Tempo de compilação é uma coisa que me incomoda um pouco quando estou mexendo com Rust, por exemplo. Cada cargo build ou check é uma esperinha chata. Com Go isso não acontece.
Além da simplicidade, a linguagem se propõe a trazer para mesa um tanto de features desejáveis de outras linguagens e mais alguns bônus. Como eles dizem na documentação, V foi criada porque nenhuma das linguagens que os inspiraram tinha “todas” as features que eles buscavam.
Outra coisa que gostei bastante: baterias inclusas. Não tem coisa mais irritante do que ter que ficar instalando um pacote para cada coisa trivial que você precisa fazer.
V traz built-in uma biblioteca multiplataforma de UI nativa, biblioteca gráfica 3D, ORM (que atualmente suporta SQLite, mas há trabalho em curso para MySQL e Postgres; e no futuro também Oracle), frameworks de Web e Teste, etc. O mínimo que você usa no dia a dia.
E finalmente, a interoperabilidade com C. V compila para C; e na versão que está por vir, vai ser capaz de traduzir C para V também. Isso é fantástico por dois motivos: C roda em qualquer lugar; você vai poder dar uma vida nova ao seu código C legado.
Tem mais algumas outras coisas que achei bacana na proposta da linguagem. Algumas delas são coisas que também gosto em Rust, Go, C++, enfim, acho que não vale a pena comentar, para não chover no molhado. O principal é o que falei mesmo.
Do que não gostei?
Honestamente, de nada exatamente. Mas encontrei algumas limitações, que são naturais para o estado de maturidade da linguagem.
Uma das features da linguagem é que o backend dela é C e não LLVM, como já mencionei. Isso é interessante. Mas às vezes, você se depara com alguns erros de compilação que te apontam para o código C. Se você souber C, okay, você está em casa. Mas se você não souber, provavelmente vai ficar mais assustado do que esclarecido.
Para mim, documentação, exemplos de uso e casos de erro vs. solução (a.k.a. StackOverflow) são fundamentais para a adoção de qualquer linguagem ou tecnologia em ambiente produtivo. É preciso ter uma comunidade sólida ao redor de uma linguagem para que sua adoção possa acontecer em ambiente comercial. Do contrário, boa sorte tentando convencer o seu chefe de que Xyz é a melhor solução.
Dito isso, muito embora, eu, particularmente, não ache que V esteja pronta para produção (ao menos, não para o meu contexto atual), já há bastante coisa legal sendo feita em V, desde computação científica até bot de Telegram.
Tem um repositório bacana, que segue aquela ideia de “awesome alguma coisa”, que você pode dar uma olhada, para ver o que já fizeram com V.
E como usuário de software open source, membro da comunidade, este é um ótimo momento para contribuir com o amadurecimento da linguagem, se ela te interessar. (Senão V, que seja outra linguagem ou tecnologia open source qualquer que você se interesse. Contribuir de volta é sempre uma boa.)
O que eu fiz para ajudar? Escrevi um exemplo de interop com C para converter HTML em PDF usando libwkhtmltox e mandei um PR para os mantenedores da linguagem incluírem no repo oficial.
Fonte: Convert HTML to PDF using V and libwkhtmltox (Source)
Talvez contribua mais no futuro, conforme acompanho de perto a evolução e o amadurecimento da linguagem.
Vamos ver.
—
UPDATE: 03-01-2021 – Pull request foi aceito e incorporado à master.
Eu costumo usar Node.js com certa frequência, tanto no trabalho quanto em coisas pessoais. É um script aqui, uma API ali, uma CLI acolá. Em parte porque eu gosto de escrever JavaScript; gosto de linguagens de programação com chaves e ponto-e-vírgula. Mas também porque é super prático, tem lib para tudo que é coisa que você queira fazer e a performance é geralmente entre aceitável e boa. Quero dizer, se você colocar na balança a velocidade de desenvolvimento, as ferramentas disponíveis e o footprintvs. a performance de execução, para muitos casos, Node.js é bom o bastante.
Não é de hoje esse meu “estranho” gosto por JavaScript, {} e ;.
Mas não me entenda mal, Node.js tem certamente seus downsides. O principal deles talvez nem seja técnico, mas sim o que meu amigo Phillip Calçadoapresentou na GOTO 2013, que está relacionado à ausência de boas práticas de design de software ou simplesmente o emprego das menos recomendáveis. Acredito que, em muitos casos, não por desleixo, mas por pura falta de conhecimento mesmo, porque há coisa de 10 anos, quando Node.js veio ao mundo e começamos a usar JavaScript no servidor, o emprego de boas práticas de programação no browser ainda era insignificante. Isso de alguma forma foi parar no servidor.
Conheça as ferramentas do seu ofício
Além de aprender boas práticas de engenharia de software e design de código em diferentes paradigmas de programação (estruturado, oo e funcional, por exemplo), é importante que se aprenda também um pouco mais sobre como funcionam as plataformas em si. Neste caso, Node.js. Com certeza isso fará diferença na hora de implementar aplicações de verdade e operá-las em produção sem [tanta] dor de cabeça.
