Desde que me lembro, sempre fui autodidata. Muito do que aprendi, aprendi por iniciativa própria, movido por uma curiosidade que arde dentro de mim, lendo livros técnicos, artigos científicos (eu sou nutricionista, btw), blog posts, assistindo a vídeos e, não menos importante, observando atentamente pessoas que sabem mais do que eu sobre determinado assunto.
Ao longo dos anos, tive uns tantos mentores, formais ou informais, que me ensinaram muitas coisas e me sinto bastante afortunado por isso.
Continuando o cíclo
Ensinar sempre foi algo que me interessou bastante. Seja de modo formal ou informal, sempre tive um impulso natural de compartilhar com os outros aquilo que eu sei. O que sempre fez com que a roda girasse na minha vida, em um ciclo contínuo de aprendizado e compartilhamento.
E é por isso que estou iniciando um trabalho independente e gratuito de mentoria em tecnologia e liderança.
Público alvo
Jovens líderes, engenheiros de software, arquitetos de sistemas, etc. Qualquer pessoa que esteja a fim de aprender, crescer e dar o próximo passo em sua carreira, seja lá qual for.
Se você:
– está iniciando sua carreira em engenharia de software, está meio perdido com tanta sopa de letrinha, não sabe no que foca ou que caminho trilhar;
– está responsável pela arquitetura de sistemas da firma e está enfrentando um problema técnico que não sabe como resolver;
– está responsável pela liderança técnica de uma jovem startup e as incertezas estão te deixando apavorado;
– está a cargo de escalar o time de engenharia de produtos digitais e não faz ideia de por onde começar;
– está enfrentando problemas com seu sistema em produção dia sim, dia também, com bugs, gargalos, problemas de escalabilidade;
Essa mentoria pode ser para você. Pode ser que conversando, te ouvindo e dividindo com você um pouco da minha experiência, você encontre a resposta, a solução, o caminho, ou seja lá o que esteja buscando.
Essa mentoria não é para amigos, chegados. Vocês podem me chamar a hora que for preciso. É isso que significa ser chegado, né?
Como vai funcionar?
Vamos ter encontros de 1 hora, 1 vez por semana, durante 4 semanas. Estes encontros acontecerão via Google Meet, no melhor horário que atenda às nossas agendas.
A ideia é iniciar a mentoria na segunda semana de janeiro de 2022.
Aos interessados
Se você se interessou, se é justamente o que você está precisando, basta preencher o formulário abaixo:
Andei batendo um papo muito bacana sobre a construção da Pricefy, engenharia de produtos digitais e a vida real em produção, com Christiano Milfont e Bruno Pereira, dois veteramos da tecnologia, que muita gente conhece desde os bons tempos de GUJ.
Para quem ainda não conhece o canal deles no YouTube, recomendo bastante dar um checada. Tem muita entrevista legal lá, com outros veteranos da área. Vale a pena conferir.
Outro dia desses, pensando sobre software, arquitetura de sistemas, gente e a natureza falível de tudo isso, enquanto tomava a primeira xícara de café do dia, recém coado, me lembrei de um trecho do livro ZeroMQ, do Pieter Hintjens:
Most people who speak of “reliability” don’t really know what they mean by it. We can only define reliability in terms of failure. That is, if we can handle a certain set of well defined and understood failures, we are reliable with respect to those failures. No more, no less.
ZeroMQ: Messaging for Many Applications, Pieter Hintjens, page 141.
O que eu, na modéstia do meu intelecto, reduzi à frase:
Um sistema é tão confiável quanto foi preparado para ser.
À qual, eu certamente poderia acrescentar “nem mais, nem menos” ao final. Mas não tenho tanta certeza de que “nem menos” é tão verdade assim. Principalmente, em se tratando de sistemas distribuídos; ainda que se tenha um projeto super minucioso. Vou deixar com está.
Foi daí que saiu a motivação de fazer este post. Porque este é o tipo de assunto que fica subentendido em muitas conversas que temos em nosso dia a dia, projetando, implementando e mantendo software em produção. Parece que todo mundo sabe do que está falando, presume que a pessoa ao lado sabe do que está falando e que estão todos na mesma página, falando sobre a mesma coisa, partindo das mesma premissas e reconhecendo as mesmas limitações. Ainda mais em tempos de cloud, microsserviços, serverless e essa coisa toda.
Entretanto, embora isto deva ser bem óbvio, acho que devo pecar pelo excesso aqui e dizer que não tenho a pretensão de escrever um post que esgote o assunto “confiabilidade” de software e sistemas. Aliás, muito longe disto. A literatura sobre confiabilidade de software e sistemas é vasta e impossível de se cobrir em um post. Eu nem mesmo já consumi toda a literatura de que tenho ciência da existência. Portanto, não assuma que isto é tudo.
