Lá pelo idos de 2000, quando tive meu primeiro contato com C#, eu era um jovem “programador Java”, com alguns poucos anos de experiência em Delphi, sonhando com um futuro onde Java seria ubíquo e nada mais seria importante. Mas C#, em especial, capturou minha atenção por estar sendo desenvolvida por Anders Hejlsberg, o mesmo cara que já havia criado o Turbo Pascal e o Delphi, que eu era muito fã ⎼ e ainda tenho certa nostalgia, vez ou outra, confesso.
Na época, achei que não passava de um Microsoft copycat do Java e segui a vida.
O reencontro
Fast forward uns 9 anos e lá estava eu, na Locaweb, assumindo a gestão de um time que era quase 100% baseado em C#, depois de quase uma década sem dar qualquer 5 minutos de atenção à linguagem ou à plataforma .NET em si.
A primeira surpresa que tive foi que .NET ainda não tinha ferramentas robustas de build, gerenciamento de artefatos, dependências, etc e tal, como tínhamos Maven (a.k.a. The Official Internet Download Tool), Ant, Ivy, Hudson (a.k.a. Jenkins) e Artifactory na comunidade Java. Isso, obviamente, dava espaço para que diversos problemas emergissem do desenvolvimento de aplicações distribuídas, como era o nosso caso. Problemas estes, que a comunidade Java já tinha passado há anos e coçado a sua própria coceira.
Uma das minhas primeiras iniciativas no time, então, foi dar apoio aos ótimos engenheiros de software que tínhamos, para que eles resolvessem esse problema. (Alguns de nós éramos programadores Java experientes, by the way.) Além de liberar certo tempo nas sprints, para que pudessem se dedicar a isso, também contribui com algum código. E foi dessa iniciativa que nasceu o projeto IronHammer ⎼ curiosamente, escrito em Ruby, não C#. Assunto para um outro momento.
A segunda surpresa que tive foi o quanto C# tinha evoluído e se tornado, na minha opinião, um Java melhor (a linguagem em si, não a plataforma), o que contrastava com a questão do ferramental precário, que me chamou atenção inicialmente. O próprio Visual Studio era super precário; sem ReSharper, ele não era muito mais do que um Notepad glorificado.
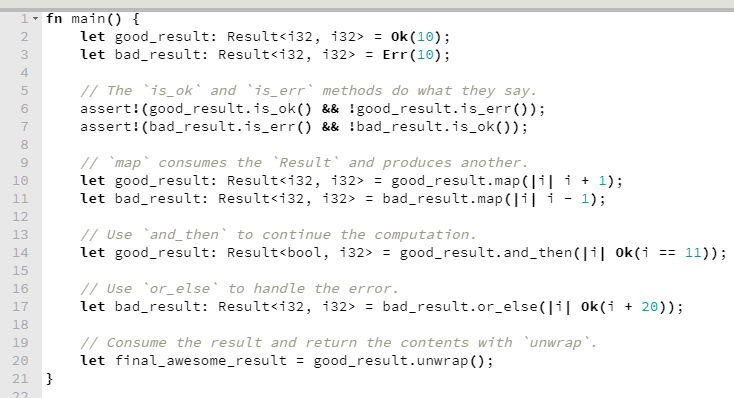
Propriedades auto-implementadas, inferência de tipos (var), expressões lambda, LINQ (que é uma das coisas mais fantásticas do .NET), extension methods, tipos anônimos, etc, eram features que C# já possuía há pelo menos 2 anos quando tomei conhecimento. E passados alguns poucos meses, quando eu mal tinha emergido da minha imersão em C# 3, veio o C# 4, trazendo dynamic e parâmetros opcionais, entre outras coisas.

Como eu queria ter tido essas features nos meus últimos anos de Java, quando eu estava completamente vidrado por linguagens dinâmicas e programação funcional (Ruby e Erlang).
É bom que se reconheça uma coisa: se a linguagem Java foi a grande influência da criação e dos primeiros anos de vida do C#, muito de sua evolução posterior se deu por influência de F#, que apesar de mais jovem, tem em seu DNA a família ML de linguagens, descendendo diretamente de OCaml. Uma bagagem e tanto.