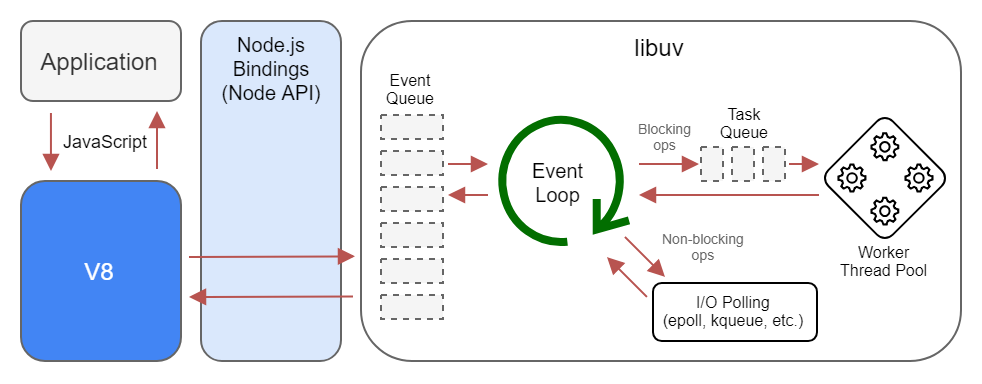
Em se tratando de Node.js, a coisa mais importante a se entender é o seu Event Loop, porque é onde a magia acontece ou a coisa engripa. Se você tem uma base de ciência da computação, vai logo se lembrar que event loop não é um conceito novo que o Node.js inventou. É na verdade um design pattern bem mais antigo. E provavelmente, você vai perceber que há ainda um outro design pattern na jogada, o reactor ⎼ que muitas vezes é tratado como se fosse a mesma coisa, mas não é.
Superada as limitações de conhecimento de programação, da linguagem e da plataforma, chegamos então às verdadeiras limitações da plataforma.
Se você chegou até aqui, provavelmente vai concordar comigo que é uma generalização dizer que Node.js é single-threaded. Mas o fato é que, na prática, para todos os efeitos, isto é verdade. Por isso, deve-se fazer todo possível para não bloquear o event loop, do contrário, a aplicação vai ficar enroscada.
Isto faz com que Node.js não seja um bom candidato para rotinas com processamento pesado, com muitos cálculos e algoritmos complexos, pelo simples fato de que isso leva tempo para executar e bloqueia o event loop, o que no final das contas, acaba limitando o throughput da aplicação.
Temos algumas soluções aqui. Uma delas é escrever essas rotinas em outra linguagem mais poderosa, compilada, com suporte a multithreading, etc e executá-las totalmente apartadas. Outra solução é trazer o poder dessas linguagens para dentro da nossa aplicação Node.js.
Worker Threads parecem interessantes também. Mas tenho zero experiência com elas.
Peça ajuda
C++ Addons tornam possível escrever funções super otimizadas, multi-threaded e tudo mais, que podem ser usadas em Node.js de modo totalmente natural, como se fossem funções comuns do JavaScript.
Addons are dynamically-linked shared objects written in C++. The require() function can load addons as ordinary Node.js modules. Addons provide an interface between JavaScript and C/C++ libraries.
Agora, o fato é que escrever em C++ não é uma tarefa simples. C++ é uma linguagem extraordinariamente poderosa, mas não é fácil de se domar. Quero dizer, programar bem em C++ não é coisa que se aprende em um mês ou dois de vídeos no YouTube.
É agora que recorremos à analogia das facas? C++ é a faca do sushiman, enquanto que JavaScript é a faquinha de rocambole.
Portanto, trata-se de uma otimização com custo alto.
Rust entra no jogo
Rust também não é uma linguagem simples de aprender. Sua curva de aprendizagem é íngreme. Bem íngrime. No entanto, ela é mais segura para quem está aprendendo do que C++, com toda certeza.
Com Rust é possível escrever código com performance compatível com C++, porém com memory safety e fearless concurrency, para usar os jargões da linguagem. O que, neste caso, tornaria o custo de otimização de um programa Node.js que chegou ao seu limite mais acessível.
Será que isto é possível? A resposta é sim. É possível escrever extensões nativas para Node.js em Rust já faz bastante tempo. Mas eu, só há umas duas semanas me dei conta disto e acabei descobrindo uma ferramenta que torna isto muito, muito, fácil mesmo.
O que Neon faz é oferecer um conjunto de ferramentas e bindings para facilitar escrever código em Rust, gerar uma biblioteca nativa e usar em Node.js como se fosse uma função JavaScript qualquer, exatamente como seria com C ou C++.
Diferente de algumas soluções em que se usa apenas FFI para fazer chamadas a bibliotecas nativas, que obviamente poderiam ser escritas em qualquer linguagem, Neon faz bind direto na API da V8, para interagir com JavaScript. O que para eles é um problema, porque quando a API da V8 muda, eles precisam mudar também. Por isso há uma iniciativa de implementar o bind via N-API.