A ideia é ser um pequeno aperitivo, que desperte o seu apetite e te leve a buscar por mais.
Confiabilidade de Software
Para começar, então, vamos trazer um pouco de definição à mesa.
The probability of failure-free software operation for a specified period of time in a specified environment [ANSI91].
Michael R. Lyu, Handbook of Software Reliability Engineering, page 5. [pdf]
Ele expande ainda um pouco mais esta ideia, logo em seguida, explicando que a confiabilidade de software é um dos atributos da qualidade de software ⎼ que por si só é uma propriedade multidimensional, que inclui outros fatores também ligados à satisfação do cliente, como funcionalidade, usabilidade, performance, suportabilidade, capacidade, instalabilidade, manutenibilidade e documentação.
The system should continue to work correctly (performing the correct function at the desired level of performance) even in the face of adversity (hardware or software faults, and even human error).
Martin Kleppmann, Designing Data-Intensive Applications, page 6.
Mais adiante, ele fala sobre o que tipicamente se espera de um software ⎼ que ele realize as funcionalidade esperadas pelo usuário; tolere erros cometidos do usuário; tenha desempenho bom o bastante para os casos de uso suportados, dentro do volume de dados esperado; e que previna acessos não autorizados e abusivos. Resumindo, o que ele diz é que o software deve continuar funcionando corretamente, mesmo quando as circunstâncias são adversas.
Enquanto Lyu apresenta 3 pontos importantíssimos para qualquer discussão sobre confiabilidade de software:
– Probabilidade de ausência de falhas; – Por período específico; – Em ambiente específico.
Kleppmann fala sobre continuidade de funcionamento correto dos sistemas mesmo quando as circunstâncias não são favoráveis a isto.
Aos sistemas que toleram tais situações adversas, ou falhas, damos o rótulo de “tolerantes à falhas”. Mas isto não significa que sejam tolerantes a todas e quaisquer falhas, porque isto seria absolutamente impossível. Há sempre uma restrição imposta por tempo para se projetar, implementar e testar uma solução, custo de viabilização, habilidade humana para realização e tamanho do retorno sobre todo investimento empregado. Em outras palavras, ter “tudo” nunca é uma opção.
Este é o ponto chave da menção que fiz de Hintjens no início deste post: um sistema tolerante à falhas é um sistema que está preparado para lidar com aquelas falhas que são bem conhecidas e compreendidas, em cujo qual certo esforço foi empregado para prepará-lo para tal. Nem mais, nem menos.
Agora, seja lá qual for a régua que adotemos, a verdade fria da coisa é que a confiabilidade de software é um fator crucial na satisfação do cliente, uma vez que falhas de software podem tornar um sistema completamente inoperante.
E não estou me referindo apenas a sistemas de ultra missão crítica, que podem causar a morte de pessoas, destruir vidas de verdade, como alguns exemplos que Pan oferece em seu artigo, mas de coisas mais mundanas mesmo, como Kleppmann cita em seu livro. Quero dizer, bugs em aplicações de negócio, que fazem seus usuários perder produtividade; indisponibilidades em e-commerces que impedem que vendas sejam concluídas; produtos de software que são vendidos, mas nunca provisionados no prazo prometido; e por aí vai. Você provavelmente deve ter ótimos exemplos muito melhores do que estes.
É claro que há momentos em que, conscientemente, decidimos sacrificar a confiabilidade de um sistema para reduzir seu custo inicial de desenvolvimento, porque estamos, por exemplo, desenvolvendo um protótipo ou MVP, que pode acabar indo para o lixo; ou pode ser o caso de termos que manter o custo total de um produto super baixo, porque sua margem de lucro não justifica nada além do mínimo possível. Ou simplesmente porque aquela funcionalidade incrível, que ninguém pode viver mais um dia sem, era para ontem.
Quem sabe se não é essa tal funcionalidade incrível, ainda que meio bugada, que vai fazer a diferença entre o sucesso ou a ruína de um produto?
Temos que estar realmente muito conscientes das decisões que tomamos, que afetam direta ou indiretamente a confiabilidade dos softwares que de algum modo comercializamos, já que este é um fator tão fundamental à satisfação dos nossos clientes.
Precisamos estar seguros em relação a pelo menos estes seis pontos:
– De onde estamos cortando; – Porque estamos cortando; – Por quanto tempo estamos cortando; – Se é um corte remediável no futuro; – O quanto o usuário vai sofrer com os cortes; – E o quanto estamos ganhando com tudo isto.