Ela segue em frente
Fast forward mais uma década e aqui estou eu, construindo a Pricefy há 5 anos, mantendo uma base de código majoritariamente C#, e mais uma vez impressionado com o quanto a linguagem evoluiu desde a última vez que parei para refletir a respeito. Do async/await do C# 5 aos avanços de pattern matching e top-level statements do C# 9, o que fica muito claro para mim é que a evolução da linguagem continua a todo vapor, mantendo-a jovial e moderna. Até quando? Não sei. É verdade que tem gente que já está reclamando que a linguagem está ficando complicada demais e inchada. Aliás, essa não é uma reclamação nova, sejamos francos; já tem certo tempo que essa questão tem sido levantada. Há até quem diga que está se transformando em C++.
Mas a verdade é que não temos que usar todas as features e capacidades de uma linguagem, sejam elas novas ou de berço, simplesmente porque elas estão lá, disponíveis. Há tempo e utilidade para cada funcionalidade ⎼ “à moda antiga” não é automaticamente errado.
No caso específico de C#, que estamos discutindo, a esmagadora maioria das novidades que chegaram ao longo dos anos foram para simplificar o código que se escreve e não para deixá-lo mais complicado. O mesmo vale para C++, diga-se de passagem.
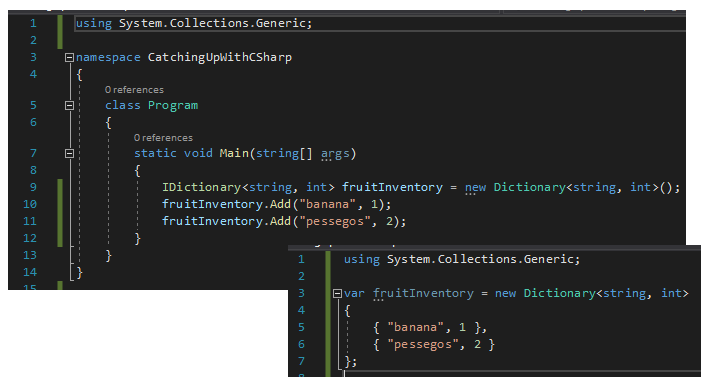
Complicado é tentar guardar na cabeça cada uma das zilhares de funcionalidades da linguagem ou as trocentas maneiras de se fazer a mesma coisa.
Honestamente? Eu não sei todas as features da linguagem. Não sei. Eu provavelmente nem devo saber, de bate pronto, assim, pá pum, todas as maneiras de se declarar e atribuir uma variável qualquer para salvar a minha própria vida. Isso porque, é quase impossível bem difícil você “modernizar” sua base de código de negócio pari passu com a linguagem de programação (ou mesmo framework) que você usa. Primeiro, porque com o passar dos anos a base de código vai ficando cada vez maior e essa “modernização” nem sempre vai trazer um retorno substancial para o problema de negócio, que o código se propõe a resolver, em função do esforço necessário para a tal “modernização”. Segundo que, vintage é cool. Não, é brincadeira. (Mas é verdade.)
O meu ponto é: manter uniformidade na base de código é mais importante e traz mais valor real ao negócio do que manter a base de código atualizada com as últimas novidades da linguagem. Um código uniforme, que qualquer dev do time navega bem e se sente em casa para implementar novas funcionalidades, modificar funcionalidades existentes e corrigir bugs, na minha cartilha, é mil vezes mais importante. Ou bem próximo disso.
Prefira a homogeneização
O que eu advogo é ir incorporando à base de código novidades da linguagem, especialmente, syntactic sugars, de maneira homogênea, para evitar criar uma colcha de retalhos. Sabe aquela base de código, que se você abrir três arquivos diferentes, parece que foram três pessoas de três lugares remotos do planeta que escreveram? Pois é. Em um arquivo, todas as variáveis são declaradas com anotação de tipo (a.k.a. tipo à esquerda); no outro, todas as variáveis são declaradas com inferência de tipo (var); e no último, há uma mistura dos dois estilos de sintaxe. E você, precisando editar o arquivo fica: e agora, que estilo devo seguir?
