No meu post anterior, falei sobre dados e arquiteturas de sistemas, enfatizando a importância de se cuidar dos dados de uma organização desde sua forma mais fundamental, no momento de seu primeiro registro histórico, ainda em estado bruto, de modo a favorecer a evolução e incremento de seu uso nos negócios atuais da organização e do futuro que está além do horizonte, uma vez que dados tendem a ter longevidade maior do que aplicações.
We observed that database systems are characterized by longevity of data. They usually involve a large volume of data that can last for a considerable period of time. Furthermore, the longevity of data and its impact in long term made it a valuable asset that had to be well managed. Given the longevity of data it is difficult to foresee all its possible uses, and hence it is impracticable to define a specific interface that would satisfy all applications developed during its lifetime.
Jack Campin, Daniel Chan, and David Harper, Specifications of Database Systems, page 316.
O ponto chave aqui é que, ao registrar os dados que entram e que nascem em uma organização, deve-se levar em conta não apenas o uso que se faz deles hoje, mas que se poderá fazer no futuro. Muitos produtos e oportunidades de negócios já nasceram a partir de dados que foram coletados e armazenados com uma finalidade, mas que em um outro momento, mostraram-se úteis para muito mais do que se pensou.
Portanto, cuide dos dados de sua organização tão bem quanto possível.
Se não pelas possíveis oportunidades de negócios futuras, pela própria evolução dos sistemas que o sucesso do seu negócio atual deve cobrar, cedo ou tarde.
O nascimento de um sistema
Fazer um startup com um sistema monolítico (a.k.a. monolito) é provavelmente a abordagem mais sensata, com raras exceções. Uma delas seria o caso do mercado de APIs, porque a própria natureza do negócio tende a favorecer certa granularidade.
O problema de se começar um projeto orientado a serviços (a.k.a. microsserviços, no dias atuais) é o investimento inicial que se precisa fazer em análise e design, para se definir contextos, fronteiras, correndo o risco de se incorrer no erro de big design up front, granularidade exagerada dos componentes de sistema e terminar com uma arquitetura mais complexa do que o necessário para suportar o momento atual do negócio. Pior ainda, pode-se terminar com uma arquitetura mais complexa do que se possa manter com a equipe atual. Incidentes à vista!
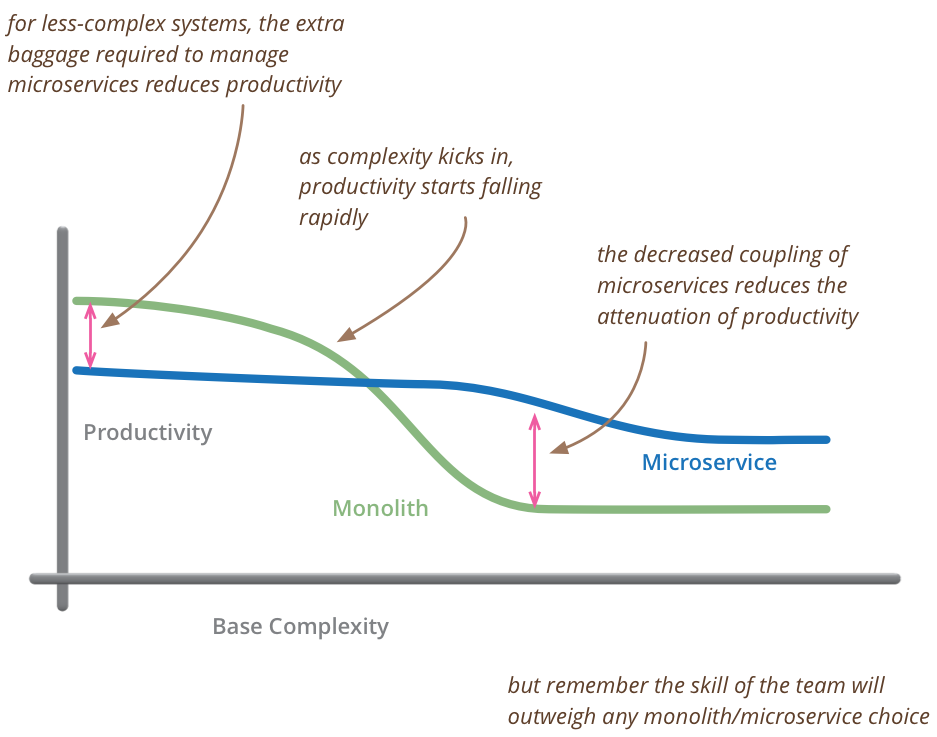
So my primary guideline would be don’t even consider microservices unless you have a system that’s too complex to manage as a monolith. The majority of software systems should be built as a single monolithic application. Do pay attention to good modularity within that monolith, but don’t try to separate it into separate services.