Não se pode ter tudo. Mas pode-se ter consciência sobre o que não se tem e suas consequências imediatas e futuras.
A triste realidade de software
Diferente de bens materiais, como um carro, uma torneira, uma fotocópia, ou um equipamento eletroeletrônico qualquer, um software não envelhece, não enferruja, não se desgasta e perde funcionalidade com o tempo. Dado que todas as condições externas ao software, às quais ele depende, sejam exatamente as mesmas, não importa quantos anos de existência tenha uma determinada versão do software, ela vai funcionar tão bem (ou tão mal) quanto da primeira vez. Nhmmmm, sort of…
A verdade deprimente é que softwares que rodam continuamente por longos períodos de tempo, fazendo qualquer coisa minimamente importante para alguém, ainda que sob as mesmas [supostas] condições de ambiente nos quais estão inseridos (hardware, sistema operacional, rede, etc), com o tempo, vão se degradando, porque estas [supostas] condições externas vão se alterando e assim também suas próprias condições internas, ainda que seu código fonte ou mesmo binário permaneçam absolutamente inalterados.
Daí a importância de se ter um time de operação capacitado, munido com ferramentas de gestão de configuração, monitoria, telemetria e todo o mais possível.
Isto é, tanto quanto o conteúdo do código fonte mantém-se intacto quando este é submetido à execução, também a sua qualidade permanece a mesma. O que significa que, quanto menor a qualidade do código fonte, maior a probabilidade de seu estado em execução se degradar em um menor espaço de tempo e resultar em incidentes em produção ⎼ o que, em última análise, se traduz em cliente insatisfeito e imagem da organização arranhada.
E isto não é tudo. Em um ensaio sobre confiabilidade de software da Carnegie Mellon University, Jiantao Pan escreve que a complexidade de um software está inversamente relacionada à sua confiabilidade; quanto maior sua complexidade, menor sua confiabilidade. Já a relação entre complexidade e funcionalidade tende a ser causal; quando maior o número de funcionalidades, maior sua complexidade.
Lembra-se da máxima de que menos é mais? E daquela estimativa de que 80% dos usuários usam apenas 20% das funcionalidades? Pois é, chunchar funcionalidades para competir pode ser não apenas uma estratégia ineficaz, como também um ofensor da confiabilidade do sistema como um todo.
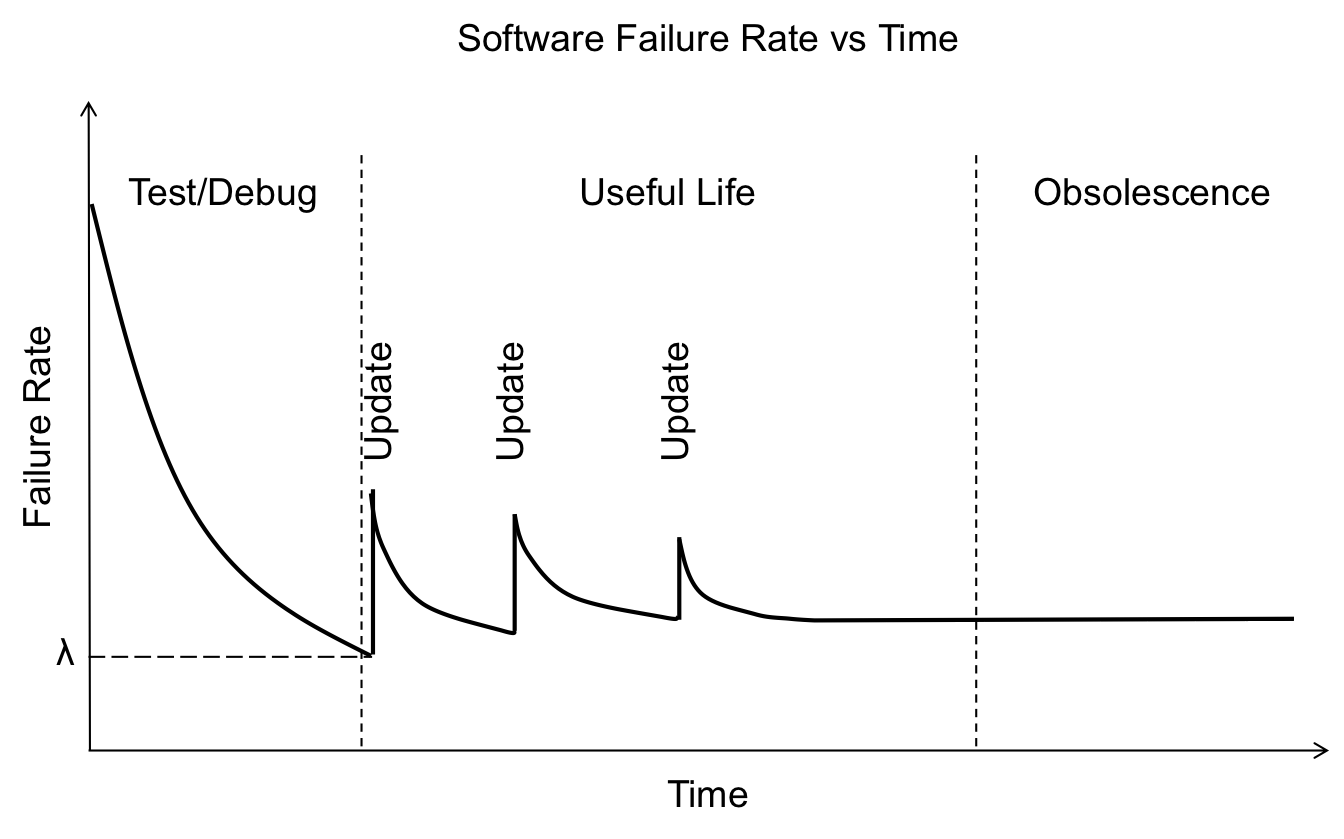
Diferentemente do que acontece com bens materiais, como disse há pouco, que vão se deteriorando e sofrendo aumento na ocorrência de falhas ao longo de sua vida útil, softwares tendem a ter maior ocorrência de falhas em sua fase inicial e muito menos em sua fase de obsolescência.
