI e dar aquela sensação de travamento na página web.
Cache API
A Cache API oferece uma interface para o mecanismo de persistência do browser específico para pares de Request/Response, que ficam disponíveis tanto em escopo de janela quanto de worker.
Esse tipo de persistência é o que chamamos de “long lived memory” e sua implementação é totalmente dependente do navegador. Aliás, aproveitando o assunto “dependente do navegador”, a Dona Prudência recomenda que você teste sua feature pelo menos nos principais navegadores onde ela deve ser suportada, especialmente, quando se tratar de dispositivos móveis. Do contrário, há uma grande chance do Senhor Lamento lhe fazer uma visita, digamos, não muito amigável. Voltemos ao lance do storage agora.
Além da API de Cache, há ainda alguns outros serviços que usam a Storage API, mecanismo de persistência de dados do navegador, como por exemplo:
Isso significa que o espaço disponível para armazenamento é compartilhado entre todos os serviços de uma mesma origem, com diferentes quotas; não é dedicado a nenhum deles.
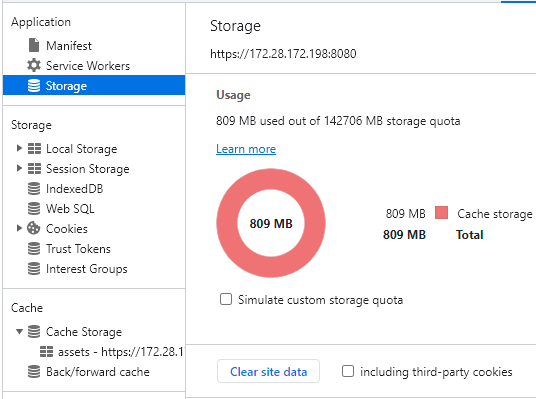
Agora, quanto ao tamanho desse espaço disponível, a documentação MDN Web Docs começa dizendo mais ou menos o seguinte: “olha só, pessoal, existem diversas maneiras do browser armazenar dados localmente e o processo pelo qual ele faz isso ⎼ calcular quanto espaço usar e quando liberar ⎼ é complicado e varia de browser para browser”. Super esclarecedor. Mas depois ela fica menos vaga e dá algumas informações mais concretas, que vou resumir aqui:
- A espaço máximo é dinâmico, baseado no espaço livre em disco;
- O limite global é essencialmente 50% do total livre do disco;
- Quando o espaço livre é atingido, acontece um processo de limpeza baseado na origem, a.k.a. origin eviction;
- A limpeza é por origem ⎼ não é seletivo quanto ao conteúdo “dentro” da origem ⎼, para evitar problemas de inconsistência.;
- Há também um group limit, que é de 20% do limite global, sendo que o mínimo é 10 MB e o máximo 2 GB (de um modo geral, o group limit é por domínio raíz e a origem por domínio absoluto);
- A limpeza acontece baseada em uma política de LRU.
Se você quiser se inteirar um pouco mais sobre essa questão de espaço disponível para armazenamento e tudo mais, o que eu lhe encorajo a fazer, para poder planejar sua estratégia de origem de conteúdo, recomendo este post: Estimating Available Storage Space. Ele já é um tanto velhinho, para “os padrões da interwebs”, mas vale a pena.
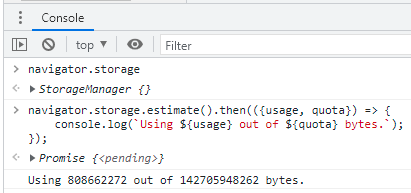
Que tal se aproveitarmos o ensejo do snippet da Figura 9 e partirmos para ver um pouco de código daqui em diante?
Uma aplicação web pode ter mais de um cache “nomeado” (o que pode ser interessante para agrupar conteúdo baseado em algum critério) e você precisa abri-lo antes de poder usá-lo. Caso ainda não exista um cache com o nome que você especificou ao tentar abri-lo, um novo será criado automaticamente.