Martin Fowler, Microservice Premium [link]
Especialmente para startups, além de favorecer a simplicidade de design e implementação, começar um projeto como monolito trás a vantagem de abreviar o tempo que se tem entre a ideia e o lançamento do produto; e depois, o aprendizado que se tem ao longo de seu amadurecimento. À medida que o negócio vai escalando, a demanda do sistema vai aumentando, pedindo não somente por disponibilidade, performance, escalabilidade, resiliência, devido ao seu sucesso, mas também por velocidade de implementação de novas funcionalidades para o usuário final, com qualidade e sem afetar o que já existe.
Este aprendizado e experiência com o sistema em produção é fundamental para o amadurecimento do time (não somente como indivíduos, mas como grupo) e o sucesso de uma empreitada de microsserviços.
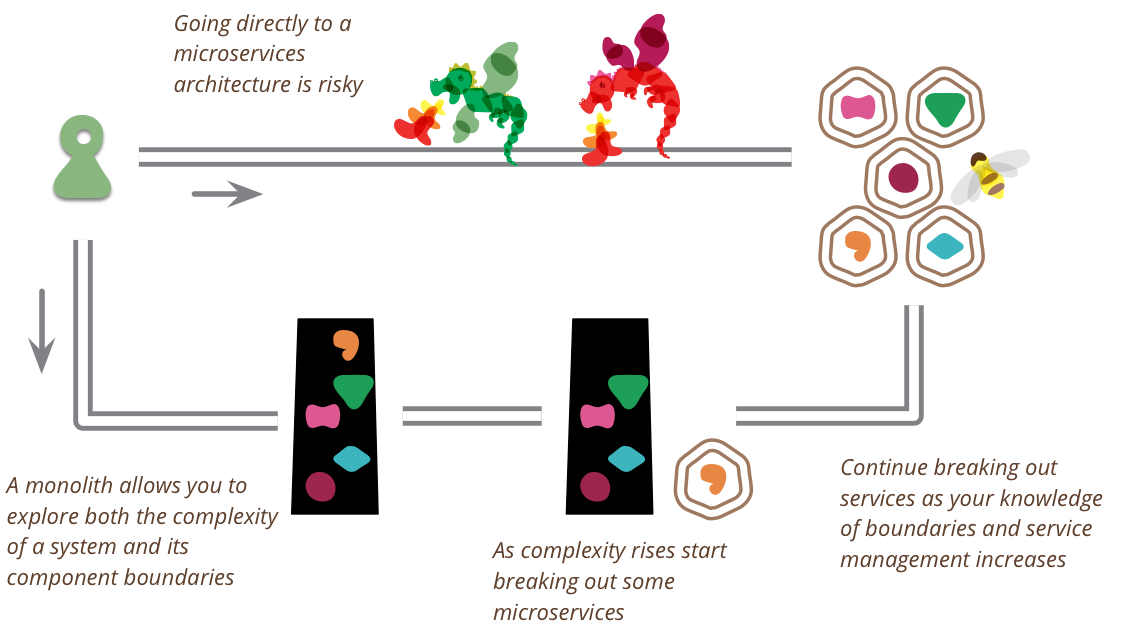
Porque o time que trabalhava junto, com todas as mãos na mesma massa, agora, por força do aumento de demanda do negócio e complexidade do sistema que se formou, vai ter que se dividir para conquistar, se quiser recuperar a produtividade.