Note que o que causa aumento da chance de falhas, com efeito levemente residual, é justamente a implantação de novas versões; em especial, se elas trouxerem consigo novas funcionalidades. Não que esta informação deva nos deixar acanhados de publicar novas versões, absolutamente. O que devemos, sim, é não ignorá-la. Precisamos ser mais responsáveis com o que publicamos em produção, investindo tempo em testes melhores, detectando falhas mais rapidamente e oferecendo maneiras de revertê-las o quanto antes.
A bem da verdade, até mesmo novas capacidades que visam aumentar a confiabilidade podem causar novas falhas. Senão por falhas no código em si, resultado do novo ciclo (seja ele de um dia ou um mês) de projeto, implementação e teste, pelo simples fato do ambiente sistêmico de produção não ser exatamente o mesmo de desenvolvimento. Eles podem até ser muito, muito, semelhantes um ao outro, mas frequentemente não são o mesmo. Muitas vezes, o ambiente de produção de ontem nem mesmo é o de hoje. Quem dirá, o de uma semana atrás.
Dispositivos móveis são um ótimo exemplo disto. Você nunca tem certeza sobre o estado que vai estar o dispositivo móvel quando seu aplicativo for instalado. Isso sem falar em sistemas embarcados.
Outro exemplo é o caso de softwares que compõem um sistema distribuído. Uma nova versão de um software coincide com uma nova versão de outro software, que torna-os de algum modo conflitantes e incompatíveis. Pau!
O fator “pessoas”
Eu acho um baita clichê quando dizem que tudo é sobre pessoas; ou alguma variação disso, com o mesmo significado. Mas no final das contas, a verdade é que é isso mesmo.
As pessoas projetam expectativas. As pessoas fazem promessas. As pessoas não conseguem cumprir suas promessas. As pessoas sequer conseguem fazer as coisas direito 100% do tempo. Porque no final das contas, como dizem, isto é ser humano, não é? É, pois é.
Em seu ensaio sobre confiabilidade de software, Pan faz referência ao paper de Peter A. Keiller e Douglas R. Miller, intitulado On the use and the performance of software reliability growth models, e escreve que falhas de software podem ser decorrente de erros, ambiguidades, omissões ou má interpretações da especificação; podem ser também descuido ou incompetência na escrita do código, teste inadequado, uso incorreto ou inesperado do software; ou outros problemas imprevistos. Em resumo, pessoas sendo pessoas.
E a despeito dele ter escrito isto em 1999, mesmo com o posterior advento do desenvolvimento de software ágil, ainda não erradicamos os fatores causadores de “falhas de software”. Diminuímos, sim, mas não eliminamos. Talvez porque, como ele diz, eles estejam intimamente relacionados a fatores humanos confusos e ao processo de projeto da coisa que estamos construindo, os quais ainda não temos um entendimento sólido. Pessoas, right?