Anatomia de uma extensão Neon
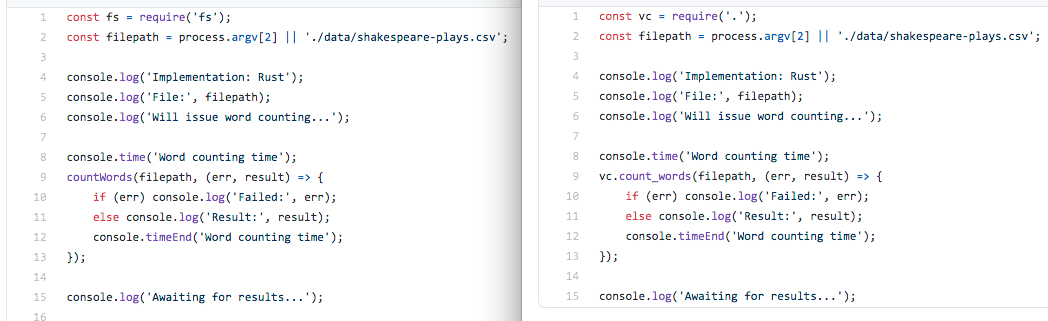
Para ter uma ideia de como é escrever uma extensão em Rust com a ajuda de Neon, fiz um projeto de teste, um contador de palavras básico. O processo foi muito simples e sem enroscos. Fiquei realmente surpreso.
Uma das coisas que me agradou bastante é que a ferramenta cria uma estrutura de projeto padronizada, bem organizada, onde você tem um diretório para a biblioteca Node.js e um para a biblioteca nativa em Rust.
No diretório lib, você tem um arquivo index.js, que é o ponto de entrada da biblioteca, e que faz nada mais nada menos do que importar e exportar a biblioteca nativa em Rust.
Okay. Neste caso, a magia não é tão encantadora assim.
O que acontece, aqui, é que eu exporto uma função que cria um tarefa de contagem de palavras, agenda ela para executar num futuro próximo e passa adiante o callback que recebeu do código JavaScript.
Esta função, depois, é usada no código JavaScript sem que fique aparente que ela é uma função externa, implementada em Rust.
Foi uma experiência bem legal escrever essa extensão e provavelmente devo escrever mais no futuro. Mas a lição mais importante que gostaria de deixar, aqui, neste post, é que você deveria procurar aprender cada vez mais sobre a sua profissão e suas ferramentas de trabalho, tanto as que usa hoje, quanto as que poderá usar amanhã ou depois, antes de qualquer outra coisa.
Em outras palavras, não é porque é possível e relativamente fácil escrever extensões nativas em Rust e usar transparentemente em Node.js, que você vai sair correndo reescrevendo tudo para fazer seu programa voar. Antes de partir para uma abordagem destas é preciso ter certeza de que você empregou o melhor design possível e esgotou todos os recursos “normais” da plataforma. Porque trazer para o jogo uma nova linguagem não é algo gratuito, muito embora pareça ser ⎼ e traz também consigo novos problemas.
Por exemplo, no caso deste contador de palavras, a versão que usa a biblioteca nativa em Rust (que inclusive usa Rayon para paralelismo) performa pior do que a versão em JavaScript puro, quando o arquivo texto não é grande o bastante. Isto porque a mudança de contexto entre JavaScript e Rust tem seu custo.
Há um limiar a partir do qual uma otimização mais hardcore é realmente necessária. Até que se ultrapasse esse limiar, o melhor que se tem a fazer é fazer o melhor com o que se tem nas mãos.
Como disse Donald Knuth: “A otimização prematura é a raiz de todos os males”.
Escrevendo testes integrados para meu projeto Moy Sekret, senti falta de um recurso nativo do Rust para fazer setup & teardown, antes e depois dos casos de teste em si, para checar e limpar alguns efeitos colaterais dele em disco, por se tratar de um programa CLI que lida com criptografia de arquivo.
Sendo Rust uma linguagem compilada para binário nativo, sem um runtime, como Java ou C#, a solução mais óbvia para resolver isto com meta-programação foi criar uma macro.
Macro rules!
Na minha primeira interação para resolver meu problema, então, criei uma macro declarativa simples para injetar um bloco de código before e after imediatamente antes e logo após as funções de testes.
O que a macro setup_run_test faz é criar uma outra macro, a run_test, que é a real responsável por rodar o caso de testes, sanduichado pelos blocos before_test e after_test definidos através da setup_run_test.
Depois, para fazer uso destas macros é bem simples.
Uma vez que a macro tenha sido exportada em sua definição, quando o módulo em que ela foi definida é importado, ela torna-se também disponível para uso no contexto atual.
Programação por convenção
A despeito destas macros terem dado um bom adianto, para eu não ter que escrever do_something(); e do_something_else(); em todos os meus casos de teste (que por enquanto nem são tantos, para ser franco), isto ainda me pareceu muito trabalho ter que fazer setup dos blocos before e after e depois usar a macro run_test! em cada caso de teste.
Por que não seguir uma convenção em vez de fazer uma configuração? You bet!
Macros procedurais
Rust tem um recurso [já não tão novo assim] chamado Procedural Macros, que permite que você manipule um trecho de código fonte (AST) em tempo de compilação e produza um código diferente para ser compilado.
Há três tipos de macros procedurais:
1) Derive macros (#[derive(AwesomeDerive]) – tipo de macro já bem estável, desde a versão 1.15 de Rust, e de uso razoavelmente comum.