Eu sou do tipo que, em geral, segue o padrão do arquivo e mantém o estilo dele, seja este qual for. Exceto quando o dito arquivo não tem padrão nenhum ou não segue as convenções gerais do projeto; aí eu mudo, para enquadrá-lo no estilo majoritário do projeto.
Uma boa abordagem para solucionar este exemplo é ir homogeneizando em favor de var tanto quanto possível. Abriu um arquivo para editar, viu um trecho de código que está fora do “padrão”, refatora, padroniza. Um padrão ruim ainda é melhor do que a ausência de um padrão, porque se no futuro o time decidir mudar o padrão, vai ser muito mais fácil do que se não houvesse padrão algum.
Que tal um outro exemplo? Você precisa implementar uma nova funcionalidade na aplicação e, no processo, se depara com um método que possui uma cadeia de ifs relativamente complexa e tudo mais. Aí, analisando, você vê que o problema não é tão complexo quanto a implementação da solução. Você vê que a implementação poderia ser drasticamente simplificada usando pattern matching, que você andou estudando, mas em nenhum outro lugar da aplicação há uso de pattern matching ainda, muito embora o runtime da aplicação dê suporte a isso. O que você faz? Refatora. Porque vai haver ganho para o negócio. Quero dizer, a próxima pessoa que precisar dar manutenção neste código vai fazer isso de maneira mais confiante e rápida.
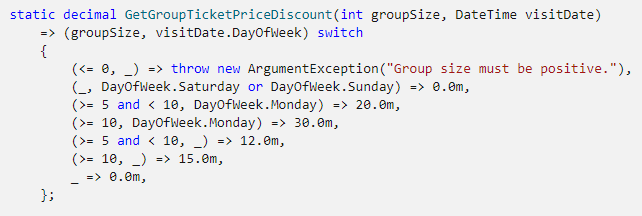
Um último exemplo que gostaria de dar aqui é o caso de interpolação de strings, que é super mundano. C# faz interpolação de strings de maneira elegante desde a versão 6, se não estou enganado, mas ainda é comum ver código por aí que não se beneficia disso, o que é uma pena. Porque além do código ficar mais limpo, quando você faz interpolação de strings, o compilador, gratuitamente, gera para você o código equivalente usando string.Format, que no final das contas, vai usar um StringBuilder. De graça e elegantemente. Quem não quer isso?
As minhas favoritas
Se você acompanhou meu rant até aqui, provavelmente, já teve uma ideia das minhas features favoritas do C# “moderno”, se é que posso chamar assim. Além delas, vou citar mais algumas.
Inferência de tipos
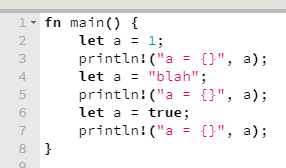
De longe, eu acho que o que eu mais gosto da linguagem C# é a inferência de tipos que ela proporciona o tempo todo (uma salva de palmas para a dupla “linguagem & compilador”), tanto na declaração de variáveis (var / dynamic), quanto na invocação de métodos que possuem type parameters (a.k.a. generics).
Out variables
Eu odiava quando tinha que declarar uma variável antes de usá-la em um método que tem parâmetros out.
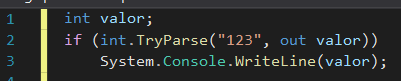
Mas aí, finalmente, no C# 7, alguém teve a brilhante ideia de resolver isso, permitindo que se declarasse variáveis out direto da invocação de métodos com parâmetros out.

Named Tuples, Discarts e Deconstruction
Tuplas estão entre minhas construções favoritas em qualquer linguagem de programação. Meu primeiro contato com elas foi em Scala, depois em Erlang. Para expressar retorno de métodos e aplicar pattern matching, por exemplo, tuplas são extremamente poderosas. Junte a isso a capacidade de fazer desconstrução de objetos e descartar valores que não importam no momento e você tem uma oportunidade fantástica de escrever código limpo e expressivo. C# 7 nos deu isso.

O snippet que apresentei na seção anterior, falando de pattern matching, é outro exemplo prático e elegante do uso de tuplas.