O guard-rail
Se você chegou até aqui, talvez esteja se perguntando: se não dá para erradicar completamente, tem que dar ao menos para controlar a magnitude, mitigar de alguma maneira, certo?
Sim, certo. Nem tudo está perdido. Já vimos algumas dicas ao longo do caminho.
Em muitos casos, com processos de desenvolvimento sólidos, com ciclos curtos de projeto, implementação e teste; com práticas de engenharia cínicas, que sempre esperam pelo pior; com engenheiros de qualidade que caçam pêlo em ovo; com processos de governança super defensivos; e com real atenção à operação desde a concepção do que se está construindo.
Em outros casos, sentando e chorando. Okay, este último não é exatamente uma opção.
Ciclos menores
Promover ciclos menores de “concepção à produção” é uma ótima prática para se adotar, se não por tudo que vimos até aqui (especialmente a questão dos pacotes novo em produção), porque as pessoas tem limiares de atenção diferentes. Mas não é só isso.
Muitas vezes, a velocidade do negócio e suas incertezas nos obrigam a mudar de foco antes de conseguirmos concluir uma determinada atividade e isto é super frustrante, mesmo que você tente entrar naquele estado mental de “estamos fazendo isso pelo negócio”, “este é o melhor a se fazer”, “estamos aqui pelo cliente”. Yeah, I get it. Mas ainda assim é frustrante. Como seres humanos nos sentimos frustrados de começar algo e não concluir, seja por desinteresse momentâneo ou por força maior. Então, o quanto antes concluirmos, melhor.
Então, quanto menores? Tão pequenos quanto o suficiente para se fazer um bom projeto, implementação limpa e testes de verdade. Em alguns casos, tudo isto pode acontecer em horas; em outros, pode levar semanas. O importante é que se saiba bem o que se está programando e como testar que tudo está saindo conforme o esperado.
Quebrar grandes requisitos em diversos requisitos menores, que vão se complementando, é um caminho para se ter ciclos menores. Com certeza, é um bom começo.
Transparência
Aqui me refiro à transparência do software rodando em produção, como ensina Michael T. Nygard, em Release It, na página 226.
Nygard diz que um sistema sem transparência não pode sobreviver por muito tempo em produção. Ele diz que se os administradores do sistema não sabem o que os componentes do sistema estão fazendo, eles não podem otimizar este sistema. Bem, seria muito perigoso mexer no que não se tem controle. E não se pode ter controle do que não se faz a menor ideia.
Se os desenvolvedores não sabem “o que funciona” e “o que não funciona” em produção, eles não podem aumentar a confiabilidade e resiliência do sistema ao longo do tempo.
E quanto aos sponsors de negócio? Se eles não sabem se eles estão ganhando dinheiro com o sistema, eles não podem investir em trabalho futuro de melhoria, etc.
Ele conclui, então, em tom meio apocalíptico, penso eu, dizendo que um sistema sem transparência vai seguir em decadência, funcionando um pouco pior a cada nova versão.
Segundo Nygard ⎼ e tendo a concordar fortemente, depois de anos e anos escrevendo software e mantendo-os em produção ⎼, sistemas que amadurecem bem são sistemas que oferecem algum grau de transparência.
elegÂnCIA
Vimos que não é possível um sistema ser tolerante a toda e qualquer falha possível e imaginável. Devemos priorizar de modo consciente quais falhas toleraremos, para mantermos o funcionamento correto do sistema para o usuário final, se possível, sem que sequer se perceba que houve algo de errado.
Reliability means making systems work correctly, even when faults occur. Faults can be in hardware (typically random and uncorrelated), software (bugs are typically systematic and hard to deal with), and humans (who inevitably make mistakes from time to time). Fault-tolerance techniques can hide certain types of faults from the end user.
Martin Kleppmann, Designing Data-Intensive Applications, page 22.
Mas haverá momentos, como já vimos, em que não será possível manter funcionalidades completas do sistema diante de certas falhas, seja por decisão ou impossibilidade técnica. Nestes momentos, precisaremos recorrer a outros artifícios, se não quisermos torturar nosso cliente com tanta insatisfação. Graceful Degradation é um desses artifícios, mas ele não vem “de graça”.
One approach to achieving software robustness is graceful degradation. Graceful degradation is the property that individual component failures reduce system functionality rather than cause a complete system failure. However, current practice for achieving graceful degradation requires a specific engineering effort enumerating every failure mode to be handled at design time, and devising a specific procedure for each failure [Herlihy91].
Charles P. Shelton and Philip Koopman, Developing a Software Architecture for Graceful Degradation in an Elevator Control System. [pdf]
A “degradação elegante” de um sistema, chamemos assim, é um atributo que às vezes é confundido com a tolerância à falhas, mas há diferença entre eles.