2) Function-like macros (pretty_macro!()) – este tipo de macro está estável desde a edição 2018 de Rust. É um tipo muito interessante, parecido com macro_rules!, porém bem mais flexível, já que você tem bastante liberdade em relação aos parâmetros que podem ser aceitos.
Pense em uma função que execute SQL, por exemplo.
Todo este código SQL acaba sendo encapsulado em um TokenStream, que é passado para uma função sql, que finalmente pode parseá-lo e blá, blá, blá.
3) Attribute macros (#[GorgeousAttribute])- este tipo também tornou-se estável em Rust 2018. É muito parecido com as anotações que temos em Java ou C#, porém estritamente em tempo de compilação e permitem fazer transformações no código.
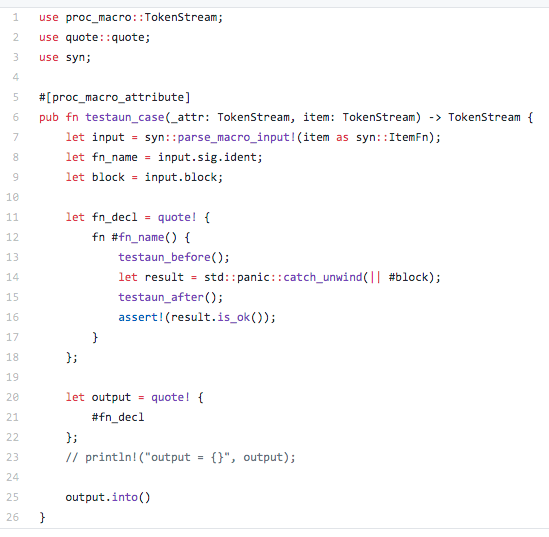
Este foi o tipo de macro que ajudou a resolver minha preguiça de digitar meia dúzia de linhas de código.
Entra o Testaun
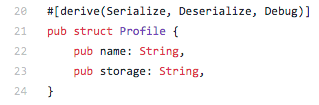
O projeto Testaun é o crate que eu criei para conter macros que me ajudem a reduzir código nos meus testes. Hoje, tudo que ele tem é uma macro. Mas por hora, é tudo que eu preciso.
O que esta macro procedural faz é extrair o bloco de código de uma função de testes e sanduichar ele com chamadas às funções testaun_before e testaun_after. Na prática, o mesmo que a macro run_test! que mostrei anteriormente.
Lembra? Em lugar de fazer o setup de dois blocos para serem executados antes e depois, usamos convention over configuration e esperamos que estas duas funções tenham sido definidas. Caso contrário, pau! O compilador vai chiar.
Okay. E como é que se usa isto depois?
Tendo adicionado este crate ao projeto, basta criar as funções que rodarão antes e depois do caso de teste, anotar a função de teste e é isto.
Como o código acima exemplifica, se um caso de teste não precisa de before & after, basta não anotar com #[testaun_case].
Uma coisa que percebi foi que o crate serial_test (que também manipula AST) e o testaun não se dão bem juntos. Testaun boicota o serial_test. Vou estudar a coexistência deles depois.
Não se reprima. Digo, não se REPITA!
Se você for como eu, um programador preguiçoso, a DRY kinda guy, você pode usar macros para economizar umas linhas de código repetitivo, reduzir boilerplate, padronizar o código do seu projeto e, no final das contas, torná-lo menos suscetível a falhas.
Desde março de 2018, eu vinha vendo uma coisa aqui, outra ali, sobre a linguagem Rust, após ter visto a apresentação do Florian Gilcher na GOTO 2017, intitulada “Why is Rust successful?”, mas nada realmente sério. Me lembro de ter ficado especialmente empolgado com duas talks do Bryan Cantrill, uma na QCon 2018, “Is it Time to Rewrite the Operating System in Rust?”, em junho de 2019, e outra em um meet up, “The Summer of Rust”, alguns dias depois, mas ainda assim, nada de pegar um livro para ler, de rabiscar algum código.
Histórico do YouTube #1 – Primeiro contato com Rust
Na época eu até tinha uma desculpa compreensível: tinha acabado de completar um bacharelado de Nutrição. Sim, isso mesmo. Quatro anos em uma sala de aula há 17km de casa, lendo um tanto de livros, artigos científicos; fazendo trabalhos, estudando para provas, apresentando seminários; estágios de 6 horas diárias em dois hospitais, uma clínica de nutrição esportiva e uma escola de educação infantil; e ainda o fadigante TCC sobre a relação entre nutrição e depressão. Tudo isso enquanto ajudava a construir a Pricefy do zero.
Dá para imaginar que o tema do TCC veio bem a calhar.
Histórico do YouTube #2 – Talks que por um momento me empolgaram
Mas então virou o ano, chegou 2020, a fadiga mental diminuiu significantemente e resolvi gastar algum tempo com Rust, estudar com um pouco mais de dedicação, rabiscar uns programas, experimentar por mim mesmo e não ficar somente no que vejo da experiência dos outros.
Esse post é para registrar um pouco das minhas impressões até aqui.