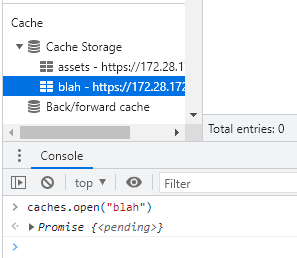
Como você deve ter percebido na Figura 10, para ter acesso à Cache API, o ponto de entrada é a propriedade read-only global caches, que é do tipo CacheStorage, e oferece alguns métodos fundamentais para seu uso típico.
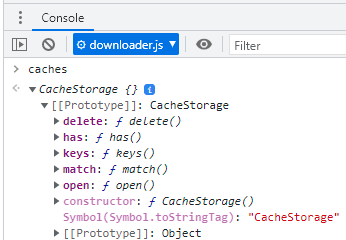
Os métodos da CacheStore são todos assíncronos e retornam uma Promise. No caso do método open(), ela resolve para o objeto Cache que se está querendo usar, pronto para uso.

Uma vez que você tenha um objeto Cache na mão, você pode então procurar por uma determinada URL. Para fazer isso, você usa o método match(), cujo primeiro argumento é uma URL ou um objeto Request, e resolve para um objeto Response. Esse método tem ainda um segundo argumento, com algumas opções interessantes para configuração dos critérios da busca.
Para uma visão concisa de como usar os diversos métodos da API, recomento: The Cache API: A quick guide.
Okay. Aqui tem um detalhe que acho que vale a pena comentar.
Há pouco, eu disse que uma aplicação pode ter mais de um cache “nomeado”, não foi? Pois é. E eu também disse que você precisa abri-lo antes de usá-lo, né? Então, nhmmm, isso é semi-verdade.
Em vez de usar caches.open(“assets”) para abri-lo e depois cache.match(“https://blah.com/tldr.png”) para recuperar o response cacheado, você pode simplesmente usar caches.match(“https://blah.com/tldr.png”). A diferença, pegando este atalho, é que a busca não é feita “em um cache específico”, mas em todos. Ou seja, há um custo extra na busca.
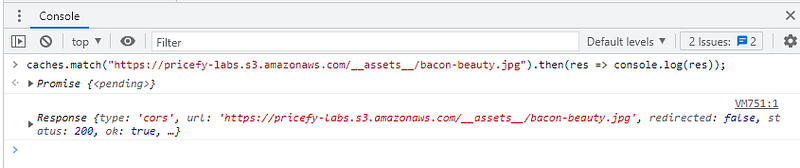
Tem mais uma coisa que acho importante comentar, que é o seguinte: diferente de alguns mecanismos de cache onde você define o tempo de expiração de um objeto e o mecanismo de cache faz o resto, aqui, você tem que deletar um objeto quando quiser revogá-lo. O mesmo vale para mantê-lo atualizado ⎼ isso é por sua conta.
Com esse recurso, você pode cachear retornos de API que não mudam com tanta frequência, imagens/vídeos de um slideshow agendados para rodar mesmo quando a rede estiver offline ⎼ pense em uma computação prévia disso, baseada no escalonamento de cada imagem ou vídeo.
Got code?
Yes, I do. Indeed.
Para tornar todos esses conceitos e sopa de letrinhas mais concretos e exemplificar como essas duas APIs podem ser usadas em conjunto, para criar uma solução completa, eu criei uma minúscula aplicação didática e subi no GitHub.
Ah, sim, claro! Que bom que você notou. A interface desse projeto é super “vintage”. Thanks for asking me.
Eu recomendo bastante que você, além de ler o código, também baixe o código na sua máquina e bote a aplicação para rodar, faça debug dela e observe o que acontece no console e nas abas network e application. Isso vai te ajudar a entender todo o mecanismo discutido até aqui. Afinal de contas, trata-se de um exemplo educativo, então, você tem que botar as mãos nele e experimentar por conta própria.
Tendo dúvidas, não hesite em me contactar.
Conclusão
A ideia desse post foi explorar um pouco dois recursos oferecidos pelos navegadores modernos, Web Workers e Cache API, para melhorar a experiência dos usuários humanos das suas aplicações, que não suportam esperar mais do que 3 segundos pelo carregamento de uma página web. E além disso, esses recursos também podem ser usados para criar aplicações que sejam tolerantes a indisponibilidades de rede e funcionem offline.
Nos falamos depois?
Vou ficar esperando…