Enquanto a tolerância à falhas diz respeito a lidar com componentes falhos do sistema, fazendo algum tipo de substituição, alguma manobra, que não cause degradação da experiência do usuário e continue a prover as funcionalidades esperadas, a degradação elegante, é a última instância do gerenciamento eficaz de falhas, quando a falha em componentes do sistema chega a um ponto em que não é mais possível manter as funcionalidades completas, com desempenho adequado, mas apenas parte delas, visando sobretudo evitar falhas generalizadas.
The purpose of graceful degradation is to prevent catastrophic failure. Ideally, even the simultaneous loss of multiple components does not cause downtime in a system with this feature. In graceful degradation, the operating efficiency or speed declines gradually as an increasing number of components fail.
Então, quando tudo for inevitavelmente para o despenhadeiro, porque o seu sistema chegou ao limite do quão confiável foi preparado para ser, tente ao menos ser elegante.
Há alguns dias tive a oportunidade de falar uma ou duas palavras no OxenteRails 2010 sobre gerenciamento de times de desenvolvimento de software, em especial, os autogerenciáveis. Foi uma experiência bem bacana, havia mais gente interessada no assunto do que eu imaginava que haveria.
Achei o evento muito arretado, como de fato era sua proposta. (háh!)
Bem, mas sendo um pouco mais especifico, deixo um destaque especial para a organização do evento, que foi impecável; muito acima da média mesmo; o pessoal da comunidade lá de Natal está de parabéns. Annaysa Melo, Paulo Fagiani, Maximiliano Guerra e todos os demais, muito obrigado pela receptividade!
A maioria das palestras que assisti foram muito boas, em especial a do Tapajós que, como já era de se esperar, mandou super bem falando de CouchDB. Queria muito ter visto também a do CV, mas infelizmente não pude, porque palestramos no mesmo horário. Fica pra próxima.
A palestra do Geoffrey— com aquela voz de peepcoder — foi no mínimo divertida; mas a do José Valim acho que ficou devendo um pouco — talvez porque, IMHO, soou um tanto quanto marketing da Plataforma. Já a do Akita me surpreendeu. Nem tanto pelo conteúdo — apesar de indiscutivelmente relevante —, mas mais pelo formato e desenvoltura. Bem legal mesmo.
Não gostei da palestra do Carlos Brando, achei muito auto-ajuda; mas deixo um ponto positivo pro trecho de Assembly e C que ele codou ao vivo. Aliás, falando em codar ao vivo, a palestra do Nando foi muito boa, com seus slides super descolados e coloridos, mas ele não codou ao vivo. Tadinho do Murphy e sua lei, não paparam essa.
Dessa fez o Kung também não codou ao vivo, como de costume, mas sua palestra foi legal, bem contextualizada, dinâmica e totalmente #devops. Aliás, ela fez tanto sucesso que, depois de terminá-la, ele ficou um tempão trocando idéia e codando com a galera no open space.
Não pude ver a palestra do Rafael Rosa, meu colega de Locaweb, porque estava na do Hugo Baraúna sobre Project Rescue. Não gostei muito, pra ser sincero, então acabei ficando meio frustrado.
O Henrique Bastos deu um show de humildade, numa palestra que, sinceramente, eu não esperava muito do tema. Foi excelente. Já a palestra do Daniel Lopes, não gostei não. Gostei do Steak, que eu ainda não conhecia, mas achei a palestra dele meio bala de prata no que diz respeito a testes de aceitação.
A palestra do Vinícius Teles foi legal, mas como eu já tinha visto ele palestrar nos dois últimos anos, na Rails Summit, não foi muito novidade pra mim. Mesmo assim, uma boa palestra.
Nessa linha de empreendedorismo — também seguida pelo Rafael Lima —, o Alê Gomes, cara muito gente fina, fez uma apresentação meio reworkeana, mas mega divertida. Casquei o bico com ele.
Vi também a palestra da Thaís, falando sobre seu dia-a-dia no trabalho, comprometimento e respeito aos colegas. Foi legal.
E por fim, rolou um Q&A com todos os palestrantes, quando foi revelado que somente eu, Akita, CV e Juan Bernabó não terminamos a faculdade. Aliás, falando nesse Q&A, rapaz, como tem gente que gosta de falar, hein? Teve palestrante que pegou o microfone e não quis mais largar. Fiquei impressionado.
Balanço final
Valeu bastante a pena ter participado dessa conferência, em especial pelas discussões e bate-papos informais.