Rust, a linguagem
Não quero, aqui, dar uma introdução à linguagem, porque já existe uma documentação oficial maravilhosa, muito material educativo disponível gratuitamente, pois isso seria um tanto redundante.
O que é importante se ter em mente, a princípio, é que Rust foi criada com o objetivo de ser uma linguagem de sistema, para ser usada em casos de uso onde normalmente se usaria C/C++, como: drivers, sistemas embarcados, microcontroladores, bancos de dados, sistemas operacionais; programas que vivem extremamente próximos ao hardware, que requerem alta performance, com baixo consumo de memória e overhead de execução próximo de zero.
Portanto, algumas decisões de design foram:
– Ser compilada para binários nativos; – Ter um sistema de tipos estático, forte e extensível; – Não ter coletor de lixo; – Ter um sistema seguro de gestão de memória; – Ser imutável por padrão; – Dar suporte a concorrência imune a data races e race conditions; – Ter checagem de uso de memória em tempo de compilação; – Permitir código “não seguro”, quando explicitamente desejado; – Oferecer tratamento de erro simples, mas robusto; – Ter um ótimo ferramental de desenvolvimento.
Dentre outras coisas. Esta não é uma lista exaustiva. Mas é o suficiente para contextualizar o que vou falar sobre minhas impressões.
Em poucas palavras, eu diria que o objetivo principal era que ela fosse uma linguagem de baixo nível, extremamente performática, porém absolutamente segura e produtiva.
Vamos então à minhas impressões.
O Compilador
Eu fiquei realmente pirado no compilador. Não, é sério. Tendo gastado boa parte dos últimos anos programando em C#, JavaScript, Go e Python, acho que não preciso dizer muito mais.
Mas vamos ver um exemplo:
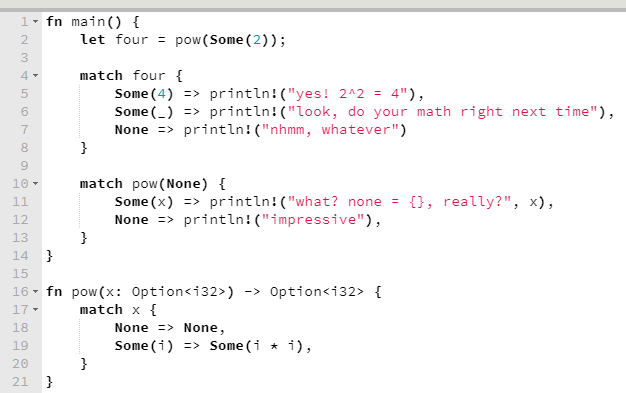
O que nos diria o compilador sobre este programinha?
Hmm? E você, o que me diz?
Ao longo do post vão aparecer mais exemplos legais da atuação do compilador, portanto não vou me prolongar aqui.
Imutável por natureza
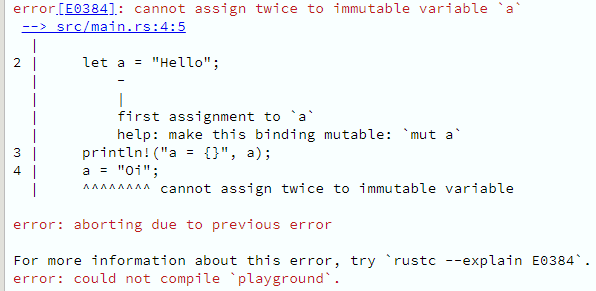
Variáveis são sempre imutáveis, a menos que explicitamente dito que não, como no caso que vimos há pouco.
Isso favorece o desenvolvimento de código concorrente seguro, o que há muito tem sido um dos principais atrativos de linguagens funcionais – ou melhor dizendo, do paradigma funcional de programação.
Não há porque temer o compartilhamento de valores que não mudam; aliás, que não podem ser modificados. Nenhuma linha de execução vai crashear esperando que a seja "Hello", quando na verdade, agora, a é "Oi".
Possessiva, porém generosa
Agora, espere. O que aconteceria se seguíssemos a sugestão do compilador e tornássemos a variável a mutável?
O efeito colateral seria observado. A variável a poderia ter seu valor modificado e os prints refletiriam isso.
Primeiro porque ela teria sido explicitamente anotada como mutável. Justo. E depois, porque a macro println! faz parte de uma família de casos específicos de macros, em que o parâmetro é implicitamente tomado por referência (a.k.a. borrowing), por questão de conforto, praticidade, mas não causam efeitos colaterais neles.
Okay. Isso coloca em cheque o que vimos no tópico anterior, não? Nhmm… não tão depressa.
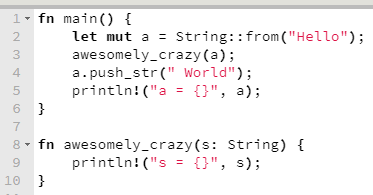
Vamos modificar um pouco o exemplo anterior e ver o que aconteceria em uma função que recebe uma variável não por referência, como é o caso da macro println!, mas por transferência de posse (a.k.a. ownership).