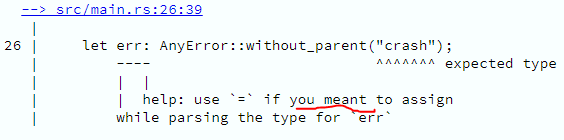
Throw Expressions
Essa feature, também do C# 7, tornou bastante prático, quando é preciso checar se um determinado identificador contém um valor e, se sim, atribuí-lo a um outro identificador; ou senão, lançar uma exceção.

Anteriormente, esse código obrigaria um tipo de if-else.
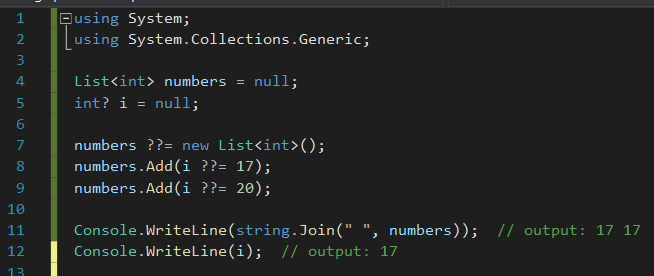
Null-coalescing Assignment
C# 6 havia introduzido Null-conditional Operator (.? e []?) na linguagem com bastante sucesso, eliminando uma série de expressões check-before-access. C# 8, por sua vez, trouxe um novo syntactic sugar para ir um pouco além (?? e ??=), super útil para fazer check-then-assign. Trocando em miúdos e exemplificando com o código abaixo, o que isso significa é que, usando o operador ??=, o valor da direita só será atribuído à variável da esquerda, se esta variável for nula.
Record Types
Para fechar, uma feature mais recente, do C# 9, que eu sinceramente ainda não apliquei em códigos de produção. Diferente das structs, que são value types que todos nós conhecemos de longa data, os records são, na verdade, syntactic sugar para classes que implementam uma série de funcionalidades que favorecem o emprego de “imutabilidade” de dados, como é o caso do operador with, que faz cópia com modificação (a.k.a. Nondestructive Mutation). É isso. Embora, eles também possam ser mutáveis, seu objetivo principal é ser immutable & data-centric types.
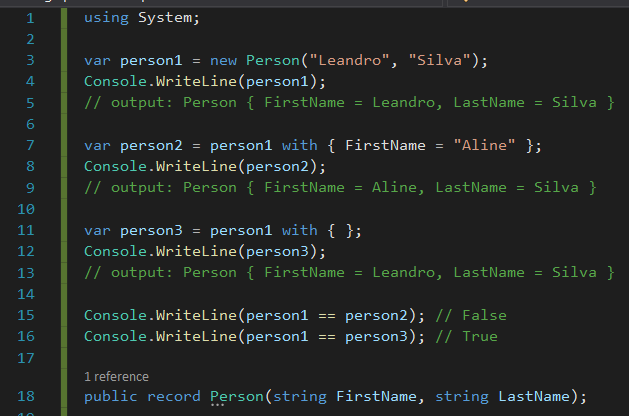

De início, quando comecei a ouvir falar dessa feature, achei que fosse só hype e pensei: já temos struct e class, para que mais um tipo? Mas quando fui me informar melhor, estudar a proposta, enxerguei benefícios práticos.
Essa é, portanto, uma feature que vejo como forte candidata a ser introduzida em bases de código mais datadas. E isso, porque ela diminui a quantidade de código que você tem que escrever para ter certas garantias e comportamentos por vezes desejados (imutabilidade, igualdade de valor, etc). C# 9 faz isso de graça, sem que você tenha que escrever um tanto de código boilerplate, que teria que dar manutenção depois.
Conclusão
C# evoluiu demais nos últimos anos. Especialmente, na última década.
A linguagem tem ficado mais complexa? Tem. Mas não é o tipo de complexidade que você e eu somos obrigados a lidar no nosso dia a dia. É complexidade que os desenvolvedores da linguagem precisam lidar. Você e eu podemos, ou não, usar as novas features que ela oferece; que na maioria dos casos, insisto, só facilitam o nosso trabalho.
Você não precisa guardar toda a sintaxe da linguagem na sua cabeça. Há coisas melhores para ocupar a nossa memória. Apenas lembre-se de sempre checar se não há uma maneira melhor ou mais simples de fazer a tarefa da vez.