Ano que vem, quem sabe, nos vemos por lá outra vez!
Nos dias 6 e 7 de agosto acontecerá em Natal a segunda edição do evento de Rails mais arretado do planeta, o OxenteRails 2010, com palestras técnicas [e não técnicas] de diversas personalidades da comunidade de desenvolvimento de software brasileira e internacional.
Se você estiver por lá e quiser ver uma palestra nada técnica, logo depois do coffe-break, às 16:00, na sala B, vou falar sobre “gerenciamento de times auto-gerenciáveis”.
Uma introdução ao assunto da minha palestra são os posts:
Quem me acompanha no Twitter sabe que mês passado estive na 11ª Conferência Internacional de Desenvolvimento Ágil de Software, a.k.a.XP 2010— que este ano aconteceu na longínqua Trondheim, na Noruega —, junto com meu companheiro de Locaweb, Alexandre Freite, figurinha conhecida da comundade ágil de São Paulo.
O evento foi muito bacana, teva ótima organização, boas palestras, tudo muito legal mesmo. Parabéns ao Danilo Sato, ao Hugo Corbucci, à Mariana Bravo e aos demais organizadores.
Palestras
As palestras foram boas, mas em geral não trouxeram nada de muito novo. Mesmo o keynote do Martin Fowler, que tocou no assunto de deploy contínuo, não trouxe nada de muito novo. O Guilherme Silveira, da Caelum, havia blogado em março e feito uma apresentação em maio sobre esse tema no evento Maré de Agilidade, em BH.
Gostei bastante do tutorial do Paulo Caroli, da ThoughtWorks, sobre Agile Card Wall; da palestra do Franscico Trindade, também da ThoughtWorks, sobre Coaching de Guerrilha; achei interessante a palestra do Manoel Pimentel, da Visão Ágil, sobre Coaching para Liderança de Equipes Ágeis, mas fiquei um pouco entediado com suas dinâmicas; e infelizmente, não pude ver o workshop do Rodrigo Yoshima, da Aspercom, e do Phillip Calçado, da ThoughtWorks, sobre Modelagem Ágil, porque eles baleiraram a sala!
O keynote do Klaus Wuestefeld foi bem divertido — feito no Notepad! — e, como sempre, subversivo!
Networking
Mas apesar das boas palestras, a parte mais interessante mesmo, na minha opinião, foram os papos informais nos intervalos das palestras, almoço e final do dia. Papos informais são uma excelente maneira de trocar experiências, ter insights e conhecer pessoas talentosas. Rolou de tudo: liderança de times ágeis, auto-gerenciamento, débito técnico, desafio de lidar com sistemas legados, gerenciamento de iterações, Kanban, métricas, e por aí vai. Muito proveitoso.
Dicas de reviews
Sugiro fortemente que você leia os reviews feitos pelo Rafael Rosa, um dos meus colegas de Locaweb que também estiveram por lá.
Outra dica de leitura é o review que o Alan, também da Locaweb, fez do curso de CSPO que ele fez na prévia da conferência.
Já faz um tempão que li um post do Martin Fowler que falava sobre o aumento de produtividade resultante do uso de dois monitores grandes, em lugar de um único e pequeno monitor. Na época, achei bem interessante a idéia, mas como estava totalmente fora do meu alcance ter uma área de trabalho dessas — em meu emprego da época —, preferi simplesmente deixar pra lá. Mas ultimamente, mesmo adorando a tela do meu MacBook 13.3” — que passei a levar pro meu emprego atual —, de tanto ver pessoas ao meu lado usando dois monitores grandes, de maneira tão inteligente e produtiva, passeir a querer testar isso também.
A deixa final
Como já disse algumas vezes aqui no blog, em meus times, além de alguns legados, lidamos basicamente com Ruby on Rails, C#/ASP.NET MVC e Git como DVCS. Então, além de um bom editor de textos e um terminal, precisamos também de um Visual Studio— com ReSharper, porque sem isso, ele não é nada — que, infelizmente, para usuários de Mac e Linux, só roda em Windows. Tentei resolver isso usando Mono, mas acabei desistindo — por enquanto, porque vai ter revanche!
Bem, resolvi então usar o Parallels Desktop 5 para rodar o Visual Studio 2010 no conforto do meu Mac e, de tabela, adicionar mais um monitor à minha área de trabalho.
Meu space de programação
Pra mim ficou fantástico! Porque no meu space de programação deixei o Visual Studio maximizado na tela grande (à esquerda), rodando no Windows, que por sua vez está rodando no Parallels Desktop, em tela cheia e com look & feel de Mac OS X; e na tela do Mac (à direita) — que eu adoro! —, deixei o terminal, onde posso interagir com o Git e tudo mais. Yay!