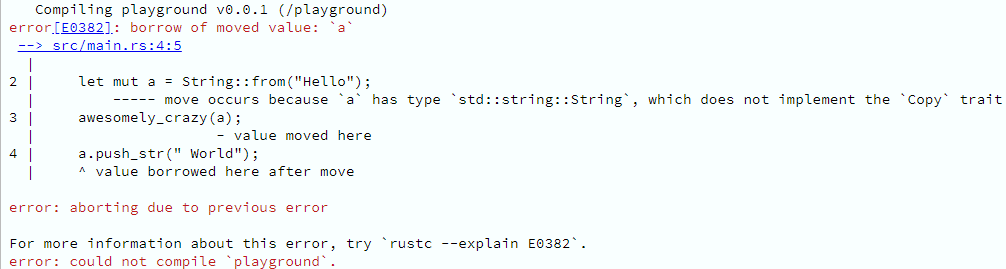
O compilador logo chia, dizendo que se está tentando emprestar o valor supostamente possuído pela variável a, para poder modificá-lo, enquanto este, na verdade, teve sua posse transferida para a função awesomely_crazy. Ou seja, o que quer que awesomely_crazy faça com o que recebeu, a variável a não tem mais nada a ver com isso.
O que acontece é que, em Rust, como você já deve ter percebido, um valor só pode ser possuído por uma única variável por vez; e quando o escopo em que esta está contida termina, seu valor é destruído. No entanto, essa posse pode ser cedida a outro.
Quem garante essa coisa de ownership, borrowing e lifetime em tempo de compilação é o chamado borrow checker, que muitas vezes se recusa a compilar um programa que você tem “certeza” que está tudo certo.
No nosso caso, somente a variável a era dona do valor "Hello" até ter transferido sua posse para a função awesomely_crazy. A partir de então, a função awesomely_crazy (nominalmente o parâmetro s) é quem passou a ser sua única proprietária; e ao final de sua execução, ao término de seu escopo, esse valor será destruído. É por isso que ele não pode ser emprestado novamente para modificação, através de a.push_str, ou mesmo emprestada para println!, que sequer modifica alguma coisa.
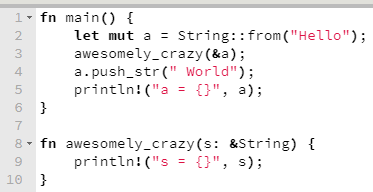
Portanto, se quisessemos fazer esse código compilar, teríamos que modificar a implementação da função awesomely_crazy, de modo que ela passasse a tomar o valor da variável a emprestado, por referência (& – C/C++ feelings, anybody else?), e não por posse.
Não haveria qualquer problema.
Mas note que awesomely_crazy toma o valor de a emprestado, por referência, mas não pode modificá-lo, como é o caso em outras linguagens. Se quiséssemos permitir que awesomely_crazy modifique o valor possuído pela variável a, teríamos que fazer um desencorajador malabarismo de mut, que provavelmente nos faria pensar um pouco mais no algoritmo que estamos tentando escrever.
Eu sei que tudo isso pode parecer complicado (e na prática é mesmo; tente implementar uma estrutura de dados recursiva, por exemplo), mas essas características da linguagem:
– Imutabilidade por padrão; – Mutabilidade por decisão explícita; – Posse exclusiva de valor; – Empréstimo de valor com restrições.
Com regras rigidamente observadas pelo compilador, são super interessantes na hora de escrever programas que rodam continuamente, por tempo indeterminado, sem crashear depois de devorar toda a memória disponível, por causa leaks; ou então, programas com processos concorrentes, que não crasheiam por conta de data races e race conditions.
Essa é a maneira de Rust possibilitar um runtime de alta performace, seguro para processos concorrentes, que não correm o risco de lidar com dangling pointers, data races, e ainda livres do overhead de um coletor de lixo para garantir isso.
Confesso que volta e meia ainda passo perrengue com isso e tenho que repensar meu código, mas isso tem acontecido cada vez menos e tenho gostado cada vez mais. O que realmente me deixa puto são certos casos de inferências, que penso pqp, como é que ele não consegue saber em tempo de compilação o quanto essa p@%$# vai consumir de memória.
Anyway. De qualquer forma, não existe null pointer em Rust e isso por si só já me deixa feliz.
Sintaxe, bizarra sintaxe
Olha quem está falando: alguém que gastou um tanto de horas de sua vida programando em Erlang. Okay. Não tenho muito o que reclamar.
Mas a real é que esse título é mais clickbait do que verídico.
A verdade é que eu gosto da sintaxe de Rust. Sempre fui fã de linguagens com sintaxe C-like, tipo: Java, JavaScript, C#, Scala, Go, e outras. Mas em todas essas linguagens sempre tem alguma coisa que acho chata, irritante ou bizarra. Às vezes as três.
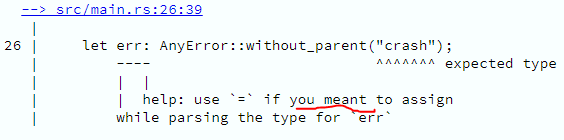
No caso de Rust, o que acho bizarro é a anotação de escopo para ajudar na validação de tempo de vida de referências à memória. Como vimos anteriormente, não há coletor de lixo, então toda referência tem um tempo de vida baseado no escopo em que esta está contida. Terminado o escopo, essa referência é destruída e sua memória liberada. A maior parte do tempo, o compilador consegue inferir isso sem ajuda, mas às vezes, você precisa dar uma mãozinha, usando o chamado generic lifetime parameter, para garantir que em tempo de execução as dadas referências serão de fato válidas.