Cada pequeno grupo, agora, vai ter que assumir a responsabilidade por uma parte do todo; vai ter que caminhar de forma autônoma, com desafios e objetivos próprios, porém interagindo e contribuindo com os demais grupos por um bem comum ⎼ que em última análise é a missão da organização.
Voltamos então à questão dos dados.
Evolução e escala dependem de dados
Quando os times começam a se dividir e, com isto, dividir também o monolito que os trouxe até o ponto de sucesso onde estão, um dos primeiros problemas com que precisam lidar diz respeito aos dados.
Dentre as principais motivações para se implementar uma arquitetura baseada em microsserviços é que cada time tenha autonomia para evoluir seus microsserviços e implantá-los em produção sem depender rigidamente de outros times. Idealmente, cada microsserviço deve estar fracamente acoplado a outros microsserviços. Isto não é possível no padrão tradicionalmente adotado por monolitos, onde um único banco de dados está no centro da arquitetura, porque qualquer mudança feita no schema deste, para atender a um determinado microsserviço, pode impactar diretamente outros tantos microsserviços.
Acredite em mim quando digo que não é preciso ser muito azarado para causar um problema deste tipo em produção. Anos e anos de integração de aplicações via banco de dados já provaram isso.
Mesmo que mudanças no schema do banco de dados não sejam um problema para sua organização, porque ela tem um processo de governança super rígido e centralizado, que possibilite controlar a menor mudança que seja no banco de dados e supostamente garantir que não ocorra incidentes decorrentes delas, ainda assim, haveria o problema de escalabilidade, disponibilidade e performance.
Afinal de contas, você não vai querer que o uso que um microsserviço faz do banco de dados penalize outros microsserviços. Ou que uma falha no banco de dados afete todos os microsserviços que estão conectados a ele. Isto não seria muito melhor que um monolito. Seria ok para um primeiro passo, mas aconselhável dar o próximo.
Dividir uma instância de banco de dados não é por si só um problema, desde que se selecione os vizinhos com cuidado, para não promover o chamado noisy neighbor effect. Na verdade, pode ser uma estratégia.
É preciso então considerar alternativas, caminhos que progressivamente viabilizem o desacoplamento.
Modelos de arquitetura de sistemas
No post anterior, vimos um modelo de arquitetura de sistemas centrado em um fluxo de dados imutáveis, que são perpetuamente registrados (como fatos históricos) e constantemente propagados para quem possa interessar. Na prática, um log.
Como escrevi lá e repito aqui: log stream é apenas um dos modelos possíveis. Há muitos modelos de arquitetura documentados, que dão conta de dados e integração de sistemas, como 1, 2, 3 e 4, por exemplo. É importante conhecer pelos menos alguns e ter senso crítico na hora da adoção.
Portanto, hoje, quero apresentar um outro modelo, um padrão que pode ser implementado sozinho ou combinado com log stream.
Dados pedem um guardião
Se você já foi exposto a sistemas distribuídos por algum tempo, certamente já se deu conta do quão verdade é a primeira lei da distribuição de objetos.
First Law of Distributed Object Design: Don’t distribute your objects!
Martin Fowler, Patterns of Enterprise Application Architecture [link].
O mesmo vale para dados em sua forma mais primária; especialmente quando podem ser modificados por mais de uma via. Basta permitir que múltiplas aplicações modifiquem a mesma fonte de dados (uma tabela de RDBMS, por exemplo) e o inferno está instaurado na terra. Com direito a limbo e tudo mais. Digo, cache.
Portanto, o princípio fundamental deste modelo apresentado aqui, conhecido como Database per Service, é que um dado deve pertencer a um e somente um microsserviço; e somente ele deve ter poder para modificá-lo.

Neste modelo, todo acesso a uma fonte de dados é rigidamente guardado por um microsserviço, que deve oferecer uma API de acesso aos interessados. Este padrão de isolamento também é conhecido como Application Database.
Obviamente, como você pode imaginar, há vantagens e desvantagens neste modelo. Vamos ver algumas.
Vantagens
– O acesso direto ao banco de dados é feito por uma única via;
– A consistência dos dados é feita em um ponto único;
– Pode-se modificar o schema do banco sem afetar outros microsserviços;
– É possível escolher o banco mais especializado para a estrutura de dados;
– Maior agilidade da ideia à produção.