Visual Studio 2010 no Windows (à esquerda); Terminal no Mac OS X (à direita)
E tem mais: quando não precisar usar o Visual Studio por um longo tempo, tenho duas alternativas:
– desligar o Windows;
– ou simplesmente pausá-lo no Parallels Desktop.
E se for o caso, arrastar o TextMate pra tela grande.
Ficou muito bom isso, o Parallels Desktop é demais!
Meus outros spaces
Uma área de trabalho dessas não serve só pra programação. Hoje mesmo precisava editar um wiki enquanto olhava dados em uma planilha. Sem problemas! Planilha na tela grande e wiki sendo editado na tela do Mac. Fantástico!
Só faz um dia que estou com essa área de trabalho expandida e sinto que não posso mais trabalhar sem ela. hehehe
Há dois meses postei aqui minhas duas propostas para o evento Agile Brazil 2010. Uma delas foi aceita — “Como vi Scrum ser completamente rechaçado em uma grande empresa”.
Qual a idéia dessa palestra?
Bem, nem só de acertos vive um agilista — os contadores de “case”, sim; os agilistas, não. Aliás, pelo contrário, frequentemente aprendemos mais com nossos erros do que acerto. Porque muitas vezes nossos acertos são frutos de pura sorte e sequer conseguimos reproduzi-los novamente.
Dito isto, minha palestra não é sobre “dar carrinho” nos amigos que estiveram comigo nessa experiência, nem apontar culpados ou citar nomes. Não! Minha palestra é sobre apontar erros que cometemos — óbvio, querendo acertar; é sobre lições aprendidas — boas e ruins.
Essa apresentação é a visão e opinião de todos?
Não sei exatamente. Vou falar única e exclusivamente da minha visão e opinião sobre os fatos.
Como o Vinícius Teles sabiamente disse há alguns anos, “Programação em par é uma das práticas mais conhecidas e mais polêmicas utilizadas pelos que adotam o Extreme Programming“. Emprestando mais algumas de suas palavras, o motivo é que:
“Ela sugere que todo e qualquer código produzido no projeto seja sempre implementado por duas pessoas juntas, diante do mesmo computador, revezando-se no teclado.
À primeira vista, a programação em par parece ser uma prática fadada ao fracasso e ao desperdício. Afinal, embora possa haver benefícios, temos a impressão de que ela irá consumir mais recursos ou irá elevar o tempo do desenvolvimento. Entretanto, não é exatamente isso o que ocorre.”
Não, não é isso mesmo!
Nossa experiência
Há quatro meses decidimos, de uma vez por todas, levarmos realmente à sério esse negócio de programação em par aqui nos times de desenvolvimento dos sistemas centrais da Locaweb. De imeditato, optamos pelo caminho mais eficaz: reduzimos pela metade o número de máquinas dos times. Sim, quase que do dia para a noite, passamos a ter apenas e tão-somente uma máquina para cada dois desenvolvedores.
Estações de pareamento: como é que é isso?
Desde que fizemos a redução de 50% de nossas estações de trabalho, passamos a ter as chamadas estações de pareamento, máquinas destinadas exclusivamente para trabalho.
Estações de pareamento precisam ter:
– usuário genérico para login;
– script para settar no git o dupla atual;
– configuração padrão de desktop, diretórios e ferramentas;
– apenas o instante messager de trabalho;
– apenas o cliente de e-mail de trabalho;
– acesso total à Internet;
– idealmente: 2 teclados, 2 mouses e 2 monitores (grandes!).
Mas não devem ter:
– arquivos pessoais;
– programas de distração.
Bem, não está diretamente associado ao modelo de estações de pareamento, mas é bem importante também que as duplas tenham ao seu lado o monitor da integração contínua de seu time, para ter sempre à vista o feedback dos builds. No nosso caso, temos monitores suspensos como o que pode ser visto na foto ao lado — de preferência, sempre verdinhos!
Estação de relax: tem isso, é?
Junto com a idéia das estações de pareamento também adotamos a idéia de estação de relax. Atualmente temos apenas uma, dado o tamanho de nossa equipe.
A estação de relax é uma máquina com acesso total à Internet para a galera relaxar um pouco durante a jornada de trabalho, acessar e-mail pessoal, redes sociais, internet banking, enfim, o que quiserem e bem entenderem. Acesso total à qualquer hora do dia!
O que temos colhido com isso?
Até agora só ganhamos! Ganhamos produtividade, qualidade, propriedade coletiva de código, padronização, e por aí vai.