Side note – Olha o compilador aí, dando aquela ajuda Google-like
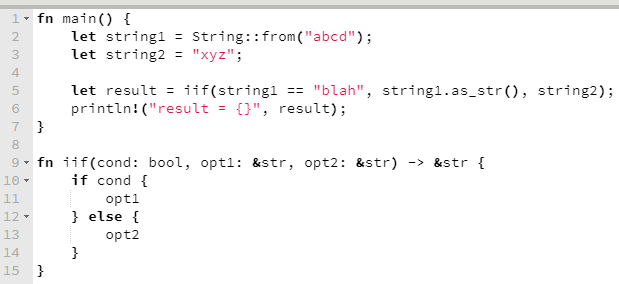
O código abaixo implementa um if-ternário sem sucesso, porque há uma ambiguidade sobre que referência será retornada.
O compilador, naturalmente, não gosta disso, diz o motivo e sugere uma solução.
Implementada a solução sugerida; ou seja, anotado o escopo de vida do que a função recebe e do que retorna, para que a ambiguidade seja eliminada.
Vòila! O código compila e, a menos que tenha um erro de lógica, roda perfeitamente como esperado.
Tudo bem. Foi só uma anotaçãozinha. Mas isso porque também foi só uma funçãozinha. Imagine algo com escopo de vida um pouco mais completo, que precise de mais de uma anotação de lifetime e ainda outras anotações de tipos genéricos.
É, a coisa pode escalar bem rápido. Generics é um recurso fantástico, sem sombra de dúvidas, mas imagine isso na assinatura de uma função, que também tem outros parâmetros, e retorno, e… Pff!
Mas por outro lado, o lado bom, agora, é que há um recurso robusto de definição de tipos. Em lugar de escrever algo assim:
Você pode definir um tipo que defina essa especificação gigantesca, fazendo bom uso de generics e tudo mais; e inclusive, dar um nome para o que ela representa. Só espero que você seja melhor do que eu com nomes.
Vê? Com isso é possível tornar o código bem mais semântico, comunicar mais significado, porque no final das contas, você passa mais tempo lendo código do que escrevendo ou apagando código.
Side note – Outra vez, o compilador amigão
Pattern Matching e tratamento de erros
Quem me conhece e já trocou ideias de programação comigo, sabe que sou bem fã de pattern matching. Essa é uma das coisas que mais gosto em Erlang e é também uma das que mais gosto em Rust.
Lindo, não? Okay. Eu sei que estou exagerando um pouco.
Mas a questão é que este recurso, além de favorecer que se escreva código mais declarativo e com viés mais funcional, também encoraja o tratamento de erros mais simples, menos complicado.
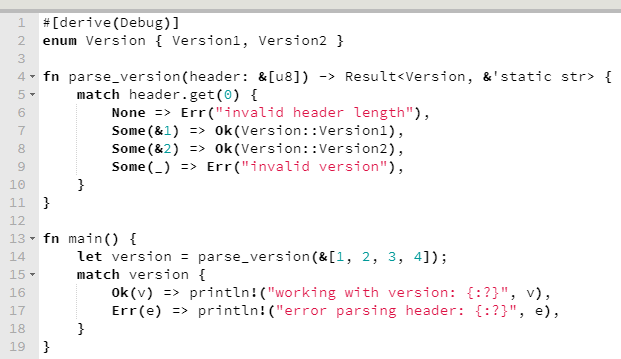
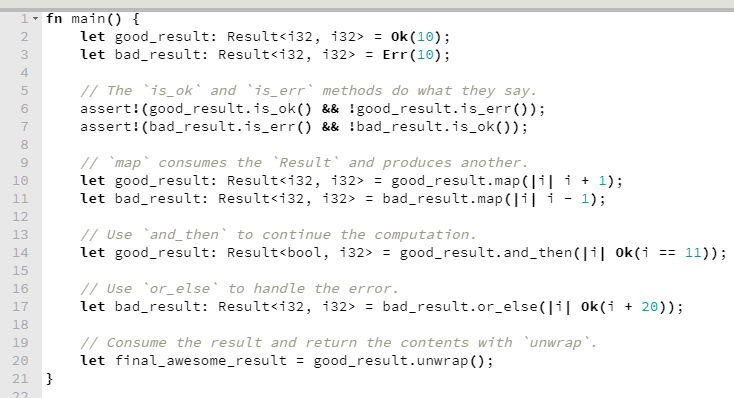
Em Rust, a forma idiomática de tratamento de erros é que o retorno de uma função seja uma enumResult, que pode conter o resultado do sucesso ou o famigerado erro.
Este é um exemplo que peguei da própria documentação da enumResult. Ele dispensa explicação, tão simples e declarativo que é.