Desvantagens
– Mais complexo de gerenciar, pois tem mais componentes;
– Transações precisam ser coordenadas entre múltiplos microsserviços;
– Consultas precisam agregar múltiplas origens de dados de microsserviços;
– Modificações nos dados precisam ser notificadas aos interessados;
– Performance de operações simples podem ser impactadas.
Como você pode ver, são ótimas vantagens, é verdade. Mas as desvantagens não são poucas. No entanto, o ponto chave aqui é que a complexidade é inerente ao problema em mãos. Frente à natureza do problema, qualquer solução que se proponha vai ser complexa de implementar e trazerá consigo desafios.
Que tal pensar em como superar os desafios decorrentes?
Possíveis soluções para os problemas apontados
1. Mais difícil de gerenciar
É nesta hora que automação de processos de operação, infraestrutura como código, serverless e práticas de devops vem bem a calhar.
2. Transações precisam ser coordenadas entre múltiplos microsserviços
Este é um dos maiores desafios de uma arquitetura com database per service. Não é um desafio novo, no entanto. Transações distribuídas tem sido um problema há muitos anos. Desde que os dados precisaram ser distribuídos, provavelmente.
Uma maneira de lidar com esse problema é usando o padrão Saga.
A saga is a sequence of local transactions. Each local transaction updates the database and publishes a message or event to trigger the next local transaction in the saga. If a local transaction fails because it violates a business rule then the saga executes a series of compensating transactions that undo the changes that were made by the preceding local transactions.
Chris Richardson, Saga Pattern [link]
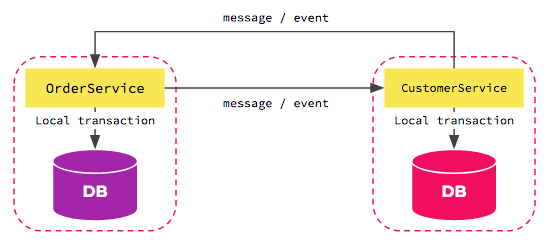
É bom lembrar que, para que isto seja possível, é preciso aceitar a possibilidade de consistência eventual. Temos a tendência de pensar em ACID o tempo todo, mas a verdade é que nem todos os processos de negócio precisam ser assim.
3. Consultas precisam agregar múltiplas origens de dados de microsserviços
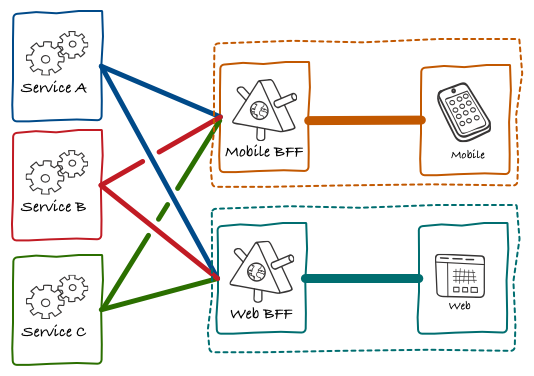
Uma das soluções possíveis para este desafio é usar o padrão conhecido como Back-end for Front-end (BFF), que resolve o problema de agregação de dados, criando uma fachada especializada para cada aplicação cliente.
Este padrão resolve não somente o problema prático de se fazer agregação de dados, para promover uma experiência rica nas aplicações clientes, mas principalmente, dois problemas diretamente derivados dele no contexto de sistemas distribuídos: verbosidade e latência de rede que se tem ao se fazer múltiplas requisições a microsserviços para compor um conjunto de dados para uma aplicação cliente.
Uma outra alternativa bem conhecida é o padrão Command Query Responsibility Segregation (CQRS). A abordagem aqui é criar views read-only, cuidadosamente modeladas (a.k.a. desnormalizadas) para atender ao domínio de negócio local a um microsserviço.
Geralmente, para manter os dados destas views atualizados, se faz uso de eventos, que são publicados pelos microsserviços ao modificarem os dados que guardam ou por mecanismos de change data capture.