Uma coisa interessante para se mencionar aqui, que tem tudo a ver com pattern matching e tratamento de erros, é que enums em Rust estão muito próximas do que em linguagens funcionais chamamos de tipos algébricos, o que favorece muito a expressividade do código.
Okay. Mas voltando à Result e ao tratamento de erros, expandindo um pouco no exemplo acima, retirado da própria documentação, perceba que há uma série de funções bacanas, incluindo map e or_else.
De novo, essa é a maneira idiomática de se lidar com erros em Rust. Sim, existe uma macro panic!, muito parecida com o que há em Go, mas use com moderação.
Aliás, falando em Go, eu tenho que dizer que gosto bastante de Go e prova disso é que desde 2012 tenho estudado e feito Go aqui e ali, quando faz sentido. Dito isso, eu acho a forma idiomática de tratamento de erros super simples e compreensível, porém tosca e pobre. Nada sofisticada. Mas tudo bem, este não é o ponto da linguagem.
Recursos funcionais
Rust não é uma linguagem funcional. Rust não foi desenvolvida para ser uma linguagem funcional. Mas tendo sido significantemente influenciada por programação funcional, Rust oferece muitas ferramentas para que programadores experientes em programação funcional escrevam código com conformação funcional.
São todos recursos disponíveis na linguagem, que possibilitam escrever código expressivo, com estilo funcional; e com um detalhe importante: em geral, uma das reclamações que se faz de linguagens funcionais (e não quero aqui discutir isso) é a questão de se preterir performance de execução em função do rigor conceitual do código, mas este não é o caso de Rust, que tem massiva influência da filosofia C++ de custo zero de abstração.
Tudo ao mesmo tempo agora
Concorrência em Rust, na minha visão, não é tão natural como é em Erlang ou Go, mas isso é ok. Por outro lado, Rust oferece mais de uma ferramenta para se implementar concorrência:
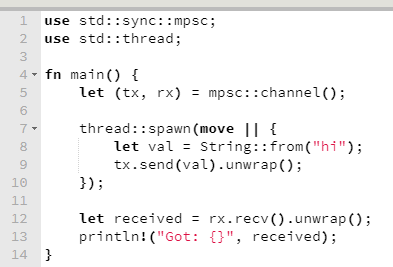
Este é um exemplo simples de message passing que peguei emprestado de Klabnik & Nichols. Bem semelhante ao que se tem em Go, por exemplo, porém um tanto mais verboso.
Aliás, um parênteses aqui: às vezes acho Rust um pouco verbosa de mais. Fecha parênteses.
Este modelo de troca de mensagens é um que me agrada bastante e que estou bem familiarizado. Em muitas situações tendo a pensar primeiro neste modelo antes de considerar outro, porque ele favorece o desacoplamento.
Sinceramente, não gosto muito deste modelo. Mas programação não é sempre sobre o que se gosta, mas sobre o que se precisa fazer para ir da maneira mais segura e eficiente possível do ponto A ao ponto B. Então, quando é necessário usar o bom e velho lock, cá está ele à disposição. Implementação de estruturas de dados thread safe, semáforos de acesso a recursos, são exemplos de uso.
Já este exemplo abaixo é de concorrência com futures, usando a relativamente nova implementação de async/await, que também segue a filosofia de abstração com custo zero. Acho que este modelo dispensa qualquer introdução, por ter se popularizado tanto nos últimos anos, desde que foi implementado em F# e C# e mais recentemente em JavaScript.
Pensando bem, nos últimos anos, escrevendo um monte de C# e Node.js quase diariamente (e ocasionalmente algum Python com Async IO/ASGI nos finais de semana) este é o modelo que mais uso. É simples de ler código com async/await, fácil de entender, de explicar, não tem tempo ruim.
É bom ter mais de uma ferramenta à disposição e ser capaz de implementar mais de um modelo de concorrência, para então escolher o que melhor atende à tarefa em questão; e isso não é exclusivo, um ou outro. Em um sistema, pode haver uma combinação desses modelos que vimos. Aliás, esse é o mais provável.
A propósito, se você ainda se confunde um pouco com concorrência vs paralelismo, recomendo 2 minutos de leitura aqui.
Bem, apesar da minha reclamação sobre a verbosidade do message passing de Rust, no final do dia, a conta ainda fica positiva.
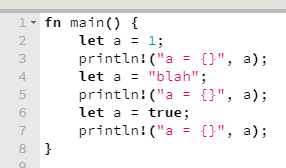
Odeio redefinição de variável
Uma coisa que odeio com todas as minhas forças é shadowing de variável.
Pqp, que p%#*@ é essa?!?!?!
Tá. Eu sei que shadowing não é o puro mal encarnado, tem lá sua razão de ser, blá, blá, blá…
I’m done.
Conclusão
Não existe bala de prata e isso você já deveria saber. Também não existe a linguagem perfeita e própria para todas as situações. O que existe são ferramentas em uma caixa; e o que se espera de você é que você saiba escolher a ferramenta certa, para o trabalho certo, na hora certa.
Eu tenho gostado bastante de Rust até então. Tenho tropeçado em alguns pontos aqui e ali, odiado uma coisa ou outra, mas no geral, estou muito satisfeito.