4. Modificações nos dados precisam ser notificadas aos interessados
Quando se incorpora os princípios de uma arquitetura orientada a eventos, este problema meio que é a regra do jogo, então não há muito o que dizer a respeito.
O item anterior toca brevemente neste ponto.

Obviamente, não precisa haver uma arquitetura totalmente orientada a eventos para se beneficiar da troca de mensagens, pub/sub & Cia. Basta ter um middleware simples de mensageria e vòila. Sempre que um microsserviço modificar um dado na base, ele publica a novidade em um tópico. Quem tiver interesse no assunto, se inscreve no tópico e faz algo a respeito.
5. Performance de operações simples podem ser impactadas
Sim, fazer um join bem feito entre duas, três, quatro tabelas em um banco de dados relacional, com índices bem construídos, é bem performático na maioria dos casos. É difícil competir com isto. Mas colocando de lado a complexidade de implementação do padrão CQRS, consultas em tabelas desnormalizadas tendem a ser bem mais rápidas.
Tudo a seu tempo
É difícil pensar em uma arquitetura de microsserviços em que o banco de dados seja livremente compartilhado por todos. Especialmente depois de tudo que vimos até aqui. Mas há algumas estratégias para se compartilhar o banco de dados e ainda assim promover algum desacoplamento entre os serviços.
Eu gosto de pensar nestas estratégias como as marchas de um carro, que você vai engatando conforme vai desenvolvendo velocidade. Você até pode pular uma marcha ou outra, mas não adianta sair da primeira direto para a quarta ou quinta. É preciso estar a certa velocidade para tirar proveito de cada uma delas.
Analogamente, eu penso que você pode usar essas estratégias enquanto caminha de um extremo ao outro, de uma arquitetura monolítica para uma com um banco de dados por microsserviço, conforme a velocidade de crescimento da sua organização, modelo de negócios, demanda imposta aos sistemas e habilidades atuais do time.
Mesmo schema, diferentes usuários
Nesta abordagem, cada microsserviço tem seu usuário em um único servidor de banco de dados e compartilha o schema com os demais. Privilégios de leitura e escrita são controlados por usuário.
Evolução dos schemas ainda são um problema e requer um bom trabalho de governança para mantê-lo, bem como os privilégios dos microsserviços. Mas pode ser um caminho para começar a criar uma barreira que delimita quem tem a guarda do que.
Múltiplos schemas, mesmo servidor de banco de dados
Aqui, cada microsserviço tem seu próprio schema, realiza transações em seu próprio schema e participa de sagas. Muito embora não seja o ideal, enquanto o time não tiver condições para implementar Saga, as transações podem ser estendidas aos schemas dos vizinhos.
Nesta abordagem, quando um microsserviço precisa de dados de outro, ele os obtém a partir da API do microsserviço que tem a guarda dos dados desejados. Novamente, embora não seja o ideal, em um primeiro momento, pode-se até fazer um UNION ALL com os schemas dos outros.
É um nível de desacoplamento bem interessante, que pode te levar longe até que a próxima estratégia se faça necessária. Com os microsserviços restritos ao seus próprios schemas, sendo monitorados individualmente, torna-se relativamente fácil migrá-los para instâncias dedicadas, havendo justificativa para isso.
Arrematando
Monolito não é xingamento. É geralmente o melhor começo.
Arquitetura de microsserviços pode estar em voga e todo mundo estar comentando, mas não é fácil de implementar e nem é a solução para todos. Na verdade, ela trás consigo seus próprios desafios. Portanto, deve ser considerada somente quando o estágio do negócio e a demanda que este impõe em seus sistemas de software estejam gritando por isto.
– A organização está em sucesso crescente;
– O time está crescendo para atender a demanda;
– O monolito está super complexo, difícil de manter e evoluir;
– A produtividade está em declínio;
– Boas práticas de automação e devops estão ficando inviáveis;
– Escalabilidade, disponibilidade e performance estão em cheque.
Quando esta hora chegar, lembre-se de seus dados. Ou os incidentes te lembrarão de que você se esqueceu deles.
Idealmente, é bom que cada domínio de dados tenha seu próprio microsserviço guardião e que só ele tenha poder de modificá-los.